 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLevenshtein Training for Word-level Quality Estimation
Sep 15, 2021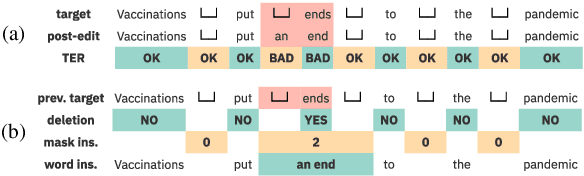
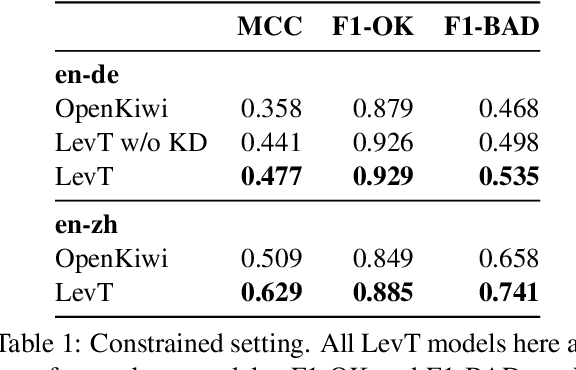
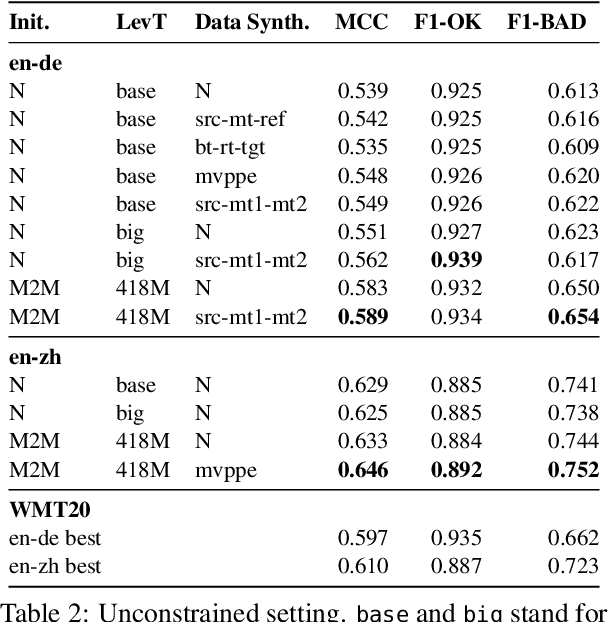
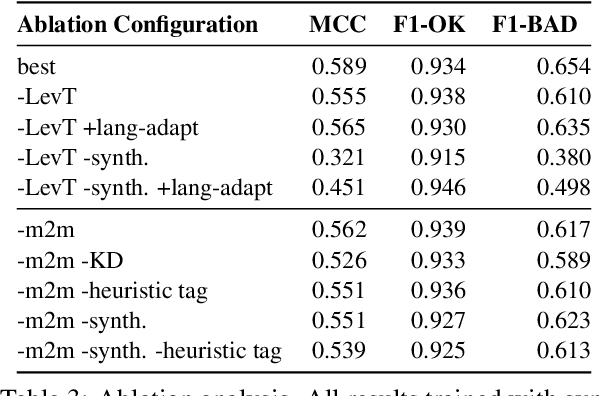
We propose a novel scheme to use the Levenshtein Transformer to perform the task of word-level quality estimation. A Levenshtein Transformer is a natural fit for this task: trained to perform decoding in an iterative manner, a Levenshtein Transformer can learn to post-edit without explicit supervision. To further minimize the mismatch between the translation task and the word-level QE task, we propose a two-stage transfer learning procedure on both augmented data and human post-editing data. We also propose heuristics to construct reference labels that are compatible with subword-level finetuning and inference. Results on WMT 2020 QE shared task dataset show that our proposed method has superior data efficiency under the data-constrained setting and competitive performance under the unconstrained setting.
