 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiDexGrasp: Coordinated Bimanual Dexterous Grasps across Object Geometries and Sizes
Apr 08, 2026Bimanual dexterous grasping is a fundamental and promising area in robotics, yet its progress is constrained by the lack of comprehensive datasets and powerful generation models. In this work, we propose BiDexGrasp, consists of a large-scale bimanual dexterous grasp dataset and a novel generation model. For dataset, we propose a novel bimanual grasp synthesis pipeline to efficiently annotate physically feasible data for dataset construction. This pipeline addresses the challenges of high-dimensional bimanual grasping through a two-stage synthesis strategy of efficient region-based grasp initialization and decoupled force-closure grasp optimization. Powered by this pipeline, we construct a large-scale bimanual dexterous grasp dataset, comprising 6351 diverse objects with sizes ranging from 30 to 80 cm, along with 9.7 million annotated grasp data. Based on this dataset, we further introduce a bimanual-coordinated and geometry-size-adaptive dexterous grasping generation framework. The framework lies in two key designs: a bimanual coordination module and a geometry-size-adaptive grasp generation strategy to generate coordinated and high-quality grasps on unseen objects. Extensive experiments conducted in both simulation and real world demonstrate the superior performance of our proposed data synthesis pipeline and learned generative framework.
OmniDexGrasp: Generalizable Dexterous Grasping via Foundation Model and Force Feedback
Oct 27, 2025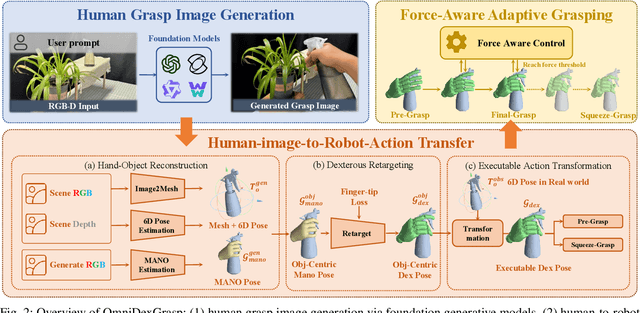


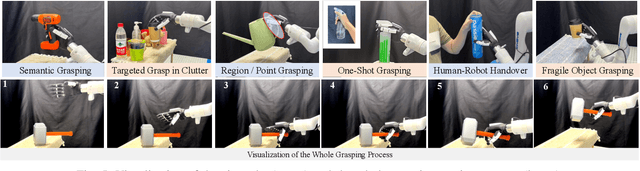
Enabling robots to dexterously grasp and manipulate objects based on human commands is a promising direction in robotics. However, existing approaches are challenging to generalize across diverse objects or tasks due to the limited scale of semantic dexterous grasp datasets. Foundation models offer a new way to enhance generalization, yet directly leveraging them to generate feasible robotic actions remains challenging due to the gap between abstract model knowledge and physical robot execution. To address these challenges, we propose OmniDexGrasp, a generalizable framework that achieves omni-capabilities in user prompting, dexterous embodiment, and grasping tasks by combining foundation models with the transfer and control strategies. OmniDexGrasp integrates three key modules: (i) foundation models are used to enhance generalization by generating human grasp images supporting omni-capability of user prompt and task; (ii) a human-image-to-robot-action transfer strategy converts human demonstrations into executable robot actions, enabling omni dexterous embodiment; (iii) force-aware adaptive grasp strategy ensures robust and stable grasp execution. Experiments in simulation and on real robots validate the effectiveness of OmniDexGrasp on diverse user prompts, grasp task and dexterous hands, and further results show its extensibility to dexterous manipulation tasks.