 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFresnel Microfacet BRDF: Unification of Polari-Radiometric Surface-Body Reflection
Dec 08, 2022



Computer vision applications have heavily relied on the linear combination of Lambertian diffuse and microfacet specular reflection models for representing reflected radiance, which turns out to be physically incompatible and limited in applicability. In this paper, we derive a novel analytical reflectance model, which we refer to as Fresnel Microfacet BRDF model, that is physically accurate and generalizes to various real-world surfaces. Our key idea is to model the Fresnel reflection and transmission of the surface microgeometry with a collection of oriented mirror facets, both for body and surface reflections. We carefully derive the Fresnel reflection and transmission for each microfacet as well as the light transport between them in the subsurface. This physically-grounded modeling also allows us to express the polarimetric behavior of reflected light in addition to its radiometric behavior. That is, FMBRDF unifies not only body and surface reflections but also light reflection in radiometry and polarization and represents them in a single model. Experimental results demonstrate its effectiveness in accuracy, expressive power, and image-based estimation.
ViewBirdiformer: Learning to recover ground-plane crowd trajectories and ego-motion from a single ego-centric view
Oct 12, 2022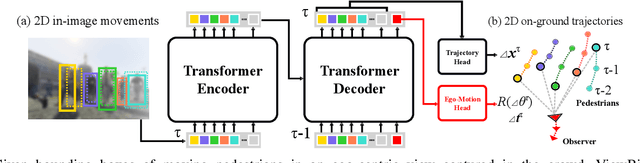
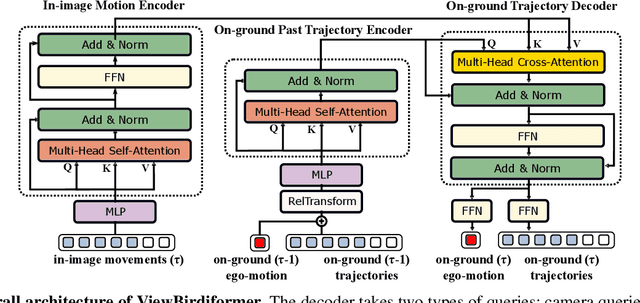
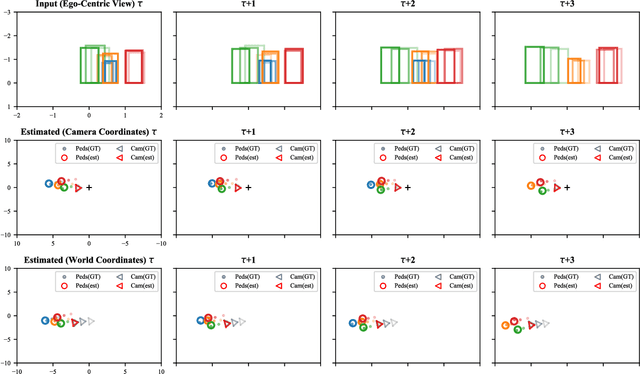
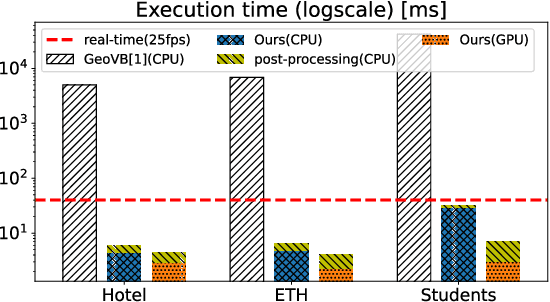
We introduce a novel learning-based method for view birdification, the task of recovering ground-plane trajectories of pedestrians of a crowd and their observer in the same crowd just from the observed ego-centric video. View birdification becomes essential for mobile robot navigation and localization in dense crowds where the static background is hard to see and reliably track. It is challenging mainly for two reasons; i) absolute trajectories of pedestrians are entangled with the movement of the observer which needs to be decoupled from their observed relative movements in the ego-centric video, and ii) a crowd motion model describing the pedestrian movement interactions is specific to the scene yet unknown a priori. For this, we introduce a Transformer-based network referred to as ViewBirdiformer which implicitly models the crowd motion through self-attention and decomposes relative 2D movement observations onto the ground-plane trajectories of the crowd and the camera through cross-attention between views. Most important, ViewBirdiformer achieves view birdification in a single forward pass which opens the door to accurate real-time, always-on situational awareness. Extensive experimental results demonstrate that ViewBirdiformer achieves accuracy similar to or better than state-of-the-art with three orders of magnitude reduction in execution time.