Evaluating Saliency Methods for Neural Language Models
Apr 12, 2021
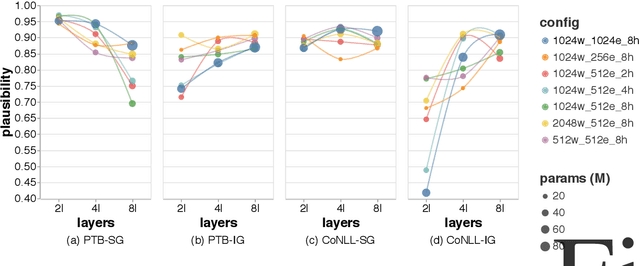

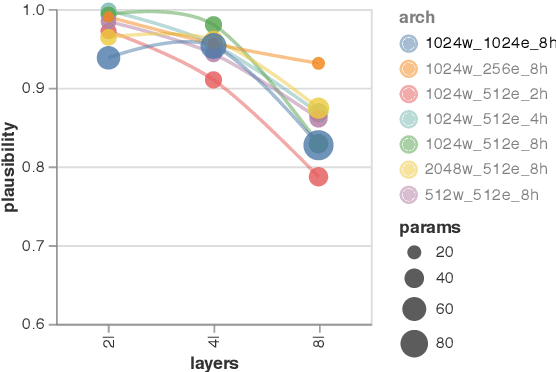
Saliency methods are widely used to interpret neural network predictions, but different variants of saliency methods often disagree even on the interpretations of the same prediction made by the same model. In these cases, how do we identify when are these interpretations trustworthy enough to be used in analyses? To address this question, we conduct a comprehensive and quantitative evaluation of saliency methods on a fundamental category of NLP models: neural language models. We evaluate the quality of prediction interpretations from two perspectives that each represents a desirable property of these interpretations: plausibility and faithfulness. Our evaluation is conducted on four different datasets constructed from the existing human annotation of syntactic and semantic agreements, on both sentence-level and document-level. Through our evaluation, we identified various ways saliency methods could yield interpretations of low quality. We recommend that future work deploying such methods to neural language models should carefully validate their interpretations before drawing insights.
Espresso: A Fast End-to-end Neural Speech Recognition Toolkit
Oct 15, 2019
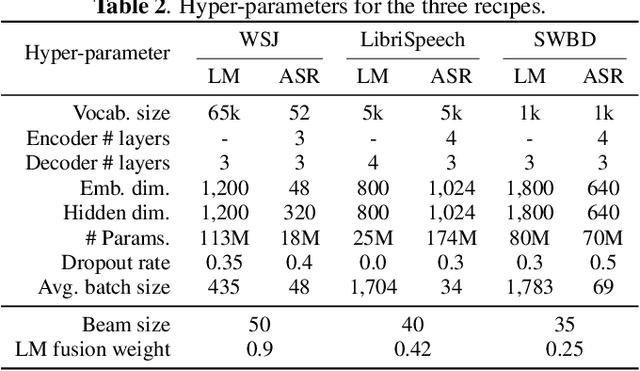
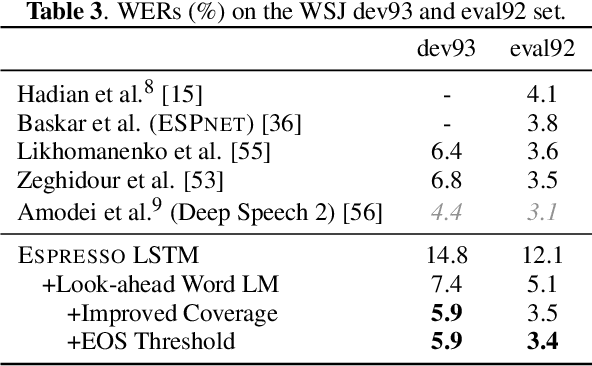
We present Espresso, an open-source, modular, extensible end-to-end neural automatic speech recognition (ASR) toolkit based on the deep learning library PyTorch and the popular neural machine translation toolkit fairseq. Espresso supports distributed training across GPUs and computing nodes, and features various decoding approaches commonly employed in ASR, including look-ahead word-based language model fusion, for which a fast, parallelized decoder is implemented. Espresso achieves state-of-the-art ASR performance on the WSJ, LibriSpeech, and Switchboard data sets among other end-to-end systems without data augmentation, and is 4--11x faster for decoding than similar systems (e.g. ESPnet).
