 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregate vs. Personalized Judges in Business Idea Evaluation: Evidence from Expert Disagreement
Apr 24, 2026Evaluating LLM-generated business ideas is often harder to scale than generating them. Unlike standard NLP benchmarks, business idea evaluation relies on multi-dimensional criteria such as feasibility, novelty, differentiation, user need, and market size, and expert judgments often disagree. This paper studies a methodological question raised by such disagreement: should an automatic judge approximate an aggregate consensus, or model evaluators individually? We introduce PBIG-DATA, a dataset of approximately 3,000 individual scores across 300 patent-grounded product ideas, provided by domain experts on six business-oriented dimensions: specificity, technical validity, innovativeness, competitive advantage, need validity, and market size. Analyses show substantial expert disagreement on fine-grained ordinal scores, while agreement is higher under coarse selection, suggesting structured heterogeneity rather than random noise. We then compare three judge configurations: a rubric-only zero-shot judge, an aggregate judge conditioned on mixed evaluator histories, and a personalized judge conditioned on the target evaluator's scoring history. Across dimensions and model sizes, personalized judges align more closely with the corresponding evaluator than aggregate judges, and evaluator agreement correlates with similarity of judge-generated reasoning only under personalized conditioning. These results indicate that pooled labels can be a fragile target in pluralistic evaluation settings and motivate evaluator-conditioned judge designs for business idea assessment.
Pretraining and Updating Language- and Domain-specific Large Language Model: A Case Study in Japanese Business Domain
Apr 12, 2024



Several previous studies have considered language- and domain-specific large language models (LLMs) as separate topics. This study explores the combination of a non-English language and a high-demand industry domain, focusing on a Japanese business-specific LLM. This type of a model requires expertise in the business domain, strong language skills, and regular updates of its knowledge. We trained a 13-billion-parameter LLM from scratch using a new dataset of business texts and patents, and continually pretrained it with the latest business documents. Further we propose a new benchmark for Japanese business domain question answering (QA) and evaluate our models on it. The results show that our pretrained model improves QA accuracy without losing general knowledge, and that continual pretraining enhances adaptation to new information. Our pretrained model and business domain benchmark are publicly available.
Training Generative Question-Answering on Synthetic Data Obtained from an Instruct-tuned Model
Oct 13, 2023