nLMVS-Net: Deep Non-Lambertian Multi-View Stereo
Jul 25, 2022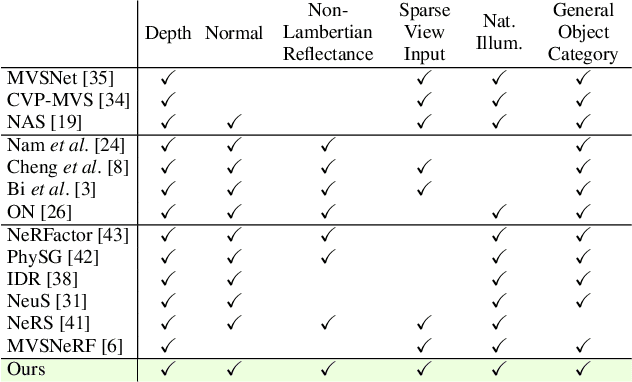
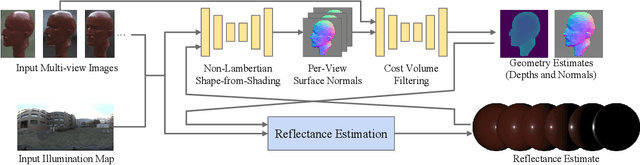

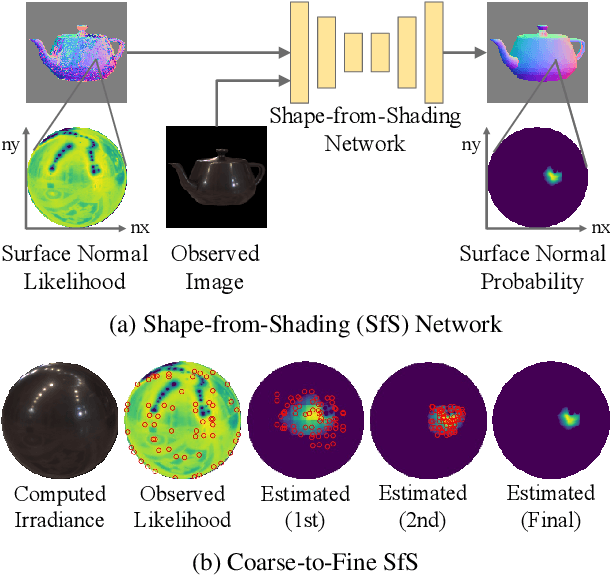
We introduce a novel multi-view stereo (MVS) method that can simultaneously recover not just per-pixel depth but also surface normals, together with the reflectance of textureless, complex non-Lambertian surfaces captured under known but natural illumination. Our key idea is to formulate MVS as an end-to-end learnable network, which we refer to as nLMVS-Net, that seamlessly integrates radiometric cues to leverage surface normals as view-independent surface features for learned cost volume construction and filtering. It first estimates surface normals as pixel-wise probability densities for each view with a novel shape-from-shading network. These per-pixel surface normal densities and the input multi-view images are then input to a novel cost volume filtering network that learns to recover per-pixel depth and surface normal. The reflectance is also explicitly estimated by alternating with geometry reconstruction. Extensive quantitative evaluations on newly established synthetic and real-world datasets show that nLMVS-Net can robustly and accurately recover the shape and reflectance of complex objects in natural settings.
BlindSpotNet: Seeing Where We Cannot See
Jul 08, 2022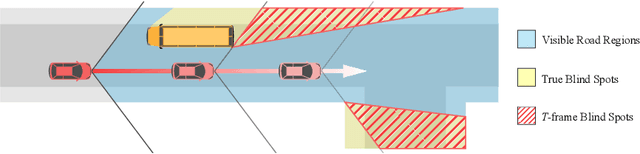

We introduce 2D blind spot estimation as a critical visual task for road scene understanding. By automatically detecting road regions that are occluded from the vehicle's vantage point, we can proactively alert a manual driver or a self-driving system to potential causes of accidents (e.g., draw attention to a road region from which a child may spring out). Detecting blind spots in full 3D would be challenging, as 3D reasoning on the fly even if the car is equipped with LiDAR would be prohibitively expensive and error prone. We instead propose to learn to estimate blind spots in 2D, just from a monocular camera. We achieve this in two steps. We first introduce an automatic method for generating ``ground-truth'' blind spot training data for arbitrary driving videos by leveraging monocular depth estimation, semantic segmentation, and SLAM. The key idea is to reason in 3D but from 2D images by defining blind spots as those road regions that are currently invisible but become visible in the near future. We construct a large-scale dataset with this automatic offline blind spot estimation, which we refer to as Road Blind Spot (RBS) dataset. Next, we introduce BlindSpotNet (BSN), a simple network that fully leverages this dataset for fully automatic estimation of frame-wise blind spot probability maps for arbitrary driving videos. Extensive experimental results demonstrate the validity of our RBS Dataset and the effectiveness of our BSN.
