 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialog State Tracking: A Neural Reading Comprehension Approach
Aug 15, 2019
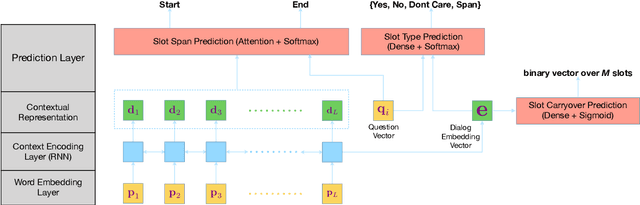
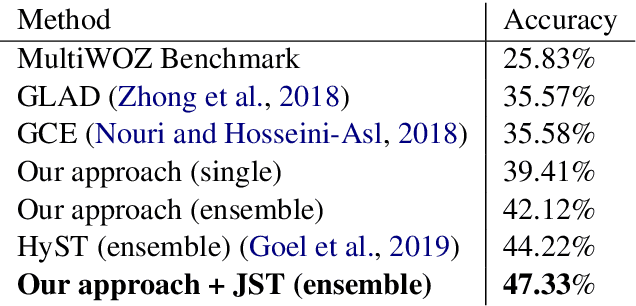
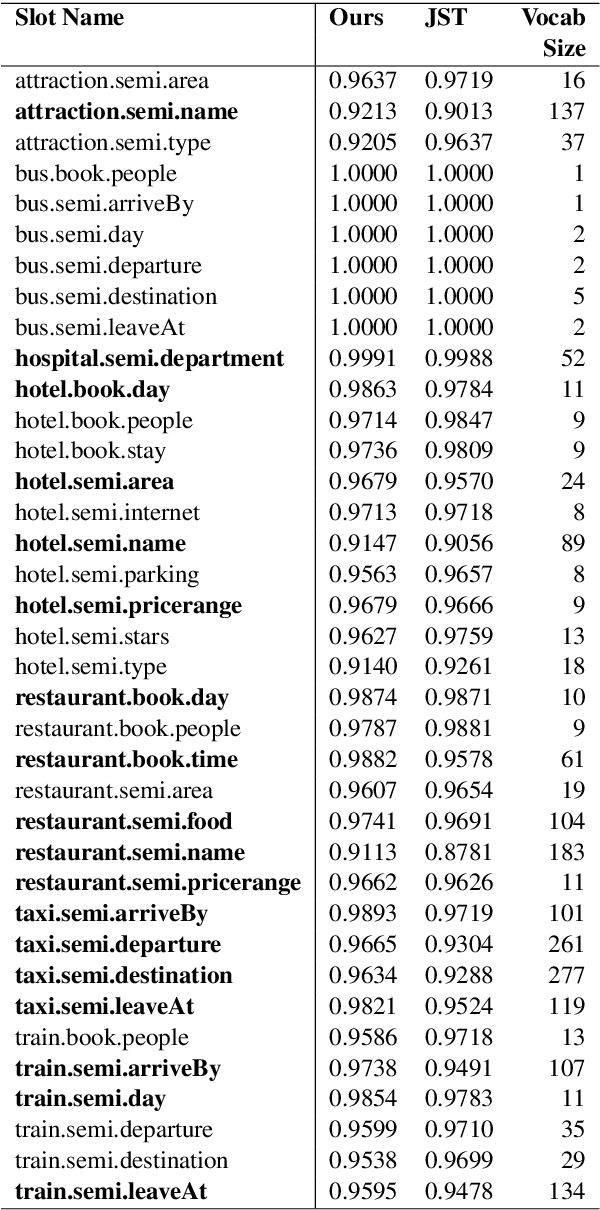
Dialog state tracking is used to estimate the current belief state of a dialog given all the preceding conversation. Machine reading comprehension, on the other hand, focuses on building systems that read passages of text and answer questions that require some understanding of passages. We formulate dialog state tracking as a reading comprehension task to answer the question $what\ is\ the\ state\ of\ the\ current\ dialog?$ after reading conversational context. In contrast to traditional state tracking methods where the dialog state is often predicted as a distribution over a closed set of all the possible slot values within an ontology, our method uses a simple attention-based neural network to point to the slot values within the conversation. Experiments on MultiWOZ-2.0 cross-domain dialog dataset show that our simple system can obtain similar accuracies compared to the previous more complex methods. By exploiting recent advances in contextual word embeddings, adding a model that explicitly tracks whether a slot value should be carried over to the next turn, and combining our method with a traditional joint state tracking method that relies on closed set vocabulary, we can obtain a joint-goal accuracy of $47.33\%$ on the standard test split, exceeding current state-of-the-art by $11.75\%$**.