Saliency-driven Word Alignment Interpretation for Neural Machine Translation
Jun 27, 2019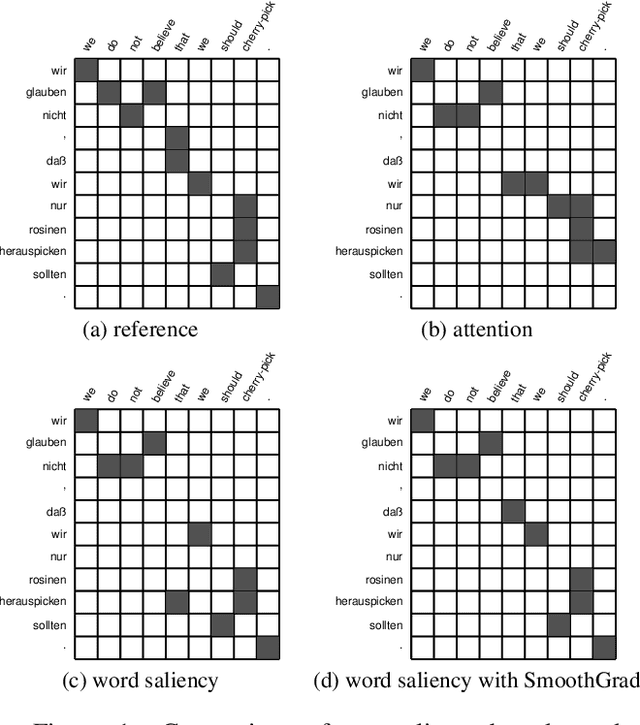
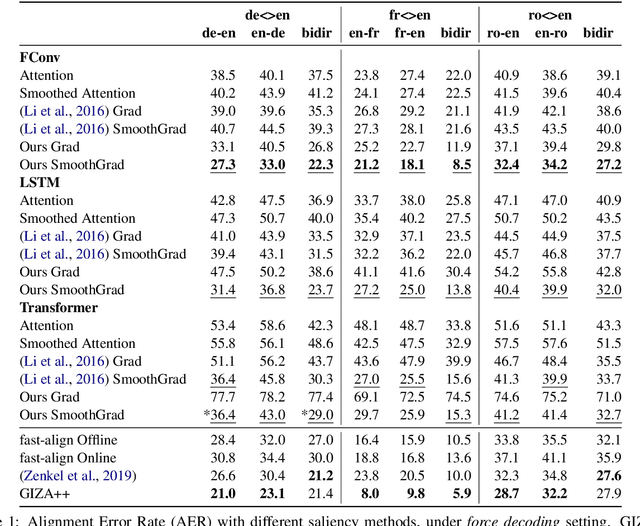
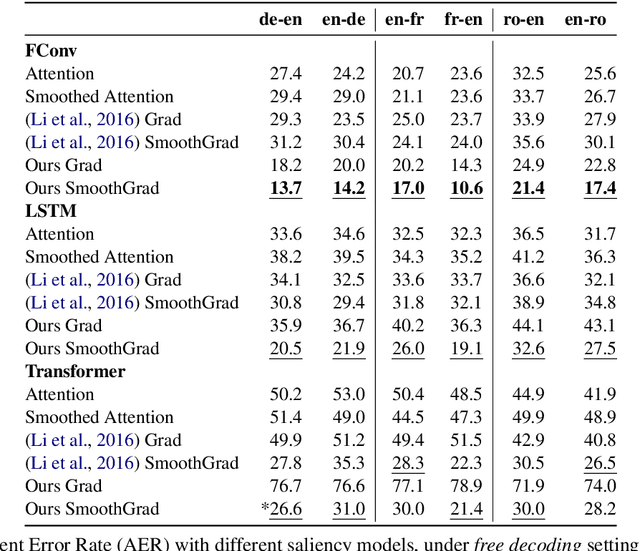
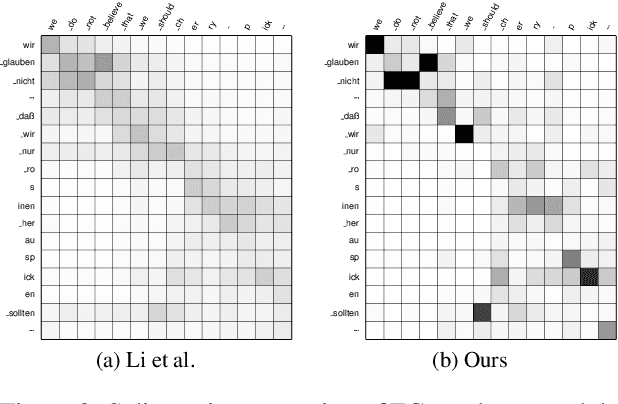
Despite their original goal to jointly learn to align and translate, Neural Machine Translation (NMT) models, especially Transformer, are often perceived as not learning interpretable word alignments. In this paper, we show that NMT models do learn interpretable word alignments, which could only be revealed with proper interpretation methods. We propose a series of such methods that are model-agnostic, are able to be applied either offline or online, and do not require parameter update or architectural change. We show that under the force decoding setup, the alignments induced by our interpretation method are of better quality than fast-align for some systems, and when performing free decoding, they agree well with the alignments induced by automatic alignment tools.