View Birdification in the Crowd: Ground-Plane Localization from Perceived Movements
Nov 09, 2021

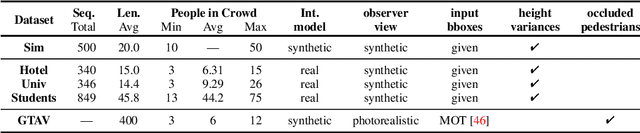
We introduce view birdification, the problem of recovering ground-plane movements of people in a crowd from an ego-centric video captured from an observer (e.g., a person or a vehicle) also moving in the crowd. Recovered ground-plane movements would provide a sound basis for situational understanding and benefit downstream applications in computer vision and robotics. In this paper, we formulate view birdification as a geometric trajectory reconstruction problem and derive a cascaded optimization method from a Bayesian perspective. The method first estimates the observer's movement and then localizes surrounding pedestrians for each frame while taking into account the local interactions between them. We introduce three datasets by leveraging synthetic and real trajectories of people in crowds and evaluate the effectiveness of our method. The results demonstrate the accuracy of our method and set the ground for further studies of view birdification as an important but challenging visual understanding problem.
Structure of Multiple Mirror System from Kaleidoscopic Projections of Single 3D Point
Mar 29, 2021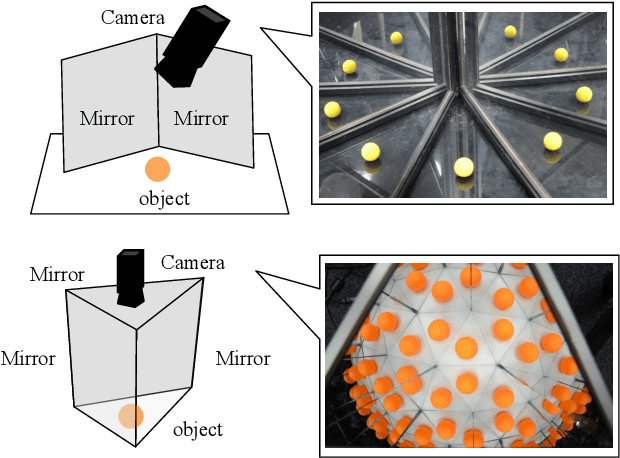
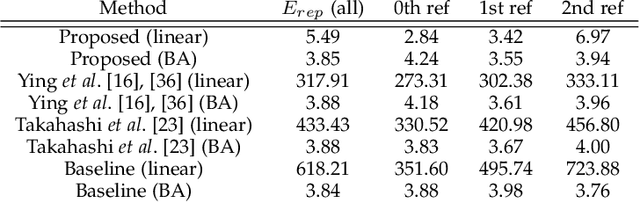
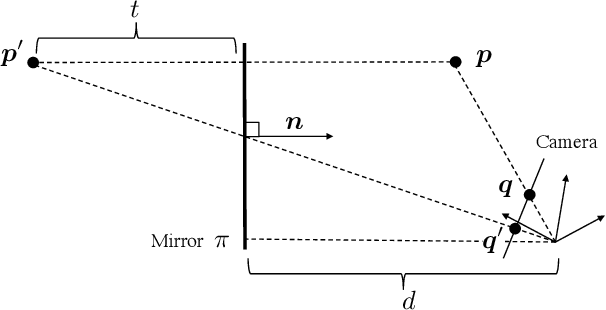
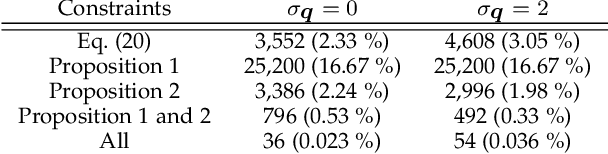
This paper proposes a novel algorithm of discovering the structure of a kaleidoscopic imaging system that consists of multiple planar mirrors and a camera. The kaleidoscopic imaging system can be recognized as the virtual multi-camera system and has strong advantages in that the virtual cameras are strictly synchronized and have the same intrinsic parameters. In this paper, we focus on the extrinsic calibration of the virtual multi-camera system. The problems to be solved in this paper are two-fold. The first problem is to identify to which mirror chamber each of the 2D projections of mirrored 3D points belongs. The second problem is to estimate all mirror parameters, i.e., normals, and distances of the mirrors. The key contribution of this paper is to propose novel algorithms for these problems using a single 3D point of unknown geometry by utilizing a kaleidoscopic projection constraint, which is an epipolar constraint on mirror reflections. We demonstrate the performance of the proposed algorithm of chamber assignment and estimation of mirror parameters with qualitative and quantitative evaluations using synthesized and real data.
