 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Speculative Decoding
Feb 02, 2024



Speculative Decoding is a widely used technique to speed up inference for Large Language Models (LLMs) without modifying its outcome. When performing inference on an LLM, speculative decoding uses a smaller draft model which generates speculative tokens and then uses the target LLM to verify those draft tokens. The speedup provided by speculative decoding heavily depends on the choice of the draft model. It has been widely suggested to select a draft model that provides a high probability of the generated token being accepted by the LLM to achieve the highest throughput. However, our experiments indicate the contrary with throughput diminishing as the probability of generated tokens to be accepted by the target model increases. To understand this phenomenon, we perform extensive experiments to characterize the different factors that affect speculative decoding and how those factors interact and affect the speedups. Based on our experiments we describe an analytical model which can be used to decide the right draft model for a given workload. Further, using our insights we design a new draft model for LLaMA-65B which can provide 30% higher throughput than existing draft models.
PolyThrottle: Energy-efficient Neural Network Inference on Edge Devices
Oct 30, 2023



As neural networks (NN) are deployed across diverse sectors, their energy demand correspondingly grows. While several prior works have focused on reducing energy consumption during training, the continuous operation of ML-powered systems leads to significant energy use during inference. This paper investigates how the configuration of on-device hardware-elements such as GPU, memory, and CPU frequency, often neglected in prior studies, affects energy consumption for NN inference with regular fine-tuning. We propose PolyThrottle, a solution that optimizes configurations across individual hardware components using Constrained Bayesian Optimization in an energy-conserving manner. Our empirical evaluation uncovers novel facets of the energy-performance equilibrium showing that we can save up to 36 percent of energy for popular models. We also validate that PolyThrottle can quickly converge towards near-optimal settings while satisfying application constraints.
Does compressing activations help model parallel training?
Jan 06, 2023Large-scale Transformer models are known for their exceptional performance in a range of tasks, but training them can be difficult due to the requirement for communication-intensive model parallelism. One way to improve training speed is to compress the message size in communication. Previous approaches have primarily focused on compressing gradients in a data parallelism setting, but compression in a model-parallel setting is an understudied area. We have discovered that model parallelism has fundamentally different characteristics than data parallelism. In this work, we present the first empirical study on the effectiveness of compression methods for model parallelism. We implement and evaluate three common classes of compression algorithms - pruning-based, learning-based, and quantization-based - using a popular Transformer training framework. We evaluate these methods across more than 160 settings and 8 popular datasets, taking into account different hyperparameters, hardware, and both fine-tuning and pre-training stages. We also provide analysis when the model is scaled up. Finally, we provide insights for future development of model parallelism compression algorithms.