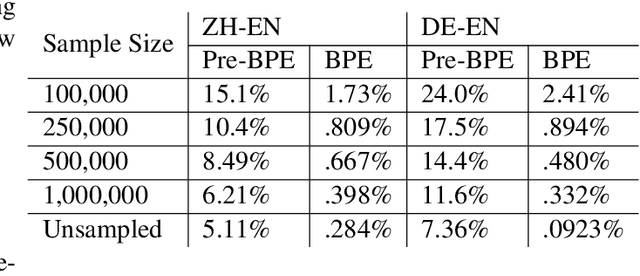
A Call for Prudent Choice of Subword Merge Operations
May 24, 2019
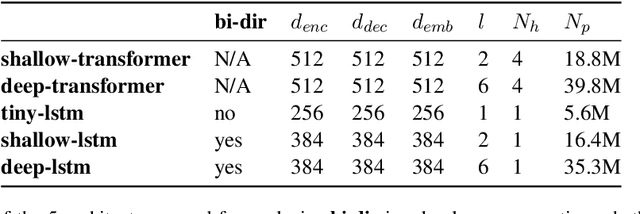
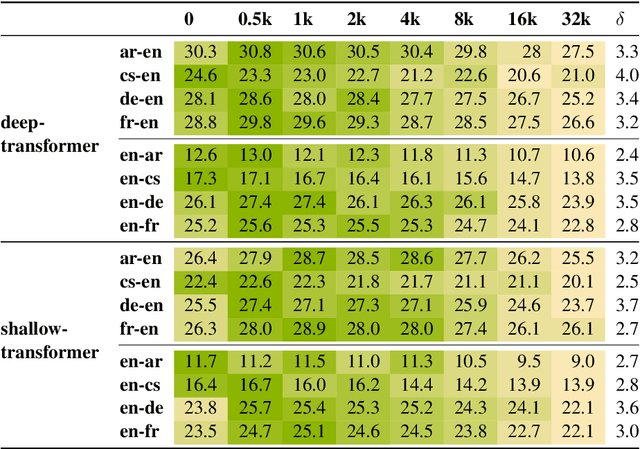
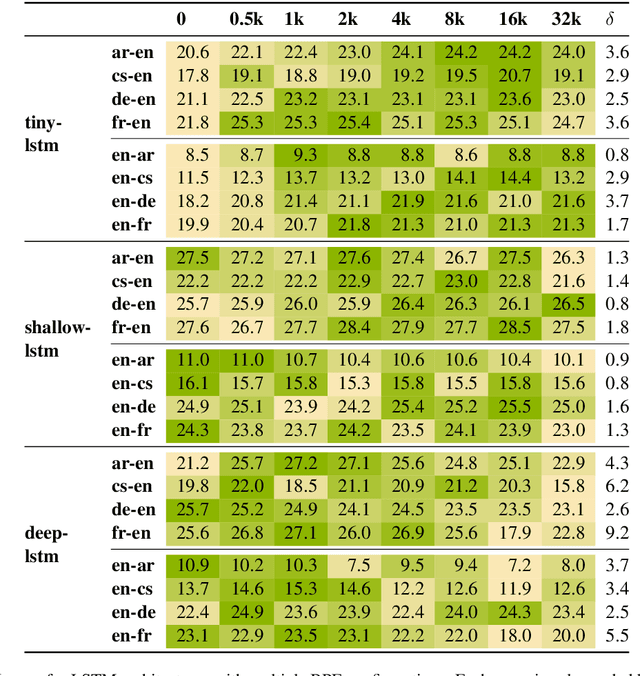
Most neural machine translation systems are built upon subword units extracted by methods such as Byte-Pair Encoding (BPE) or wordpiece. However, the choice of number of merge operations is generally made by following existing recipes. In this paper, we conduct a systematic exploration of different BPE merge operations to understand how it interacts with the model architecture, the strategy to build vocabularies and the language pair. Our exploration could provide guidance for selecting proper BPE configurations in the future. Most prominently: we show that for LSTM-based architectures, it is necessary to experiment with a wide range of different BPE operations as there is no typical optimal BPE configuration, whereas for Transformer architectures, smaller BPE size tends to be a typically optimal choice. We urge the community to make prudent choices with subword merge operations, as our experiments indicate that a sub-optimal BPE configuration alone could easily reduce the system performance by 3-4 BLEU points.