Video Region Annotation with Sparse Bounding Boxes
Aug 17, 2020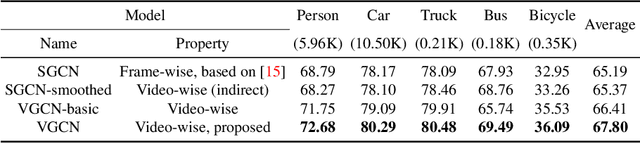
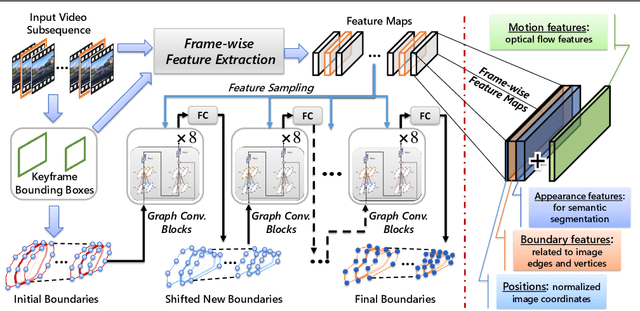
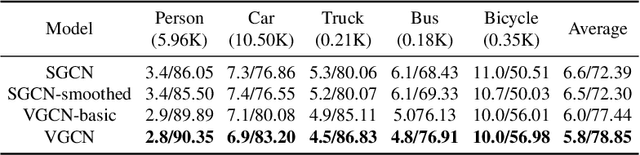
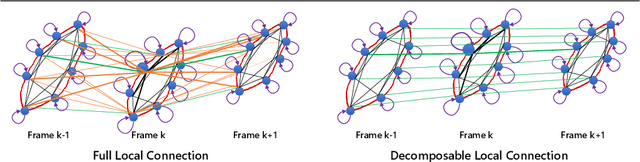
Video analysis has been moving towards more detailed interpretation (e.g. segmentation) with encouraging progresses. These tasks, however, increasingly rely on densely annotated training data both in space and time. Since such annotation is labour-intensive, few densely annotated video data with detailed region boundaries exist. This work aims to resolve this dilemma by learning to automatically generate region boundaries for all frames of a video from sparsely annotated bounding boxes of target regions. We achieve this with a Volumetric Graph Convolutional Network (VGCN), which learns to iteratively find keypoints on the region boundaries using the spatio-temporal volume of surrounding appearance and motion. The global optimization of VGCN makes it significantly stronger and generalize better than existing solutions. Experimental results using two latest datasets (one real and one synthetic), including ablation studies, demonstrate the effectiveness and superiority of our method.
Invertible Neural BRDF for Object Inverse Rendering
Aug 11, 2020
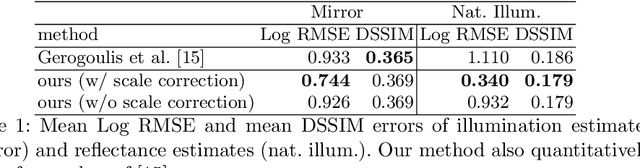

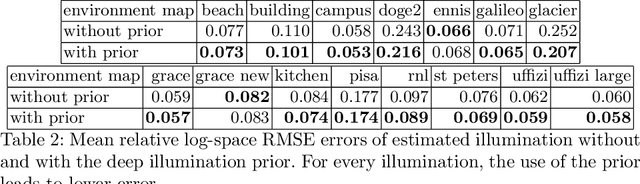
We introduce a novel neural network-based BRDF model and a Bayesian framework for object inverse rendering, i.e., joint estimation of reflectance and natural illumination from a single image of an object of known geometry. The BRDF is expressed with an invertible neural network, namely, normalizing flow, which provides the expressive power of a high-dimensional representation, computational simplicity of a compact analytical model, and physical plausibility of a real-world BRDF. We extract the latent space of real-world reflectance by conditioning this model, which directly results in a strong reflectance prior. We refer to this model as the invertible neural BRDF model (iBRDF). We also devise a deep illumination prior by leveraging the structural bias of deep neural networks. By integrating this novel BRDF model and reflectance and illumination priors in a MAP estimation formulation, we show that this joint estimation can be computed efficiently with stochastic gradient descent. We experimentally validate the accuracy of the invertible neural BRDF model on a large number of measured data and demonstrate its use in object inverse rendering on a number of synthetic and real images. The results show new ways in which deep neural networks can help solve challenging radiometric inverse problems.
