 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Prompt Alchemist: Automated LLM-Tailored Prompt Optimization for Test Case Generation
Jan 02, 2025



Test cases are essential for validating the reliability and quality of software applications. Recent studies have demonstrated the capability of Large Language Models (LLMs) to generate useful test cases for given source code. However, the existing work primarily relies on human-written plain prompts, which often leads to suboptimal results since the performance of LLMs can be highly influenced by the prompts. Moreover, these approaches use the same prompt for all LLMs, overlooking the fact that different LLMs might be best suited to different prompts. Given the wide variety of possible prompt formulations, automatically discovering the optimal prompt for each LLM presents a significant challenge. Although there are methods on automated prompt optimization in the natural language processing field, they are hard to produce effective prompts for the test case generation task. First, the methods iteratively optimize prompts by simply combining and mutating existing ones without proper guidance, resulting in prompts that lack diversity and tend to repeat the same errors in the generated test cases. Second, the prompts are generally lack of domain contextual knowledge, limiting LLMs' performance in the task.
Search-Based LLMs for Code Optimization
Aug 22, 2024



The code written by developers usually suffers from efficiency problems and contain various performance bugs. These inefficiencies necessitate the research of automated refactoring methods for code optimization. Early research in code optimization employs rule-based methods and focuses on specific inefficiency issues, which are labor-intensive and suffer from the low coverage issue. Recent work regards the task as a sequence generation problem, and resorts to deep learning (DL) techniques such as large language models (LLMs). These methods typically prompt LLMs to directly generate optimized code. Although these methods show state-of-the-art performance, such one-step generation paradigm is hard to achieve an optimal solution. First, complex optimization methods such as combinatorial ones are hard to be captured by LLMs. Second, the one-step generation paradigm poses challenge in precisely infusing the knowledge required for effective code optimization within LLMs, resulting in under-optimized code.To address these problems, we propose to model this task from the search perspective, and propose a search-based LLMs framework named SBLLM that enables iterative refinement and discovery of improved optimization methods. SBLLM synergistically integrate LLMs with evolutionary search and consists of three key components: 1) an execution-based representative sample selection part that evaluates the fitness of each existing optimized code and prioritizes promising ones to pilot the generation of improved code; 2) an adaptive optimization pattern retrieval part that infuses targeted optimization patterns into the model for guiding LLMs towards rectifying and progressively enhancing their optimization methods; and 3) a genetic operator-inspired chain-of-thought prompting part that aids LLMs in combining different optimization methods and generating improved optimization methods.
Label-Aware Distribution Calibration for Long-tailed Classification
Nov 09, 2021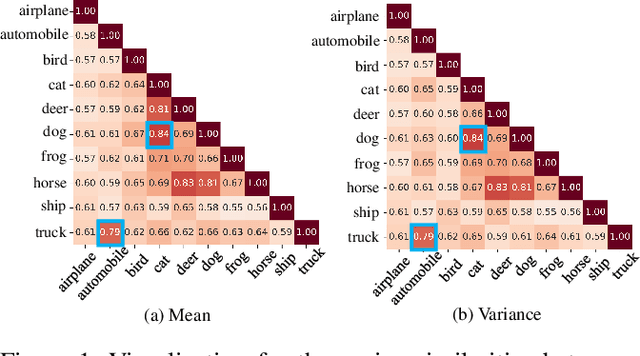