Parallelizable Stack Long Short-Term Memory
Apr 06, 2019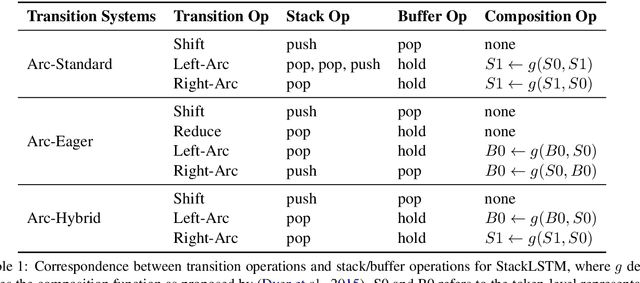
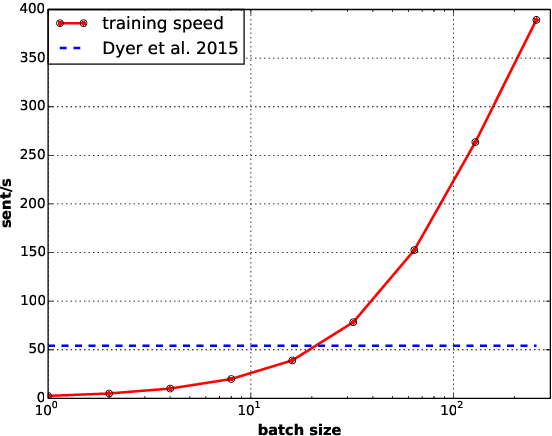
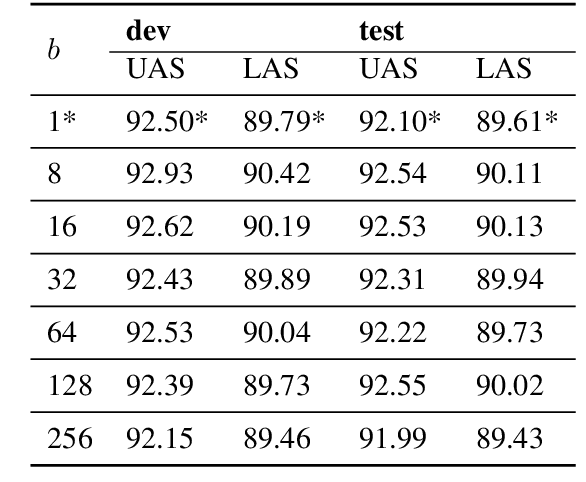
Stack Long Short-Term Memory (StackLSTM) is useful for various applications such as parsing and string-to-tree neural machine translation, but it is also known to be notoriously difficult to parallelize for GPU training due to the fact that the computations are dependent on discrete operations. In this paper, we tackle this problem by utilizing state access patterns of StackLSTM to homogenize computations with regard to different discrete operations. Our parsing experiments show that the method scales up almost linearly with increasing batch size, and our parallelized PyTorch implementation trains significantly faster compared to the Dynet C++ implementation.