BagPipe: Accelerating Deep Recommendation Model Training
Feb 24, 2022
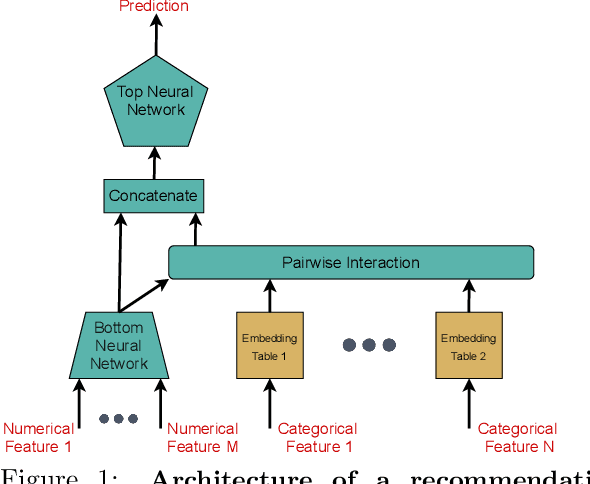
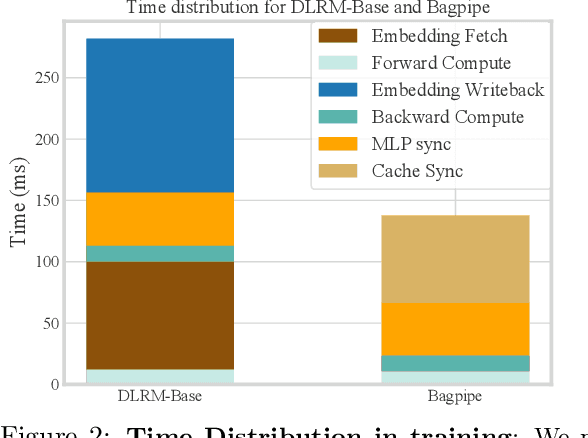
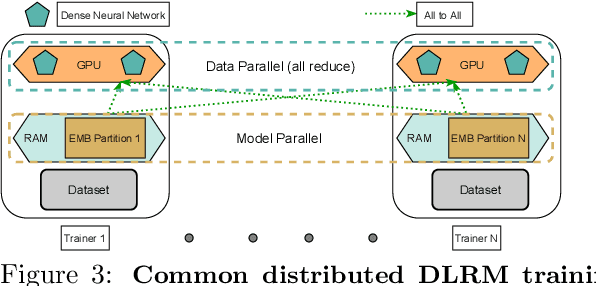
Deep learning based recommendation models (DLRM) are widely used in several business critical applications. Training such recommendation models efficiently is challenging primarily because they consist of billions of embedding-based parameters which are often stored remotely leading to significant overheads from embedding access. By profiling existing DLRM training, we observe that only 8.5% of the iteration time is spent in forward/backward pass while the remaining time is spent on embedding and model synchronization. Our key insight in this paper is that access to embeddings have a specific structure and pattern which can be used to accelerate training. We observe that embedding accesses are heavily skewed, with almost 1% of embeddings represent more than 92% of total accesses. Further, we observe that during training we can lookahead at future batches to determine exactly which embeddings will be needed at what iteration in the future. Based on these insight, we propose Bagpipe, a system for training deep recommendation models that uses caching and prefetching to overlap remote embedding accesses with the computation. We designed an Oracle Cacher, a new system component which uses our lookahead algorithm to generate optimal cache update decisions and provide strong consistency guarantees. Our experiments using three datasets and two models shows that our approach provides a speed up of up to 6.2x compared to state of the art baselines, while providing the same convergence and reproducibility guarantees as synchronous training.
Marius++: Large-Scale Training of Graph Neural Networks on a Single Machine
Feb 04, 2022
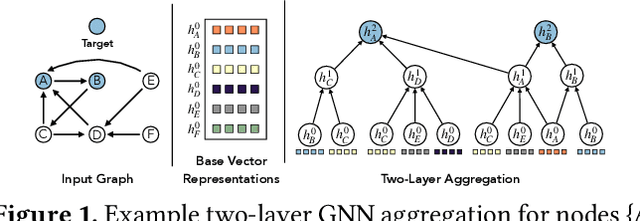
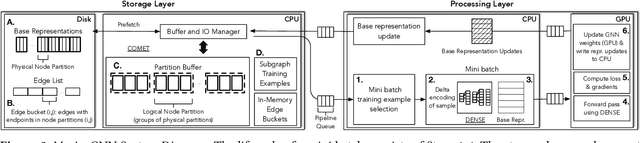
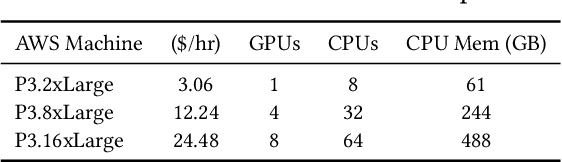
Graph Neural Networks (GNNs) have emerged as a powerful model for ML over graph-structured data. Yet, scalability remains a major challenge for using GNNs over billion-edge inputs. The creation of mini-batches used for training incurs computational and data movement costs that grow exponentially with the number of GNN layers as state-of-the-art models aggregate information from the multi-hop neighborhood of each input node. In this paper, we focus on scalable training of GNNs with emphasis on resource efficiency. We show that out-of-core pipelined mini-batch training in a single machine outperforms resource-hungry multi-GPU solutions. We introduce Marius++, a system for training GNNs over billion-scale graphs. Marius++ provides disk-optimized training for GNNs and introduces a series of data organization and algorithmic contributions that 1) minimize the memory-footprint and end-to-end time required for training and 2) ensure that models learned with disk-based training exhibit accuracy similar to those fully trained in mixed CPU/GPU settings. We evaluate Marius++ against PyTorch Geometric and Deep Graph Library using seven benchmark (model, data set) settings and find that Marius++ with one GPU can achieve the same level of model accuracy up to 8$\times$ faster than these systems when they are using up to eight GPUs. For these experiments, disk-based training allows Marius++ deployments to be up to 64$\times$ cheaper in monetary cost than those of the competing systems.