This paper presents a simple and cost-effective method for synthesizing data to train question-answering systems. For training, fine-tuning GPT models is a common practice in resource-rich languages like English, however, it becomes challenging for non-English languages due to the scarcity of sufficient question-answer (QA) pairs. Existing approaches use question and answer generators trained on human-authored QA pairs, which involves substantial human expenses. In contrast, we use an instruct-tuned model to generate QA pairs in a zero-shot or few-shot manner. We conduct experiments to compare various strategies for obtaining QA pairs from the instruct-tuned model. The results demonstrate that a model trained on our proposed synthetic data achieves comparable performance to a model trained on manually curated datasets, without incurring human costs.
Structure of Multiple Mirror System from Kaleidoscopic Projections of Single 3D Point
Mar 29, 2021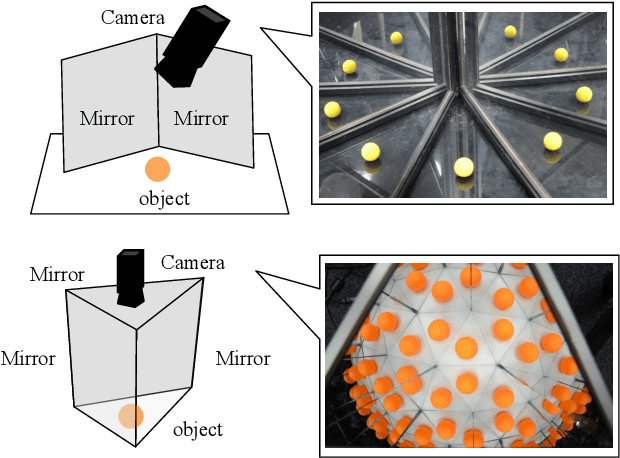
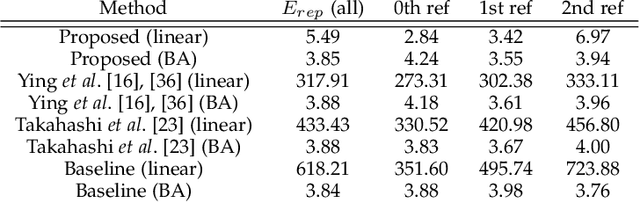
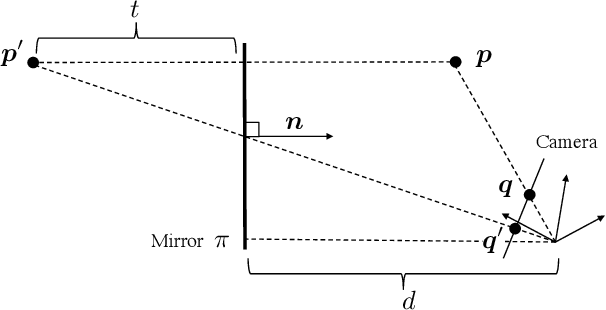
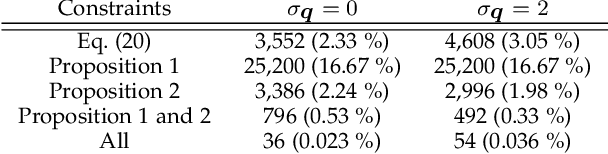
This paper proposes a novel algorithm of discovering the structure of a kaleidoscopic imaging system that consists of multiple planar mirrors and a camera. The kaleidoscopic imaging system can be recognized as the virtual multi-camera system and has strong advantages in that the virtual cameras are strictly synchronized and have the same intrinsic parameters. In this paper, we focus on the extrinsic calibration of the virtual multi-camera system. The problems to be solved in this paper are two-fold. The first problem is to identify to which mirror chamber each of the 2D projections of mirrored 3D points belongs. The second problem is to estimate all mirror parameters, i.e., normals, and distances of the mirrors. The key contribution of this paper is to propose novel algorithms for these problems using a single 3D point of unknown geometry by utilizing a kaleidoscopic projection constraint, which is an epipolar constraint on mirror reflections. We demonstrate the performance of the proposed algorithm of chamber assignment and estimation of mirror parameters with qualitative and quantitative evaluations using synthesized and real data.
A Linear Extrinsic Calibration of Kaleidoscopic Imaging System from Single 3D Point
May 27, 2017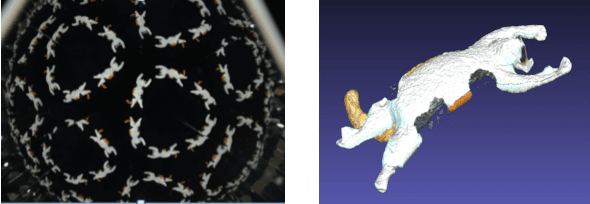
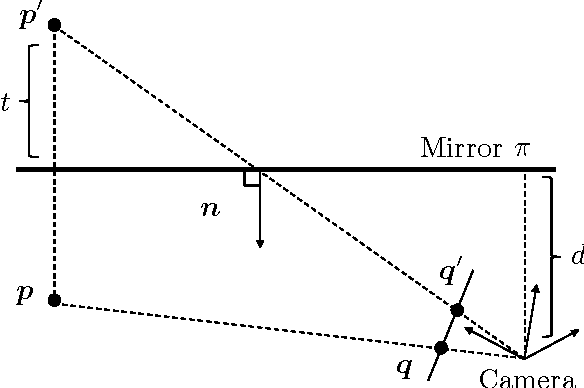
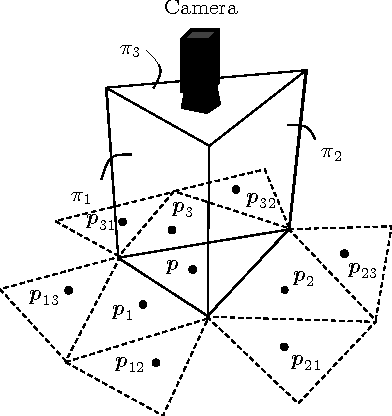
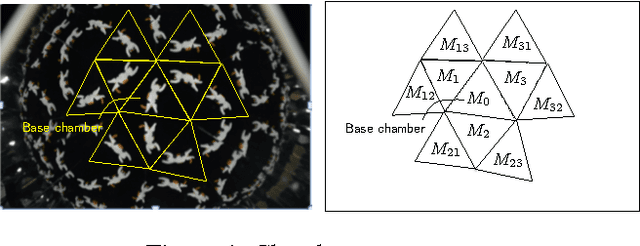
This paper proposes a new extrinsic calibration of kaleidoscopic imaging system by estimating normals and distances of the mirrors. The problem to be solved in this paper is a simultaneous estimation of all mirror parameters consistent throughout multiple reflections. Unlike conventional methods utilizing a pair of direct and mirrored images of a reference 3D object to estimate the parameters on a per-mirror basis, our method renders the simultaneous estimation problem into solving a linear set of equations. The key contribution of this paper is to introduce a linear estimation of multiple mirror parameters from kaleidoscopic 2D projections of a single 3D point of unknown geometry. Evaluations with synthesized and real images demonstrate the performance of the proposed algorithm in comparison with conventional methods.