 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEveryone-Can-Sing: Zero-Shot Singing Voice Synthesis and Conversion with Speech Reference
Jan 23, 2025We propose a unified framework for Singing Voice Synthesis (SVS) and Conversion (SVC), addressing the limitations of existing approaches in cross-domain SVS/SVC, poor output musicality, and scarcity of singing data. Our framework enables control over multiple aspects, including language content based on lyrics, performance attributes based on a musical score, singing style and vocal techniques based on a selector, and voice identity based on a speech sample. The proposed zero-shot learning paradigm consists of one SVS model and two SVC models, utilizing pre-trained content embeddings and a diffusion-based generator. The proposed framework is also trained on mixed datasets comprising both singing and speech audio, allowing singing voice cloning based on speech reference. Experiments show substantial improvements in timbre similarity and musicality over state-of-the-art baselines, providing insights into other low-data music tasks such as instrumental style transfer. Examples can be found at: everyone-can-sing.github.io.
Foundation Models for Music: A Survey
Aug 27, 2024



In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
Relating Human Perception of Musicality to Prediction in a Predictive Coding Model
Oct 29, 2022



We explore the use of a neural network inspired by predictive coding for modeling human music perception. This network was developed based on the computational neuroscience theory of recurrent interactions in the hierarchical visual cortex. When trained with video data using self-supervised learning, the model manifests behaviors consistent with human visual illusions. Here, we adapt this network to model the hierarchical auditory system and investigate whether it will make similar choices to humans regarding the musicality of a set of random pitch sequences. When the model is trained with a large corpus of instrumental classical music and popular melodies rendered as mel spectrograms, it exhibits greater prediction errors for random pitch sequences that are rated less musical by human subjects. We found that the prediction error depends on the amount of information regarding the subsequent note, the pitch interval, and the temporal context. Our findings suggest that predictability is correlated with human perception of musicality and that a predictive coding neural network trained on music can be used to characterize the features and motifs contributing to human perception of music.
Controllable deep melody generation via hierarchical music structure representation
Sep 02, 2021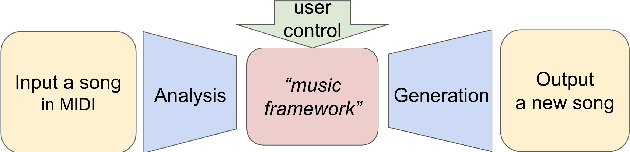
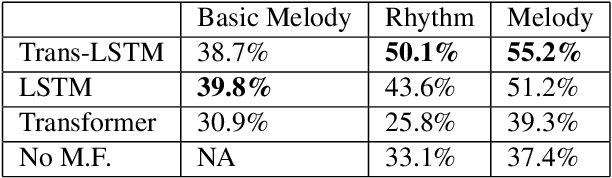
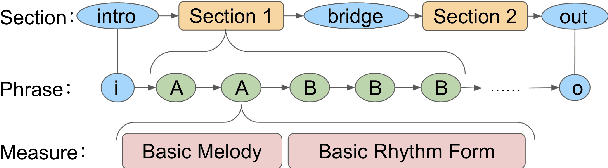
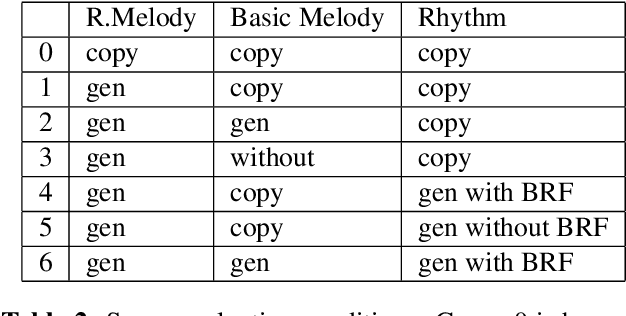
Recent advances in deep learning have expanded possibilities to generate music, but generating a customizable full piece of music with consistent long-term structure remains a challenge. This paper introduces MusicFrameworks, a hierarchical music structure representation and a multi-step generative process to create a full-length melody guided by long-term repetitive structure, chord, melodic contour, and rhythm constraints. We first organize the full melody with section and phrase-level structure. To generate melody in each phrase, we generate rhythm and basic melody using two separate transformer-based networks, and then generate the melody conditioned on the basic melody, rhythm and chords in an auto-regressive manner. By factoring music generation into sub-problems, our approach allows simpler models and requires less data. To customize or add variety, one can alter chords, basic melody, and rhythm structure in the music frameworks, letting our networks generate the melody accordingly. Additionally, we introduce new features to encode musical positional information, rhythm patterns, and melodic contours based on musical domain knowledge. A listening test reveals that melodies generated by our method are rated as good as or better than human-composed music in the POP909 dataset about half the time.
Personalized Popular Music Generation Using Imitation and Structure
May 10, 2021