Improving End-to-end Speech Recognition with Pronunciation-assisted Sub-word Modeling
Nov 10, 2018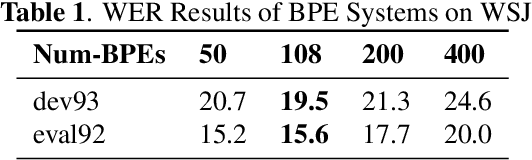
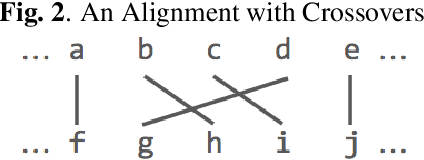

In recent years, end-to-end models have become popular for application in automatic speech recognition. Compared to hybrid approaches, which perform the phone-sequence to word conversion based on a lexicon, an end-to-end system models text directly, usually as a sequence of characters or sub-word features. We propose a sub-word modeling method that leverages the pronunciation information of a word. Experiments show that the proposed method can greatly improve upon the character-based baseline, and also outperform commonly used byte-pair encoding methods.
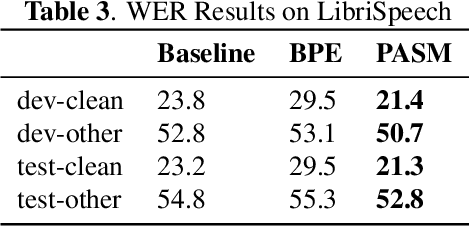
Multi-Modal Data Augmentation for End-to-End ASR
Jun 18, 2018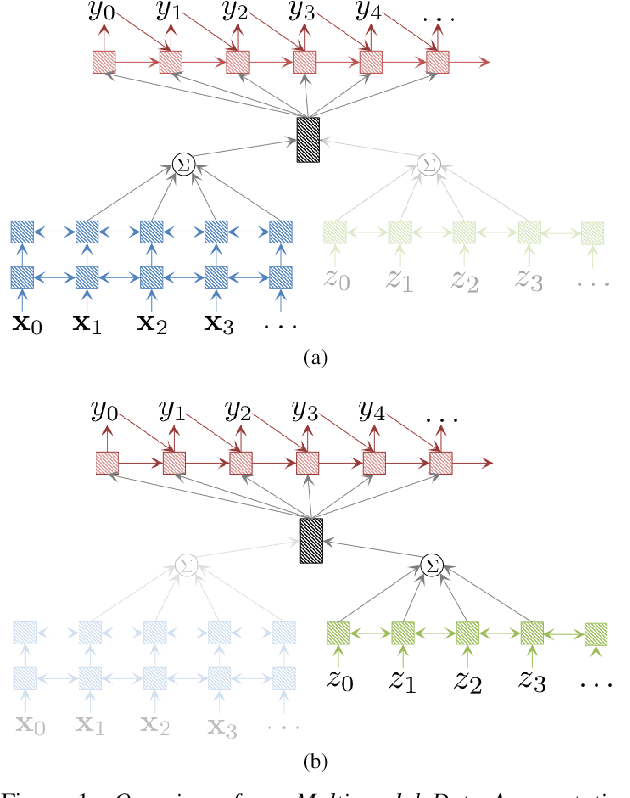

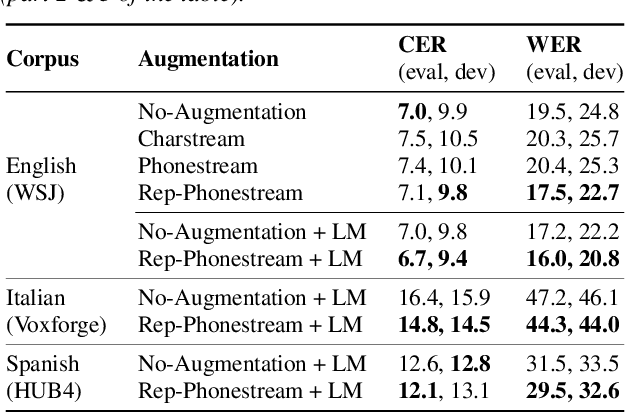
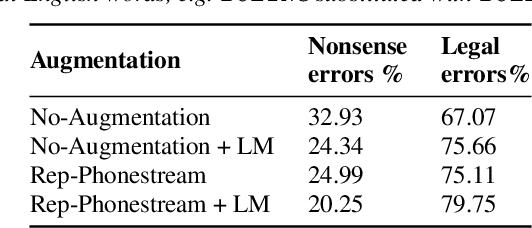
We present a new end-to-end architecture for automatic speech recognition (ASR) that can be trained using \emph{symbolic} input in addition to the traditional acoustic input. This architecture utilizes two separate encoders: one for acoustic input and another for symbolic input, both sharing the attention and decoder parameters. We call this architecture a multi-modal data augmentation network (MMDA), as it can support multi-modal (acoustic and symbolic) input and enables seamless mixing of large text datasets with significantly smaller transcribed speech corpora during training. We study different ways of transforming large text corpora into a symbolic form suitable for training our MMDA network. Our best MMDA setup obtains small improvements on character error rate (CER), and as much as 7-10\% relative word error rate (WER) improvement over a baseline both with and without an external language model.