Doing More by Doing Less: How Structured Partial Backpropagation Improves Deep Learning Clusters
Nov 20, 2021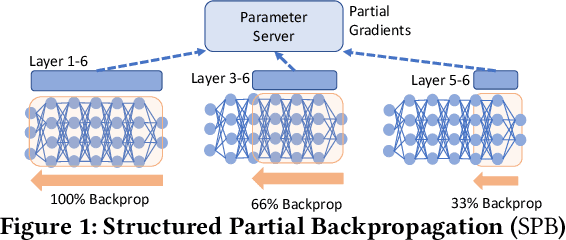
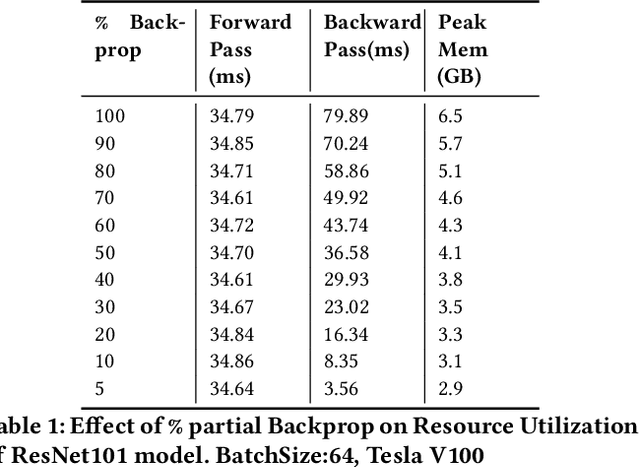
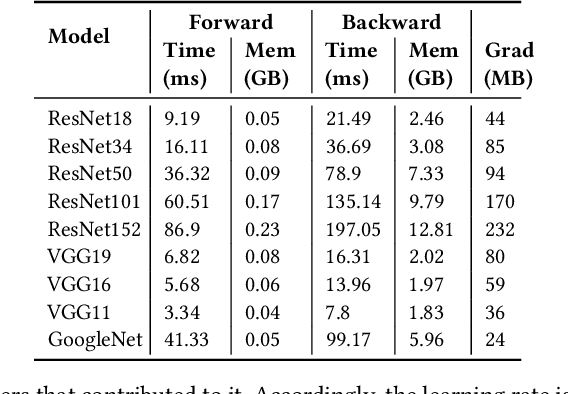
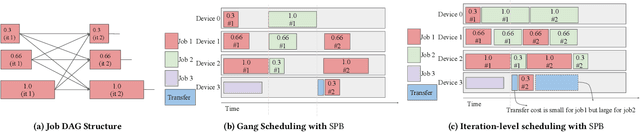
Many organizations employ compute clusters equipped with accelerators such as GPUs and TPUs for training deep learning models in a distributed fashion. Training is resource-intensive, consuming significant compute, memory, and network resources. Many prior works explore how to reduce training resource footprint without impacting quality, but their focus on a subset of the bottlenecks (typically only the network) limits their ability to improve overall cluster utilization. In this work, we exploit the unique characteristics of deep learning workloads to propose Structured Partial Backpropagation(SPB), a technique that systematically controls the amount of backpropagation at individual workers in distributed training. This simultaneously reduces network bandwidth, compute utilization, and memory footprint while preserving model quality. To efficiently leverage the benefits of SPB at cluster level, we introduce JigSaw, a SPB aware scheduler, which does scheduling at the iteration level for Deep Learning Training(DLT) jobs. We find that JigSaw can improve large scale cluster efficiency by as high as 28\%.