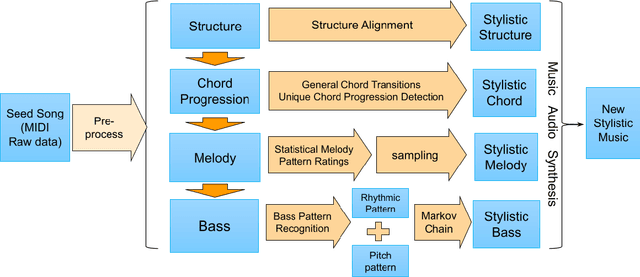

Many practices have been presented in music generation recently. While stylistic music generation using deep learning techniques has became the main stream, these models still struggle to generate music with high musicality, different levels of music structure, and controllability. In addition, more application scenarios such as music therapy require imitating more specific musical styles from a few given music examples, rather than capturing the overall genre style of a large data corpus. To address requirements that challenge current deep learning methods, we propose a statistical machine learning model that is able to capture and imitate the structure, melody, chord, and bass style from a given example seed song. An evaluation using 10 pop songs shows that our new representations and methods are able to create high-quality stylistic music that is similar to a given input song. We also discuss potential uses of our approach in music evaluation and music therapy.
POP909: A Pop-song Dataset for Music Arrangement Generation
Aug 17, 2020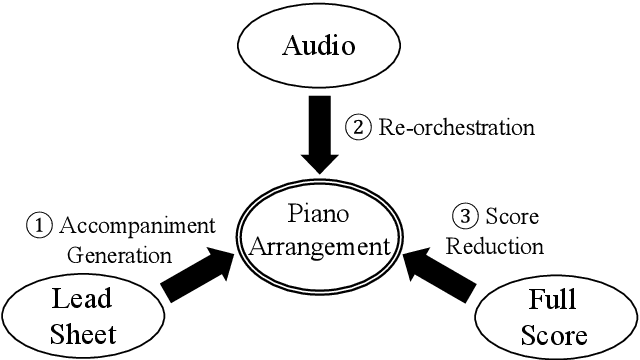
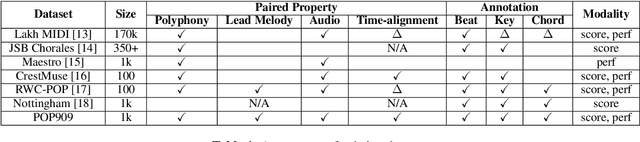
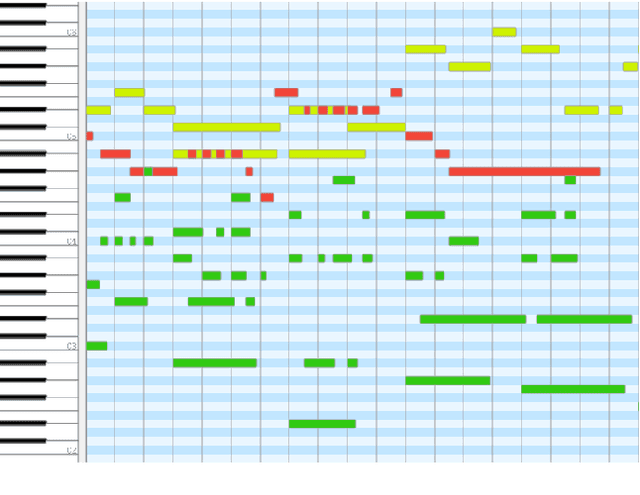
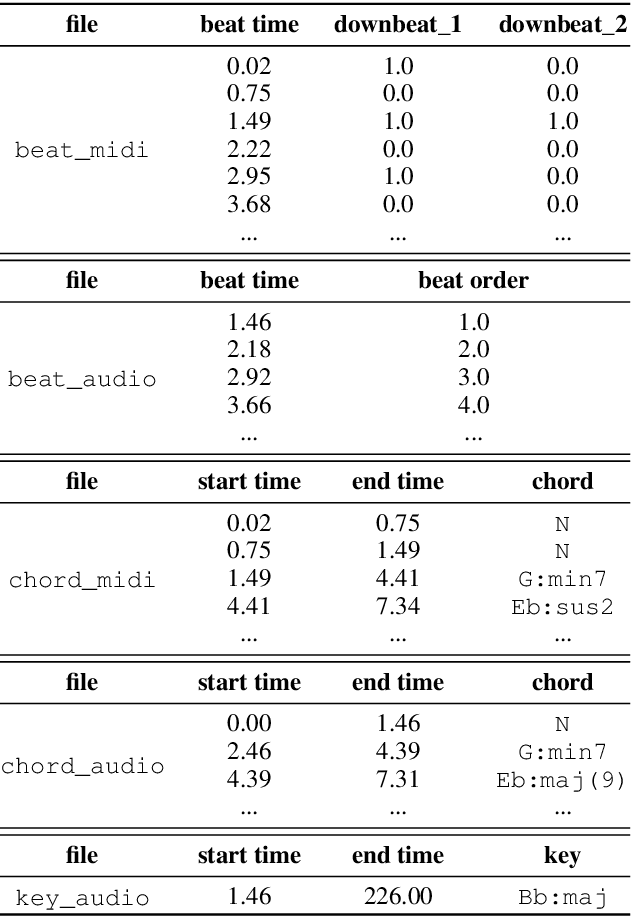
Music arrangement generation is a subtask of automatic music generation, which involves reconstructing and re-conceptualizing a piece with new compositional techniques. Such a generation process inevitably requires reference from the original melody, chord progression, or other structural information. Despite some promising models for arrangement, they lack more refined data to achieve better evaluations and more practical results. In this paper, we propose POP909, a dataset which contains multiple versions of the piano arrangements of 909 popular songs created by professional musicians. The main body of the dataset contains the vocal melody, the lead instrument melody, and the piano accompaniment for each song in MIDI format, which are aligned to the original audio files. Furthermore, we provide the annotations of tempo, beat, key, and chords, where the tempo curves are hand-labeled and others are done by MIR algorithms. Finally, we conduct several baseline experiments with this dataset using standard deep music generation algorithms.