 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoAERO: Learning Dexterous Manipulation from a Single Egocentric Video without Object Assets
Jun 06, 2026Egocentric RGB-D videos offer a natural source of human dexterous manipulation demonstrations, but existing data is difficult to use for robot learning because object pose, geometry, and contact information are often missing or require pre-scanned object assets. We present EgoAERO, the first framework that learns dexterous manipulation from a single egocentric RGB-D human demonstration without object assets. EgoAERO reconstructs contact-consistent hand-object trajectories through asset-free object tracking and reconstruction, ego motion compensation, and adaptive contact optimization, then converts them into robot policies using two-stage residual learning. We further introduce an online quality assessment mechanism and construct EgoDex-R, a large-scale egocentric dataset with 4.3M RGB-D frames for dexterous policy learning. Simulation and real-world experiments show that EgoAERO enables single-demonstration dexterous manipulation and achieves downstream performance close to CAD-based reconstructions on HOI4D.
Polymap: generating high definition map based on rasterized polygons
Nov 08, 2025The perception of high-definition maps is an integral component of environmental perception in autonomous driving systems. Existing research have often focused on online construction of high-definition maps. For instance, the Maptr[9] series employ a detection-based method to output vectorized map instances parallelly in an end-to-end manner. However, despite their capability for real-time construction, detection-based methods are observed to lack robust generalizability[19], which hampers their applicability in auto-labeling systems. Therefore, aiming to improve the generalizability, we reinterpret road elements as rasterized polygons and design a concise framework based on instance segmentation. Initially, a segmentation-based transformer is employed to deliver instance masks in an end-to-end manner; succeeding this step, a Potrace-based[17] post-processing module is used to ultimately yield vectorized map elements. Quantitative results attained on the Nuscene[1] dataset substantiate the effectiveness and generaliz-ability of our method.
Cost Volume Pyramid Network with Multi-strategies Range Searching for Multi-view Stereo
Jul 25, 2022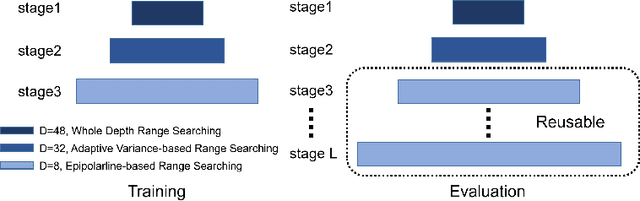
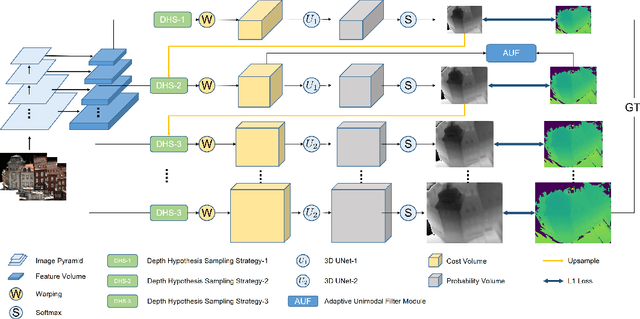
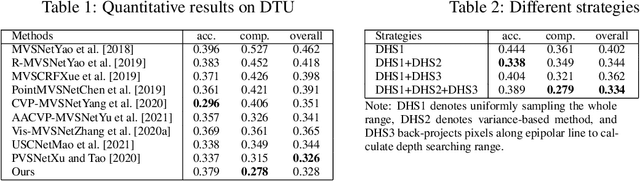
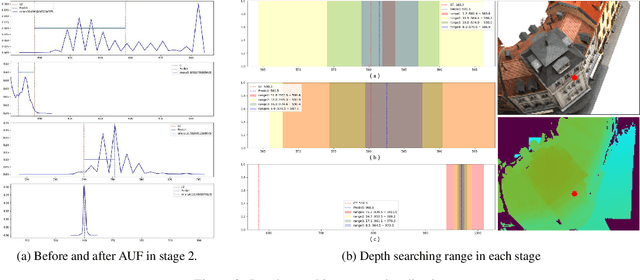
Multi-view stereo is an important research task in computer vision while still keeping challenging. In recent years, deep learning-based methods have shown superior performance on this task. Cost volume pyramid network-based methods which progressively refine depth map in coarse-to-fine manner, have yielded promising results while consuming less memory. However, these methods fail to take fully consideration of the characteristics of the cost volumes in each stage, leading to adopt similar range search strategies for each cost volume stage. In this work, we present a novel cost volume pyramid based network with different searching strategies for multi-view stereo. By choosing different depth range sampling strategies and applying adaptive unimodal filtering, we are able to obtain more accurate depth estimation in low resolution stages and iteratively upsample depth map to arbitrary resolution. We conducted extensive experiments on both DTU and BlendedMVS datasets, and results show that our method outperforms most state-of-the-art methods.