KAISA: An Adaptive Second-order Optimizer Framework for Deep Neural Networks
Jul 04, 2021



Kronecker-factored Approximate Curvature (K-FAC) has recently been shown to converge faster in deep neural network (DNN) training than stochastic gradient descent (SGD); however, K-FAC's larger memory footprint hinders its applicability to large models. We present KAISA, a K-FAC-enabled, Adaptable, Improved, and ScAlable second-order optimizer framework that adapts the memory footprint, communication, and computation given specific models and hardware to achieve maximized performance and enhanced scalability. We quantify the tradeoffs between memory and communication cost and evaluate KAISA on large models, including ResNet-50, Mask R-CNN, U-Net, and BERT, on up to 128 NVIDIA A100 GPUs. Compared to the original optimizers, KAISA converges 18.1-36.3% faster across applications with the same global batch size. Under a fixed memory budget, KAISA converges 32.5% and 41.6% faster in ResNet-50 and BERT-Large, respectively. KAISA can balance memory and communication to achieve scaling efficiency equal to or better than the baseline optimizers.
On the Utility of Gradient Compression in Distributed Training Systems
Mar 03, 2021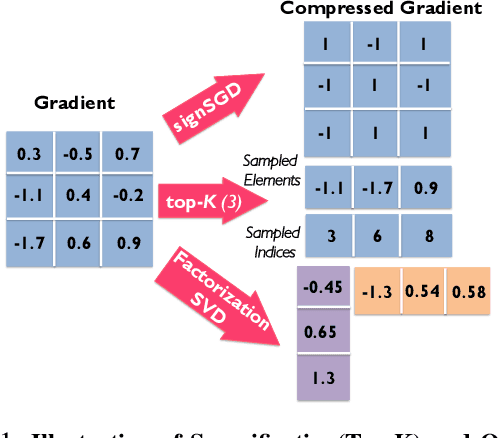


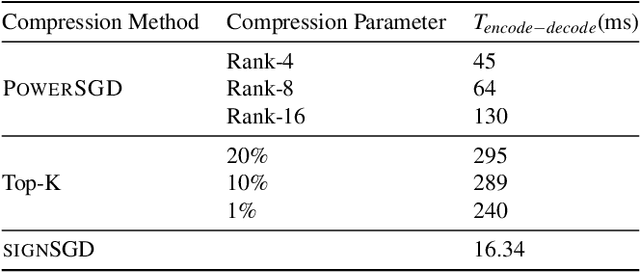
Rapid growth in data sets and the scale of neural network architectures have rendered distributed training a necessity. A rich body of prior work has highlighted the existence of communication bottlenecks in synchronous data-parallel training. To alleviate these bottlenecks, the machine learning community has largely focused on developing gradient and model compression methods. In parallel, the systems community has adopted several High Performance Computing (HPC)techniques to speed up distributed training. In this work, we evaluate the efficacy of gradient compression methods and compare their scalability with optimized implementations of synchronous data-parallel SGD. Surprisingly, we observe that due to computation overheads introduced by gradient compression, the net speedup over vanilla data-parallel training is marginal, if not negative. We conduct an extensive investigation to identify the root causes of this phenomenon, and offer a performance model that can be used to identify the benefits of gradient compression for a variety of system setups. Based on our analysis, we propose a list of desirable properties that gradient compression methods should satisfy, in order for them to provide a meaningful end-to-end speedup