Invariant Representations without Adversarial Training
Nov 04, 2018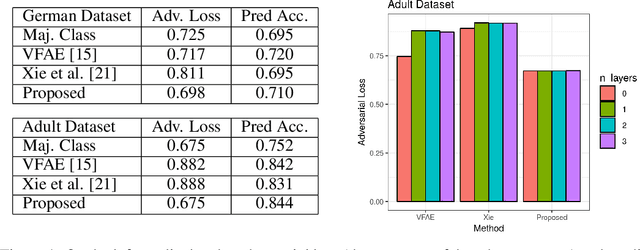
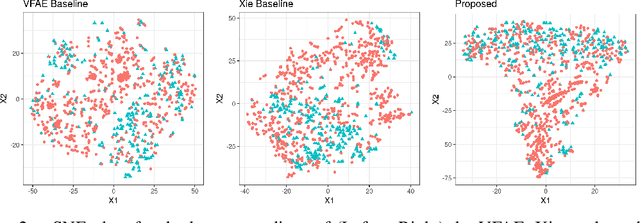
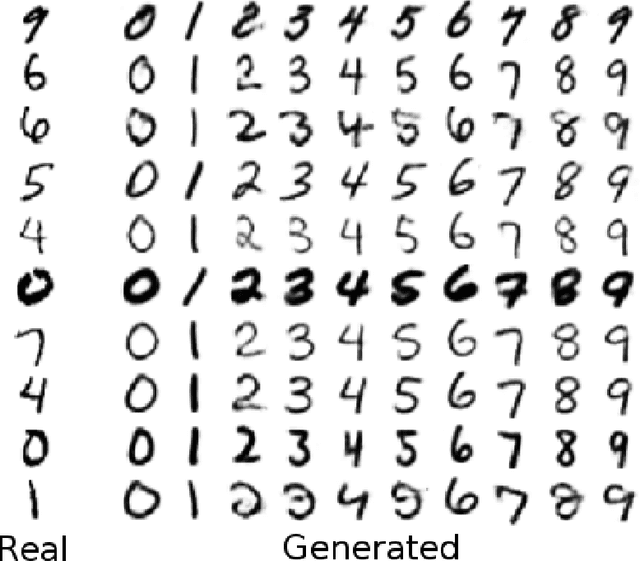
Representations of data that are invariant to changes in specified factors are useful for a wide range of problems: removing potential biases in prediction problems, controlling the effects of covariates, and disentangling meaningful factors of variation. Unfortunately, learning representations that exhibit invariance to arbitrary nuisance factors yet remain useful for other tasks is challenging. Existing approaches cast the trade-off between task performance and invariance in an adversarial way, using an iterative minimax optimization. We show that adversarial training is unnecessary and sometimes counter-productive; we instead cast invariant representation learning as a single information-theoretic objective that can be directly optimized. We demonstrate that this approach matches or exceeds performance of state-of-the-art adversarial approaches for learning fair representations and for generative modeling with controllable transformations.