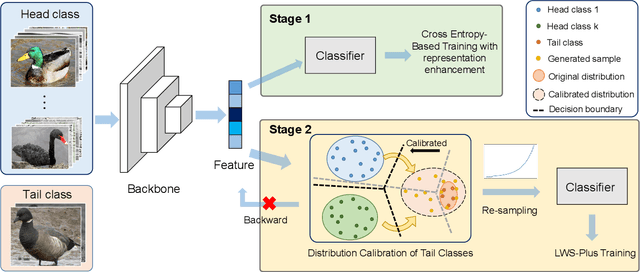
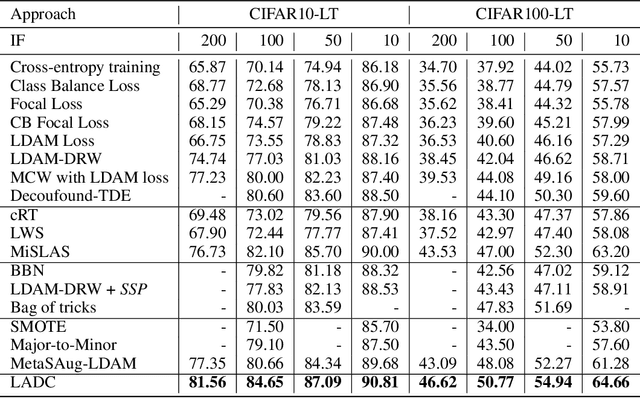
Real-world data usually present long-tailed distributions. Training on imbalanced data tends to render neural networks perform well on head classes while much worse on tail classes. The severe sparseness of training instances for the tail classes is the main challenge, which results in biased distribution estimation during training. Plenty of efforts have been devoted to ameliorating the challenge, including data re-sampling and synthesizing new training instances for tail classes. However, no prior research has exploited the transferable knowledge from head classes to tail classes for calibrating the distribution of tail classes. In this paper, we suppose that tail classes can be enriched by similar head classes and propose a novel distribution calibration approach named as label-Aware Distribution Calibration LADC. LADC transfers the statistics from relevant head classes to infer the distribution of tail classes. Sampling from calibrated distribution further facilitates re-balancing the classifier. Experiments on both image and text long-tailed datasets demonstrate that LADC significantly outperforms existing methods.The visualization also shows that LADC provides a more accurate distribution estimation.
Code Structure Guided Transformer for Source Code Summarization
Apr 19, 2021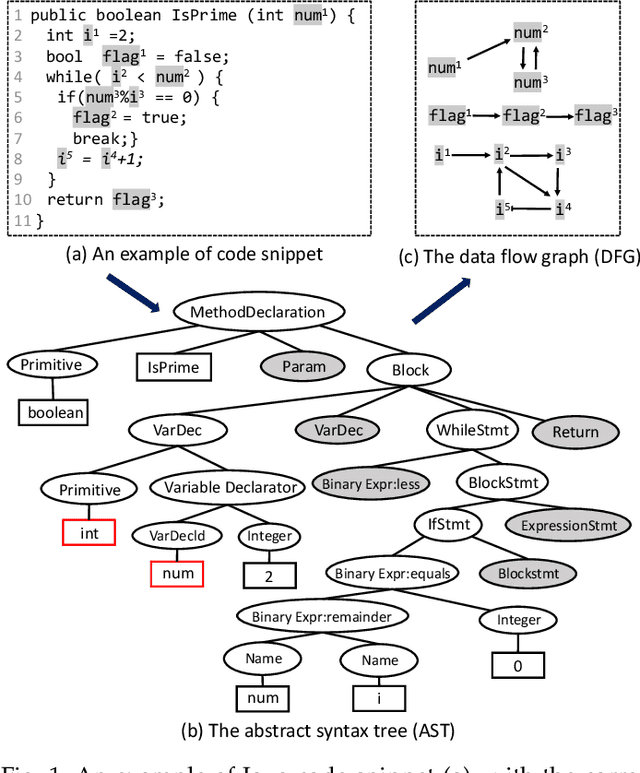
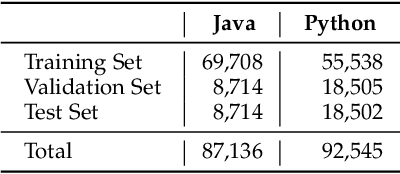
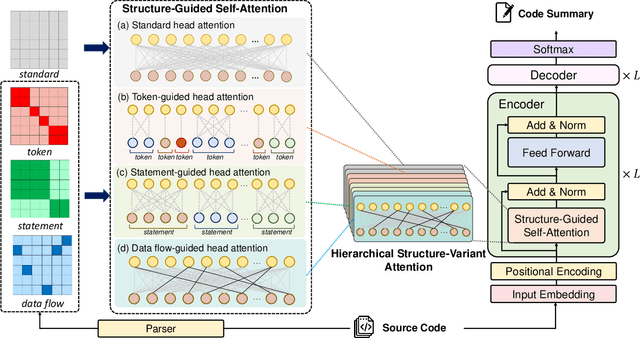
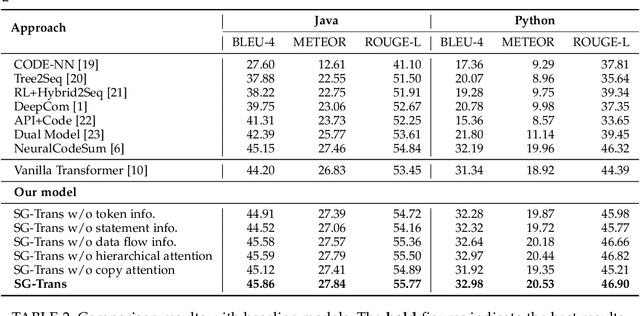
Source code summarization aims at generating concise descriptions of given programs' functionalities. While Transformer-based approaches achieve promising performance, they do not explicitly incorporate the code structure information which is important for capturing code semantics. Besides, without explicit constraints, multi-head attentions in Transformer may suffer from attention collapse, leading to poor code representations for summarization. Effectively integrating the code structure information into Transformer is under-explored in this task domain. In this paper, we propose a novel approach named SG-Trans to incorporate code structural properties into Transformer. Specifically, to capture the hierarchical characteristics of code, we inject the local symbolic information (e.g., code tokens) and global syntactic structure (e.g., data flow) into the self-attention module as inductive bias. Extensive evaluation shows the superior performance of SG-Trans over the state-of-the-art approaches.