How Do Source-side Monolingual Word Embeddings Impact Neural Machine Translation?
Jun 14, 2018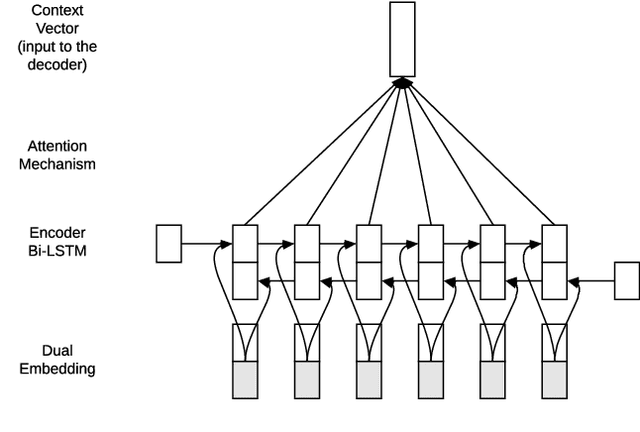
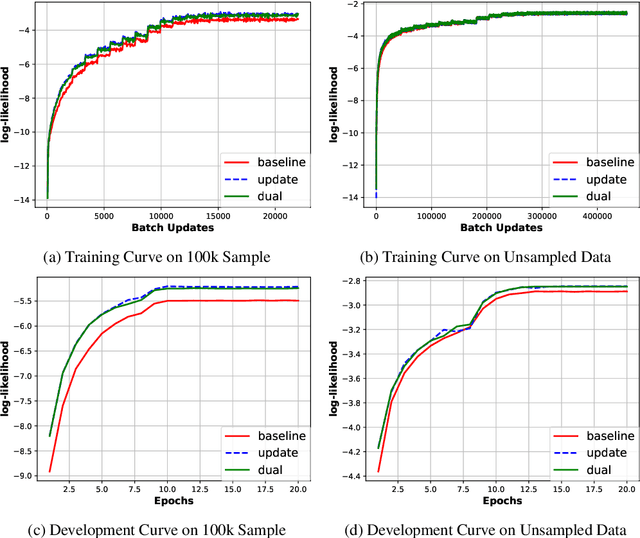
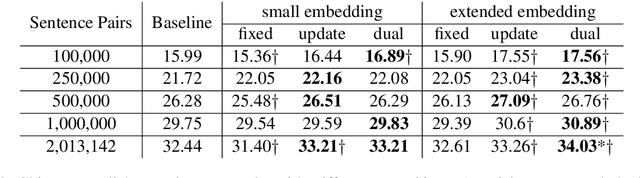
Using pre-trained word embeddings as input layer is a common practice in many natural language processing (NLP) tasks, but it is largely neglected for neural machine translation (NMT). In this paper, we conducted a systematic analysis on the effect of using pre-trained source-side monolingual word embedding in NMT. We compared several strategies, such as fixing or updating the embeddings during NMT training on varying amounts of data, and we also proposed a novel strategy called dual-embedding that blends the fixing and updating strategies. Our results suggest that pre-trained embeddings can be helpful if properly incorporated into NMT, especially when parallel data is limited or additional in-domain monolingual data is readily available.