Kernelized Hashcode Representations for Biomedical Relation Extraction
Oct 31, 2018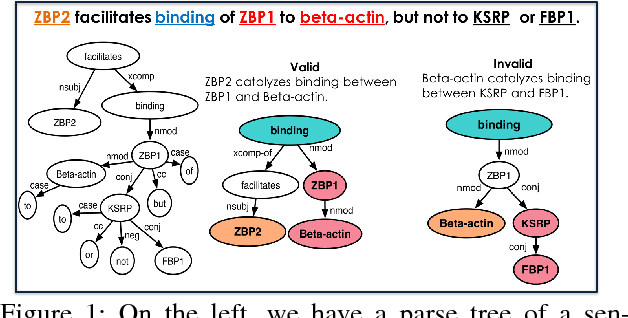
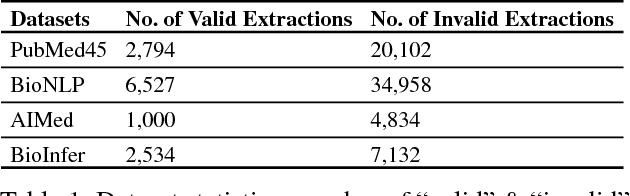
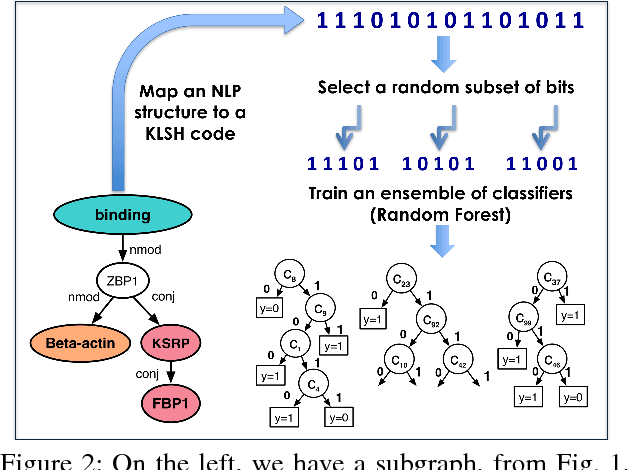
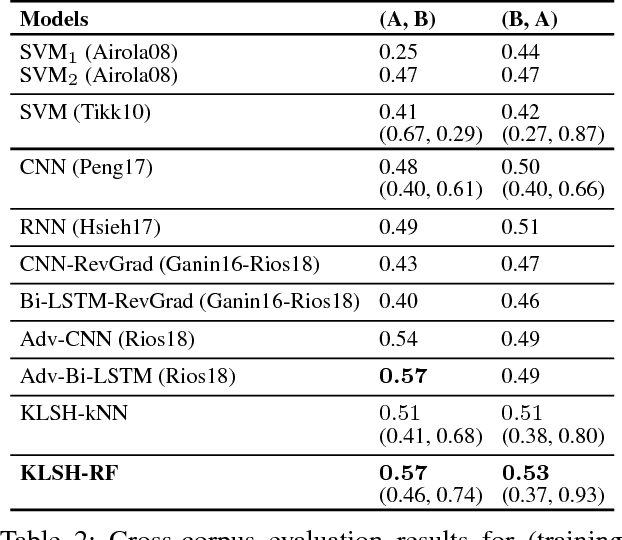
Kernel methods have produced state-of-the-art results for a number of NLP tasks such as relation extraction, but suffer from poor scalability due to the high cost of computing kernel similarities between discrete natural language structures. A recently proposed technique, kernelized locality-sensitive hashing (KLSH), can significantly reduce the computational cost, but is only applicable to classifiers operating on kNN graphs. Here we propose to use random subspaces of KLSH codes for efficiently constructing an explicit representation of NLP structures suitable for general classification methods. Further, we propose an approach for optimizing the KLSH model for classification problems by maximizing a variational lower bound on mutual information between the KLSH codes (feature vectors) and the class labels. We evaluate the proposed approach on biomedical relation extraction datasets, and observe significant and robust improvements in accuracy w.r.t. state-of-the-art classifiers, along with drastic (orders-of-magnitude) speedup compared to conventional kernel methods.