SOIC: Semantic Online Initialization and Calibration for LiDAR and Camera
Mar 09, 2020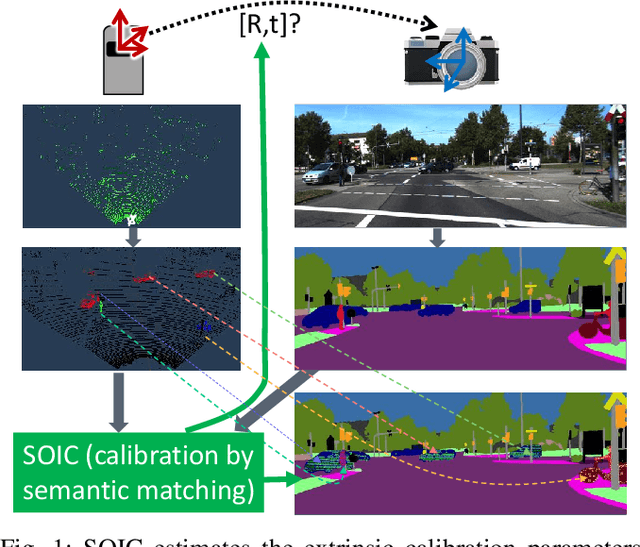
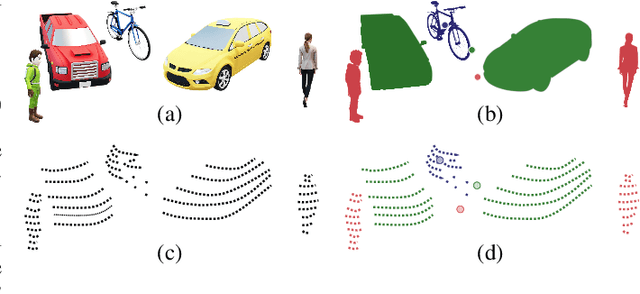
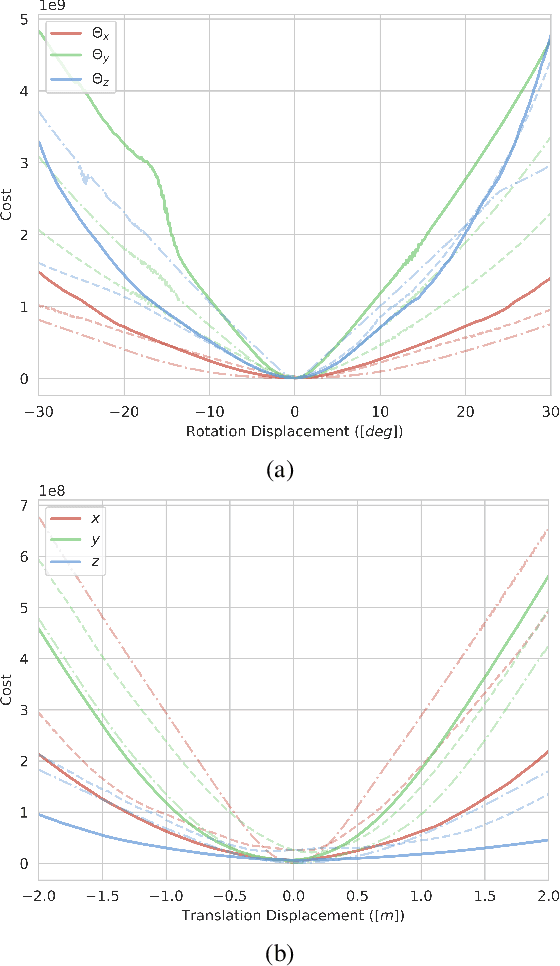
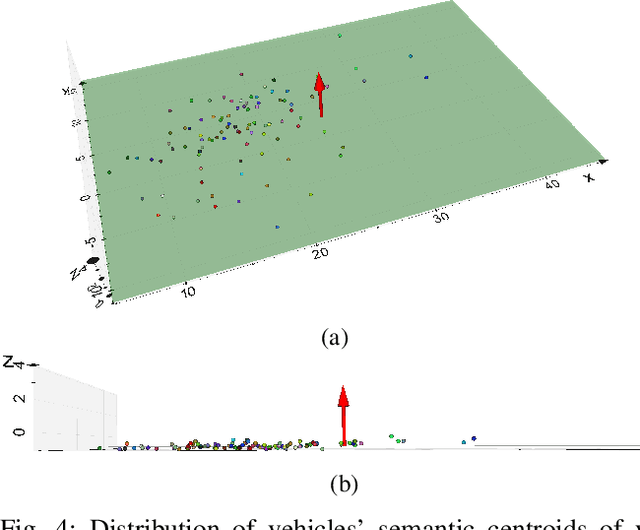
This paper presents a novel semantic-based online extrinsic calibration approach, SOIC (so, I see), for Light Detection and Ranging (LiDAR) and camera sensors. Previous online calibration methods usually need prior knowledge of rough initial values for optimization. The proposed approach removes this limitation by converting the initialization problem to a Perspective-n-Point (PnP) problem with the introduction of semantic centroids (SCs). The closed-form solution of this PnP problem has been well researched and can be found with existing PnP methods. Since the semantic centroid of the point cloud usually does not accurately match with that of the corresponding image, the accuracy of parameters are not improved even after a nonlinear refinement process. Thus, a cost function based on the constraint of the correspondence between semantic elements from both point cloud and image data is formulated. Subsequently, optimal extrinsic parameters are estimated by minimizing the cost function. We evaluate the proposed method either with GT or predicted semantics on KITTI dataset. Experimental results and comparisons with the baseline method verify the feasibility of the initialization strategy and the accuracy of the calibration approach. In addition, we release the source code at https://github.com/--/SOIC.
