 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPC-VQA: Decoupling Quality Perception and Residual Calibration for Video Quality Assessment
Apr 14, 2026Recent multimodal large language models (MLLMs) have shown promising performance on video quality assessment (VQA) tasks. However, adapting them to new scenarios remains expensive due to large-scale retraining and costly mean opinion score (MOS) annotations. In this paper, we argue that a pretrained MLLM already provides a useful perceptual prior for VQA, and that the main challenge is to efficiently calibrate this prior to the target MOS space. Based on this insight, we propose DPC-VQA, a decoupling perception and calibration framework for video quality assessment. Specifically, DPC-VQA uses a frozen MLLM to provide a base quality estimate and perceptual prior, and employs a lightweight calibration branch to predict a residual correction for target-scenario adaptation. This design avoids costly end-to-end retraining while maintaining reliable performance with lower training and data costs. Extensive experiments on both user-generated content (UGC) and AI-generated content (AIGC) benchmarks show that DPC-VQA achieves competitive performance against representative baselines, while using less than 2% of the trainable parameters of conventional MLLM-based VQA methods and remaining effective with only 20\% of MOS labels. The code will be released upon publication.
Decoupling Perception and Calibration: Label-Efficient Image Quality Assessment Framework
Jan 28, 2026Recent multimodal large language models (MLLMs) have demonstrated strong capabilities in image quality assessment (IQA) tasks. However, adapting such large-scale models is computationally expensive and still relies on substantial Mean Opinion Score (MOS) annotations. We argue that for MLLM-based IQA, the core bottleneck lies not in the quality perception capacity of MLLMs, but in MOS scale calibration. Therefore, we propose LEAF, a Label-Efficient Image Quality Assessment Framework that distills perceptual quality priors from an MLLM teacher into a lightweight student regressor, enabling MOS calibration with minimal human supervision. Specifically, the teacher conducts dense supervision through point-wise judgments and pair-wise preferences, with an estimate of decision reliability. Guided by these signals, the student learns the teacher's quality perception patterns through joint distillation and is calibrated on a small MOS subset to align with human annotations. Experiments on both user-generated and AI-generated IQA benchmarks demonstrate that our method significantly reduces the need for human annotations while maintaining strong MOS-aligned correlations, making lightweight IQA practical under limited annotation budgets.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
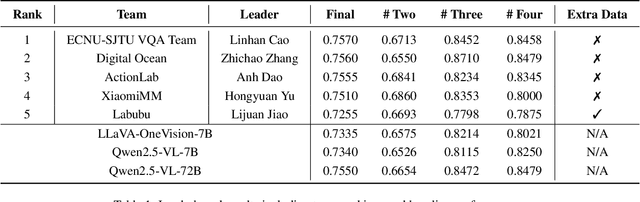
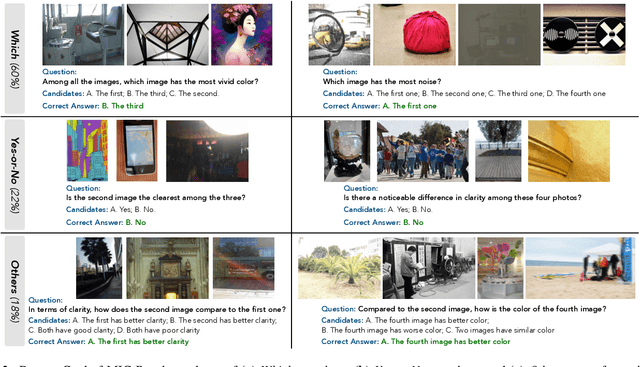
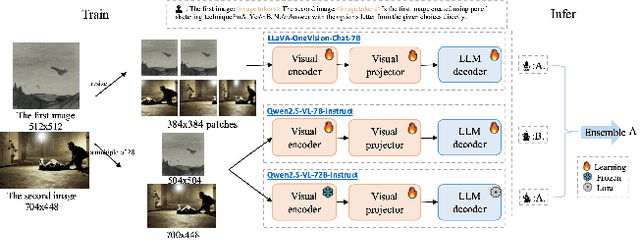
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.