Dialogue Modeling Via Hash Functions
Oct 18, 2018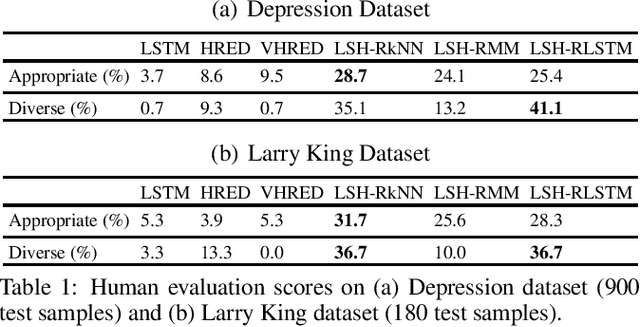
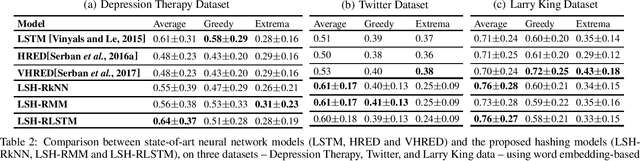
We propose a novel dialogue modeling framework which uses binary hashcodes as compressed text representations, allowing for efficient similarity search, and a novel lower bound on mutual information between the hashcodes of the two dialog agents, which serves as a model selection criterion for optimizing those representations towards better alignment between the dialog participants and higher predictability of one response from another, facilitating better dialog generation. Empirical evaluation on several datasets, from depression therapy sessions to Larry King TV show interviews and Twitter data, demonstrate that our hashing-based approach is competitive with state-of-art neural network based dialogue generation systems, often significantly outperforming them in terms of response quality and computational efficiency, especially on relatively small datasets.
Auto-Encoding Total Correlation Explanation
Feb 16, 2018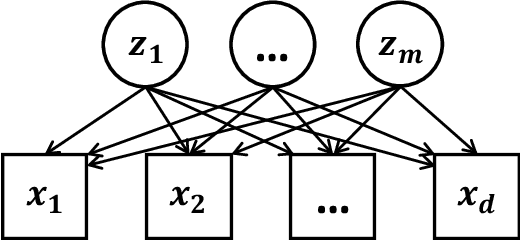
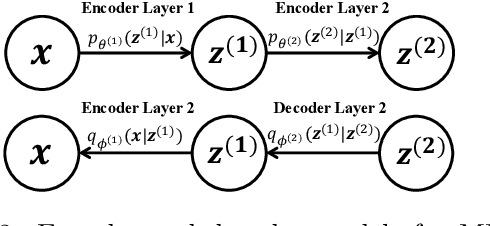

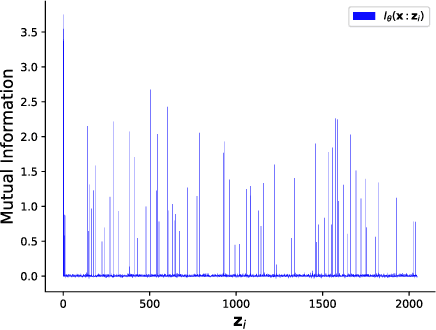
Advances in unsupervised learning enable reconstruction and generation of samples from complex distributions, but this success is marred by the inscrutability of the representations learned. We propose an information-theoretic approach to characterizing disentanglement and dependence in representation learning using multivariate mutual information, also called total correlation. The principle of total Cor-relation Ex-planation (CorEx) has motivated successful unsupervised learning applications across a variety of domains, but under some restrictive assumptions. Here we relax those restrictions by introducing a flexible variational lower bound to CorEx. Surprisingly, we find that this lower bound is equivalent to the one in variational autoencoders (VAE) under certain conditions. This information-theoretic view of VAE deepens our understanding of hierarchical VAE and motivates a new algorithm, AnchorVAE, that makes latent codes more interpretable through information maximization and enables generation of richer and more realistic samples.