3D-GMNet: Learning to Estimate 3D Shape from A Single Image As A Gaussian Mixture
Dec 10, 2019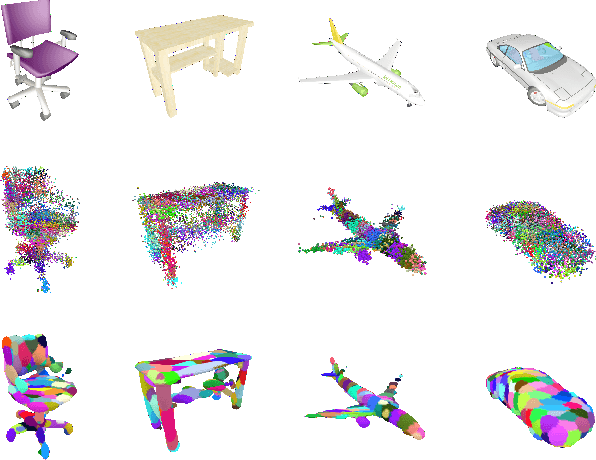

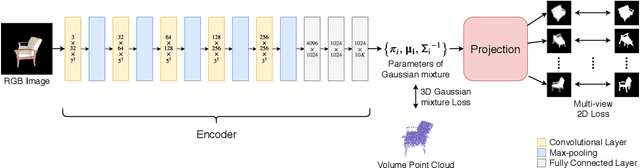

In this paper, we introduce 3D-GMNet, a deep neural network for single-image 3D shape recovery. As the name suggests, 3D-GMNet recovers 3D shape as a Gaussian mixture model. In contrast to voxels, point clouds, or meshes, a Gaussian mixture representation requires a much smaller footprint for representing 3D shapes and, at the same time, offers a number of additional advantages including instant pose estimation, automatic level-of-detail computation, and a distance measure. The proposed 3D-GMNet is trained end-to-end with single input images and corresponding 3D models by using two novel loss functions: a 3D Gaussian mixture loss and a multi-view 2D loss. The first maximizes the likelihood of the Gaussian mixture shape representation by considering the target point cloud as samples from the true distribution, and the latter improves the consistency between the input silhouette and the projection of the Gaussian mixture shape model. Extensive quantitative evaluations with synthesized and real images demonstrate the effectiveness of the proposed method.