AutoFreeze: Automatically Freezing Model Blocks to Accelerate Fine-tuning
Feb 02, 2021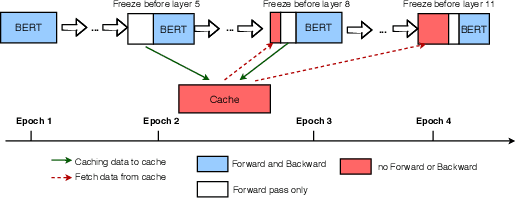
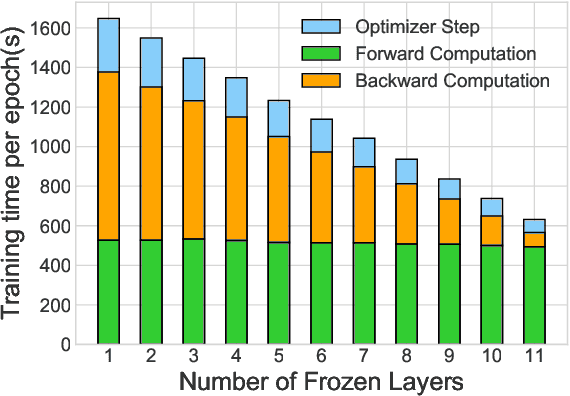
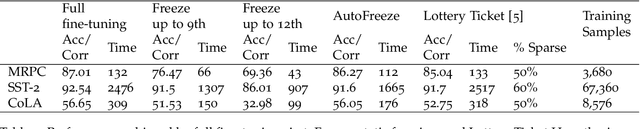
With the rapid adoption of machine learning (ML), a number of domains now use the approach of fine-tuning models pre-trained on a large corpus of data. However, our experiments show that even fine-tuning on models like BERT can take many hours when using GPUs. While prior work proposes limiting the number of layers that are fine-tuned, e.g., freezing all layers but the last layer, we find that such static approaches lead to reduced accuracy. We propose, AutoFreeze, a system that uses an adaptive approach to choose which layers are trained and show how this can accelerate model fine-tuning while preserving accuracy. We also develop mechanisms to enable efficient caching of intermediate activations which can reduce the forward computation time when performing fine-tuning. Our evaluation on fourNLP tasks shows that AutoFreeze, with caching enabled, can improve fine-tuning performance by up to 2.55x.
Learning Massive Graph Embeddings on a Single Machine
Jan 20, 2021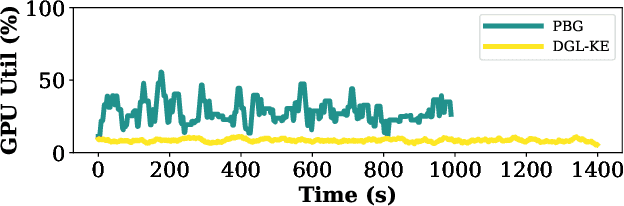

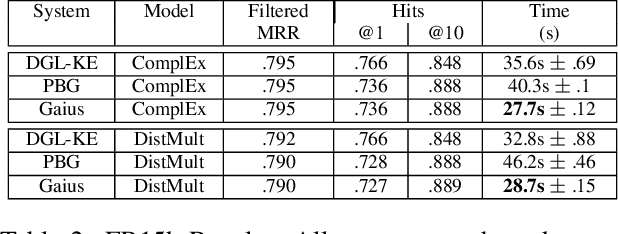
We propose a new framework for computing the embeddings of large-scale graphs on a single machine. A graph embedding is a fixed length vector representation for each node (and/or edge-type) in a graph and has emerged as the de-facto approach to apply modern machine learning on graphs. We identify that current systems for learning the embeddings of large-scale graphs are bottlenecked by data movement, which results in poor resource utilization and inefficient training. These limitations require state-of-the-art systems to distribute training across multiple machines. We propose Gaius, a system for efficient training of graph embeddings that leverages partition caching and buffer-aware data orderings to minimize disk access and interleaves data movement with computation to maximize utilization. We compare Gaius against two state-of-the-art industrial systems on a diverse array of benchmarks. We demonstrate that Gaius achieves the same level of accuracy but is up to one order-of magnitude faster. We also show that Gaius can scale training to datasets an order of magnitude beyond a single machine's GPU and CPU memory capacity, enabling training of configurations with more than a billion edges and 550GB of total parameters on a single AWS P3.2xLarge instance.