Sifting Common Information from Many Variables
Jun 16, 2017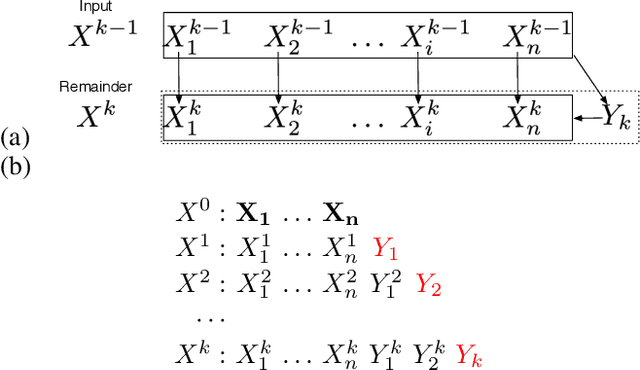
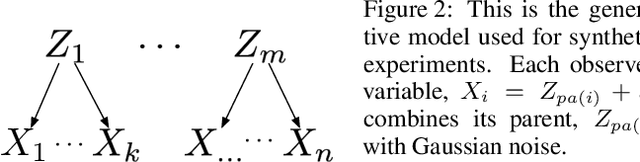
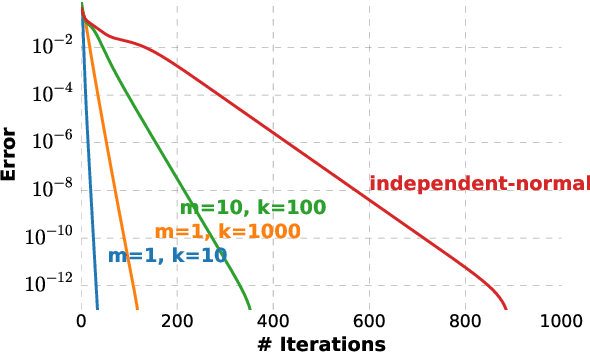
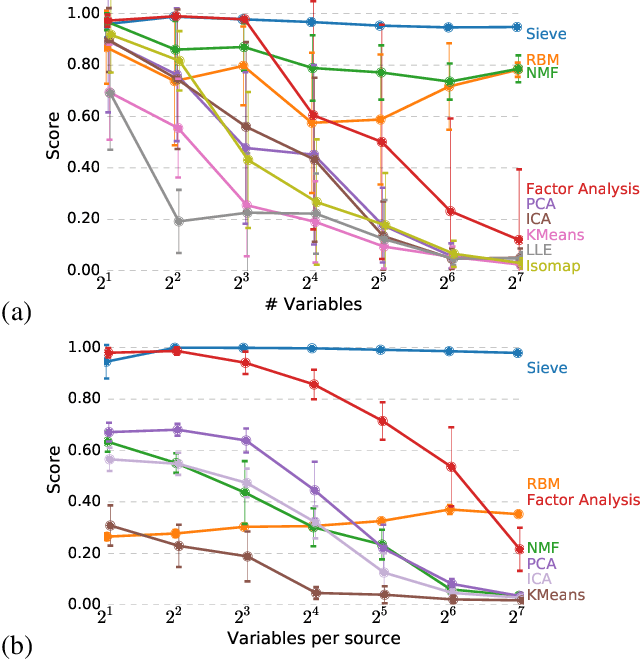
Measuring the relationship between any pair of variables is a rich and active area of research that is central to scientific practice. In contrast, characterizing the common information among any group of variables is typically a theoretical exercise with few practical methods for high-dimensional data. A promising solution would be a multivariate generalization of the famous Wyner common information, but this approach relies on solving an apparently intractable optimization problem. We leverage the recently introduced information sieve decomposition to formulate an incremental version of the common information problem that admits a simple fixed point solution, fast convergence, and complexity that is linear in the number of variables. This scalable approach allows us to demonstrate the usefulness of common information in high-dimensional learning problems. The sieve outperforms standard methods on dimensionality reduction tasks, solves a blind source separation problem that cannot be solved with ICA, and accurately recovers structure in brain imaging data.
