 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveScope: Actively Seeking and Correcting Perception for MLLMs
Jun 23, 2026Multimodal Large Language Models (MLLMs) have demonstrated impressive vision-language understanding, yet still struggle with fine-grained perception in high-resolution images. While existing training-free methods typically rely on attention-based localization or coarse-to-fine search, they are often misled by distractors and fail to locate multiple targets. Our investigation attributes these failures to Contextual Dominance, where salient distractors overwhelm target attention and cause inaccurate localization, and Semantic Bias, where global semantics cause the model to fixate on the most salient concept, resulting in incomplete localization in multi-object scenarios. Built on these insights, we propose ActiveScope, a training-free framework that enhances MLLMs by actively seeking and correcting perception. ActiveScope features two modules. The Semantic Anchor Localization (SAL) utilizes fine-grained semantic anchors to independently localize key targets, thereby mitigating semantic bias. The Interference-Suppressed Refinement (ISR) refines localization by suppressing attention on salient distractions to overcome contextual dominance. Extensive experiments on high-resolution image understanding benchmarks demonstrate that ActiveScope outperforms existing training-free methods (e.g., 96.34 percent accuracy on $V^{*}$ Bench), validating the superiority of the active search and self-correction paradigm. Our code is available at https://github.com/jasmine-ww/ActiveScope.
Locate-then-Sparsify: Attribution Guided Sparse Strategy for Visual Hallucination Mitigation
Mar 17, 2026Despite the significant advancements in Large Vision-Language Models (LVLMs), their tendency to generate hallucinations undermines reliability and restricts broader practical deployment. Among the hallucination mitigation methods, feature steering emerges as a promising approach that reduces erroneous outputs in LVLMs without increasing inference costs. However, current methods apply uniform feature steering across all layers. This heuristic strategy ignores inter-layer differences, potentially disrupting layers unrelated to hallucinations and ultimately leading to performance degradation on general tasks. In this paper, we propose a plug-and-play framework called Locate-Then-Sparsify for Feature Steering (LTS-FS), which controls the steering intensity according to the hallucination relevance of each layer. We first construct a synthetic dataset comprising token-level and sentence-level hallucination cases. Based on this dataset, we introduce an attribution method based on causal interventions to quantify the hallucination relevance of each layer. With the attribution scores across layers, we propose a layerwise strategy that converts these scores into feature steering intensities for individual layers, enabling more precise adjustments specifically on hallucination-relevant layers. Extensive experiments across multiple LVLMs and benchmarks demonstrate that our LTS-FS framework effectively mitigates hallucination while preserving strong performance.
Expanding Sparse Tuning for Low Memory Usage
Nov 04, 2024



Parameter-efficient fine-tuning (PEFT) is an effective method for adapting pre-trained vision models to downstream tasks by tuning a small subset of parameters. Among PEFT methods, sparse tuning achieves superior performance by only adjusting the weights most relevant to downstream tasks, rather than densely tuning the whole weight matrix. However, this performance improvement has been accompanied by increases in memory usage, which stems from two factors, i.e., the storage of the whole weight matrix as learnable parameters in the optimizer and the additional storage of tunable weight indexes. In this paper, we propose a method named SNELL (Sparse tuning with kerNELized LoRA) for sparse tuning with low memory usage. To achieve low memory usage, SNELL decomposes the tunable matrix for sparsification into two learnable low-rank matrices, saving from the costly storage of the whole original matrix. A competition-based sparsification mechanism is further proposed to avoid the storage of tunable weight indexes. To maintain the effectiveness of sparse tuning with low-rank matrices, we extend the low-rank decomposition by applying nonlinear kernel functions to the whole-matrix merging. Consequently, we gain an increase in the rank of the merged matrix, enhancing the ability of SNELL in adapting the pre-trained models to downstream tasks. Extensive experiments on multiple downstream tasks show that SNELL achieves state-of-the-art performance with low memory usage, endowing PEFT with sparse tuning to large-scale models. Codes are available at https://github.com/ssfgunner/SNELL.
Tongji University Undergraduate Team for the VoxCeleb Speaker Recognition Challenge2020
Oct 20, 2020
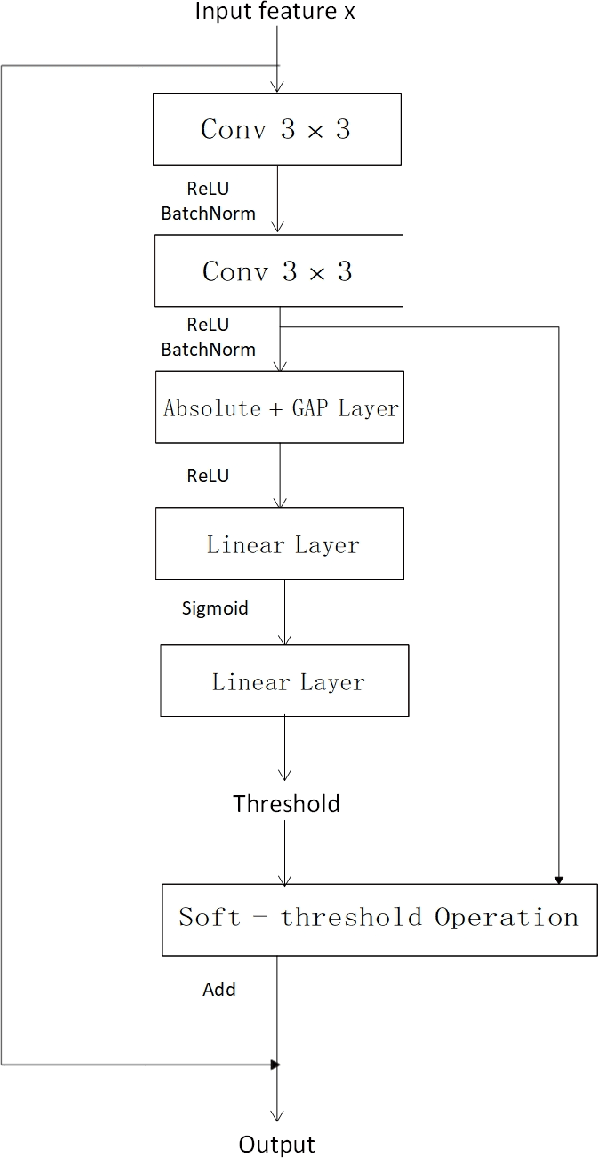

In this report, we discribe the submission of Tongji University undergraduate team to the CLOSE track of the VoxCeleb Speaker Recognition Challenge (VoxSRC) 2020 at Interspeech 2020. We applied the RSBU-CW module to the ResNet34 framework to improve the denoising ability of the network and better complete the speaker verification task in a complex environment.We trained two variants of ResNet,used score fusion and data-augmentation methods to improve the performance of the model. Our fusion of two selected systems for the CLOSE track achieves 0.2973 DCF and 4.9700\% EER on the challenge evaluation set.