Variational Information Maximization for Feature Selection
Jun 09, 2016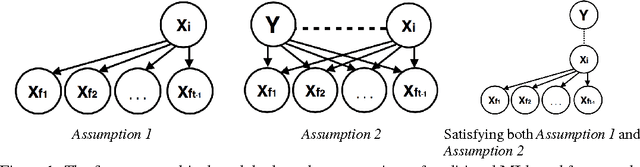


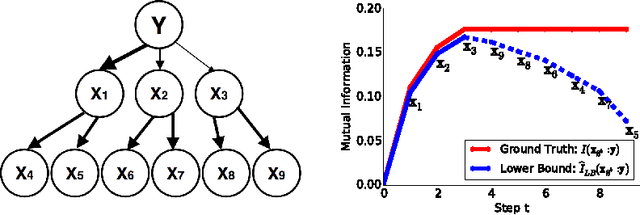
Feature selection is one of the most fundamental problems in machine learning. An extensive body of work on information-theoretic feature selection exists which is based on maximizing mutual information between subsets of features and class labels. Practical methods are forced to rely on approximations due to the difficulty of estimating mutual information. We demonstrate that approximations made by existing methods are based on unrealistic assumptions. We formulate a more flexible and general class of assumptions based on variational distributions and use them to tractably generate lower bounds for mutual information. These bounds define a novel information-theoretic framework for feature selection, which we prove to be optimal under tree graphical models with proper choice of variational distributions. Our experiments demonstrate that the proposed method strongly outperforms existing information-theoretic feature selection approaches.
The DARPA Twitter Bot Challenge
Apr 21, 2016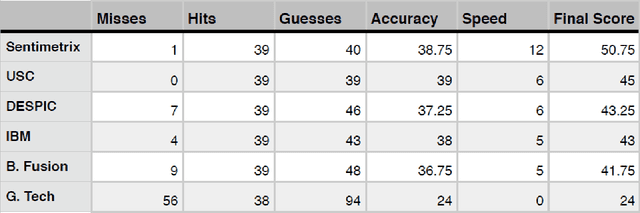
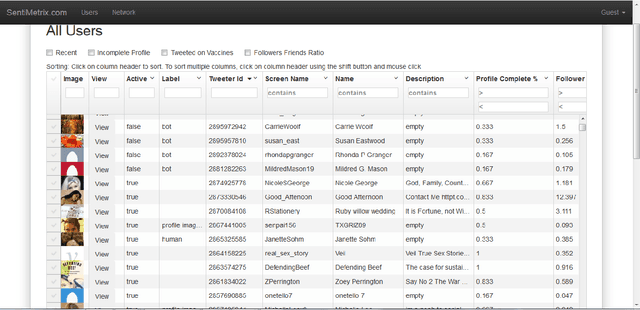
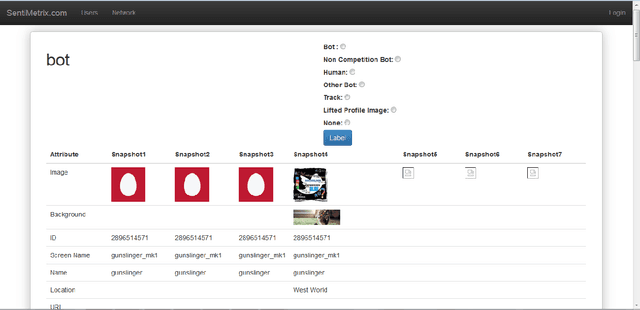
A number of organizations ranging from terrorist groups such as ISIS to politicians and nation states reportedly conduct explicit campaigns to influence opinion on social media, posing a risk to democratic processes. There is thus a growing need to identify and eliminate "influence bots" - realistic, automated identities that illicitly shape discussion on sites like Twitter and Facebook - before they get too influential. Spurred by such events, DARPA held a 4-week competition in February/March 2015 in which multiple teams supported by the DARPA Social Media in Strategic Communications program competed to identify a set of previously identified "influence bots" serving as ground truth on a specific topic within Twitter. Past work regarding influence bots often has difficulty supporting claims about accuracy, since there is limited ground truth (though some exceptions do exist [3,7]). However, with the exception of [3], no past work has looked specifically at identifying influence bots on a specific topic. This paper describes the DARPA Challenge and describes the methods used by the three top-ranked teams.
* IEEE Computer Magazine, in press
Understanding confounding effects in linguistic coordination: an information-theoretic approach
Aug 27, 2015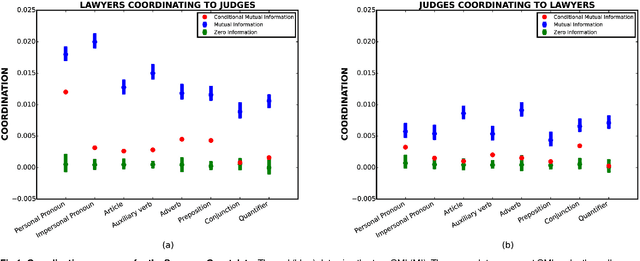
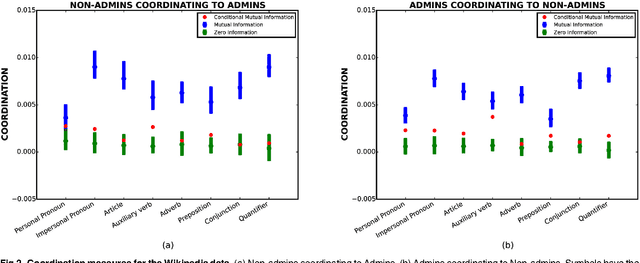
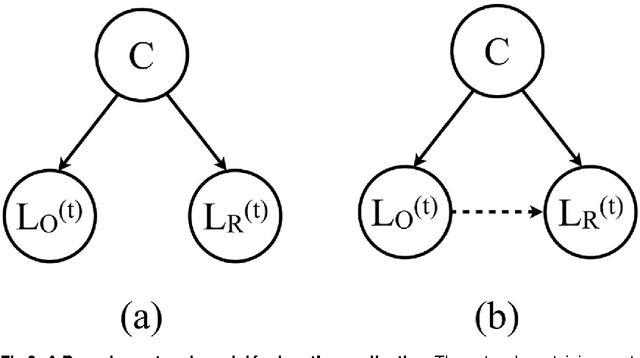
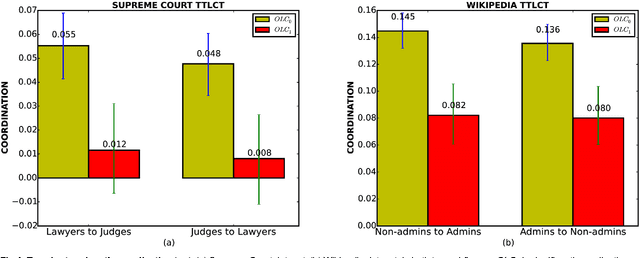
We suggest an information-theoretic approach for measuring stylistic coordination in dialogues. The proposed measure has a simple predictive interpretation and can account for various confounding factors through proper conditioning. We revisit some of the previous studies that reported strong signatures of stylistic accommodation, and find that a significant part of the observed coordination can be attributed to a simple confounding effect - length coordination. Specifically, longer utterances tend to be followed by longer responses, which gives rise to spurious correlations in the other stylistic features. We propose a test to distinguish correlations in length due to contextual factors (topic of conversation, user verbosity, etc.) and turn-by-turn coordination. We also suggest a test to identify whether stylistic coordination persists even after accounting for length coordination and contextual factors.
Efficient Estimation of Mutual Information for Strongly Dependent Variables
Mar 05, 2015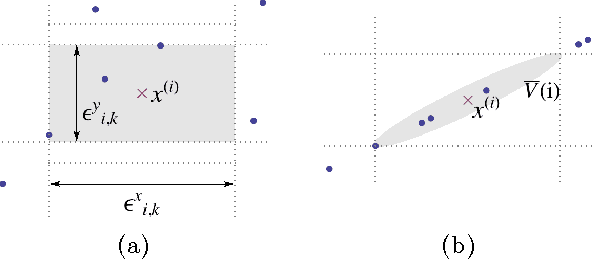
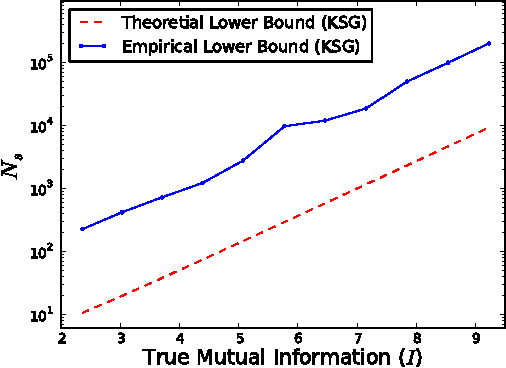
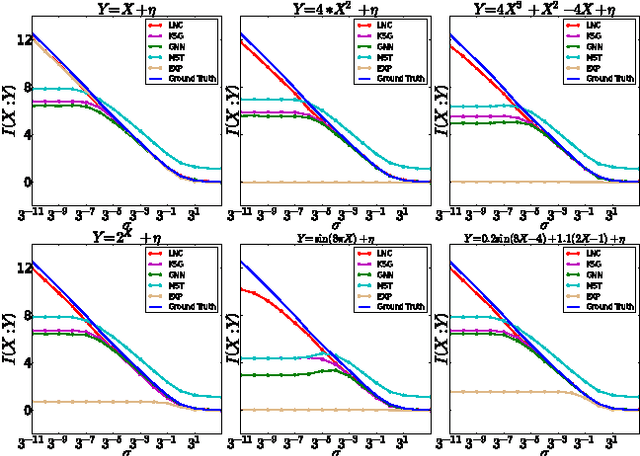
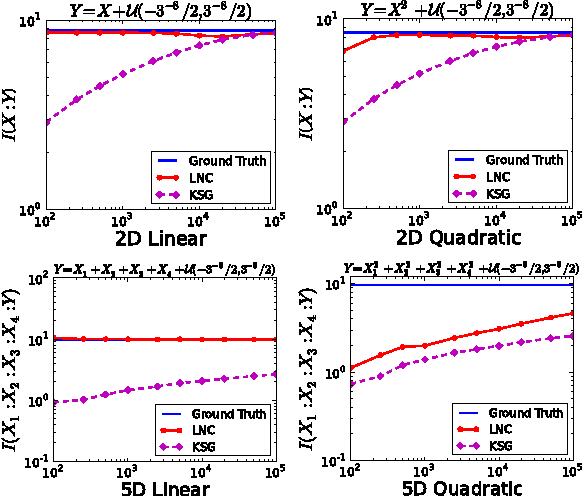
We demonstrate that a popular class of nonparametric mutual information (MI) estimators based on k-nearest-neighbor graphs requires number of samples that scales exponentially with the true MI. Consequently, accurate estimation of MI between two strongly dependent variables is possible only for prohibitively large sample size. This important yet overlooked shortcoming of the existing estimators is due to their implicit reliance on local uniformity of the underlying joint distribution. We introduce a new estimator that is robust to local non-uniformity, works well with limited data, and is able to capture relationship strengths over many orders of magnitude. We demonstrate the superior performance of the proposed estimator on both synthetic and real-world data.