 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMEX: Detecting Explanatory Evidence for Memes via Knowledge-Enriched Contextualization
May 25, 2023



Memes are a powerful tool for communication over social media. Their affinity for evolving across politics, history, and sociocultural phenomena makes them an ideal communication vehicle. To comprehend the subtle message conveyed within a meme, one must understand the background that facilitates its holistic assimilation. Besides digital archiving of memes and their metadata by a few websites like knowyourmeme.com, currently, there is no efficient way to deduce a meme's context dynamically. In this work, we propose a novel task, MEMEX - given a meme and a related document, the aim is to mine the context that succinctly explains the background of the meme. At first, we develop MCC (Meme Context Corpus), a novel dataset for MEMEX. Further, to benchmark MCC, we propose MIME (MultImodal Meme Explainer), a multimodal neural framework that uses common sense enriched meme representation and a layered approach to capture the cross-modal semantic dependencies between the meme and the context. MIME surpasses several unimodal and multimodal systems and yields an absolute improvement of ~ 4% F1-score over the best baseline. Lastly, we conduct detailed analyses of MIME's performance, highlighting the aspects that could lead to optimal modeling of cross-modal contextual associations.
Characterizing the Entities in Harmful Memes: Who is the Hero, the Villain, the Victim?
Jan 26, 2023



Memes can sway people's opinions over social media as they combine visual and textual information in an easy-to-consume manner. Since memes instantly turn viral, it becomes crucial to infer their intent and potentially associated harmfulness to take timely measures as needed. A common problem associated with meme comprehension lies in detecting the entities referenced and characterizing the role of each of these entities. Here, we aim to understand whether the meme glorifies, vilifies, or victimizes each entity it refers to. To this end, we address the task of role identification of entities in harmful memes, i.e., detecting who is the 'hero', the 'villain', and the 'victim' in the meme, if any. We utilize HVVMemes - a memes dataset on US Politics and Covid-19 memes, released recently as part of the CONSTRAINT@ACL-2022 shared-task. It contains memes, entities referenced, and their associated roles: hero, villain, victim, and other. We further design VECTOR (Visual-semantic role dEteCToR), a robust multi-modal framework for the task, which integrates entity-based contextual information in the multi-modal representation and compare it to several standard unimodal (text-only or image-only) or multi-modal (image+text) models. Our experimental results show that our proposed model achieves an improvement of 4% over the best baseline and 1% over the best competing stand-alone submission from the shared-task. Besides divulging an extensive experimental setup with comparative analyses, we finally highlight the challenges encountered in addressing the complex task of semantic role labeling within memes.
Quantum-Inspired Tensor Neural Networks for Option Pricing
Dec 28, 2022



Recent advances in deep learning have enabled us to address the curse of dimensionality (COD) by solving problems in higher dimensions. A subset of such approaches of addressing the COD has led us to solving high-dimensional PDEs. This has resulted in opening doors to solving a variety of real-world problems ranging from mathematical finance to stochastic control for industrial applications. Although feasible, these deep learning methods are still constrained by training time and memory. Tackling these shortcomings, Tensor Neural Networks (TNN) demonstrate that they can provide significant parameter savings while attaining the same accuracy as compared to the classical Dense Neural Network (DNN). In addition, we also show how TNN can be trained faster than DNN for the same accuracy. Besides TNN, we also introduce Tensor Network Initializer (TNN Init), a weight initialization scheme that leads to faster convergence with smaller variance for an equivalent parameter count as compared to a DNN. We benchmark TNN and TNN Init by applying them to solve the parabolic PDE associated with the Heston model, which is widely used in financial pricing theory.
What do you MEME? Generating Explanations for Visual Semantic Role Labelling in Memes
Dec 20, 2022



Memes are powerful means for effective communication on social media. Their effortless amalgamation of viral visuals and compelling messages can have far-reaching implications with proper marketing. Previous research on memes has primarily focused on characterizing their affective spectrum and detecting whether the meme's message insinuates any intended harm, such as hate, offense, racism, etc. However, memes often use abstraction, which can be elusive. Here, we introduce a novel task - EXCLAIM, generating explanations for visual semantic role labeling in memes. To this end, we curate ExHVV, a novel dataset that offers natural language explanations of connotative roles for three types of entities - heroes, villains, and victims, encompassing 4,680 entities present in 3K memes. We also benchmark ExHVV with several strong unimodal and multimodal baselines. Moreover, we posit LUMEN, a novel multimodal, multi-task learning framework that endeavors to address EXCLAIM optimally by jointly learning to predict the correct semantic roles and correspondingly to generate suitable natural language explanations. LUMEN distinctly outperforms the best baseline across 18 standard natural language generation evaluation metrics. Our systematic evaluation and analyses demonstrate that characteristic multimodal cues required for adjudicating semantic roles are also helpful for generating suitable explanations.
Domain-aware Self-supervised Pre-training for Label-Efficient Meme Analysis
Sep 29, 2022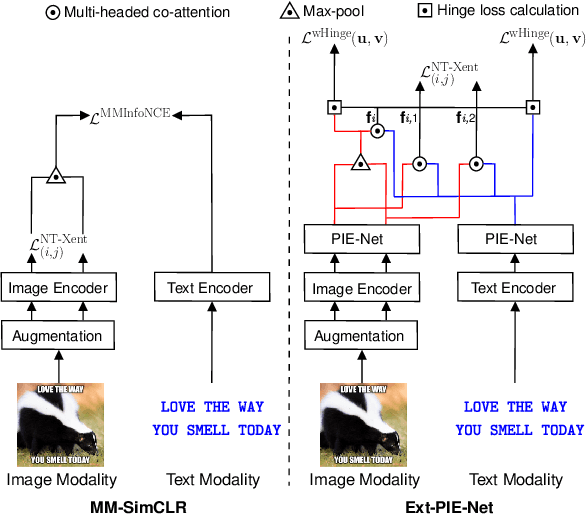

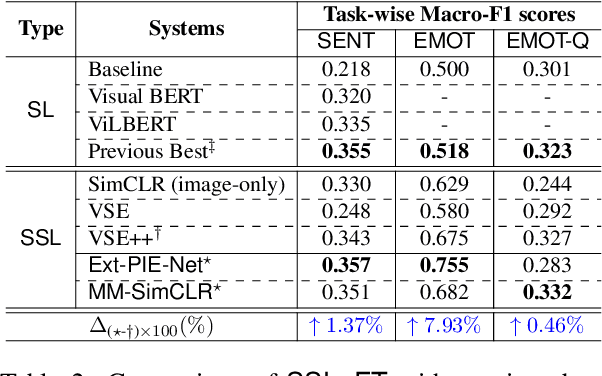
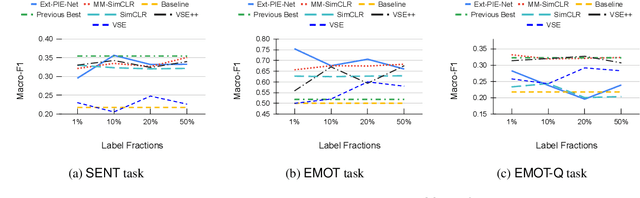
Existing self-supervised learning strategies are constrained to either a limited set of objectives or generic downstream tasks that predominantly target uni-modal applications. This has isolated progress for imperative multi-modal applications that are diverse in terms of complexity and domain-affinity, such as meme analysis. Here, we introduce two self-supervised pre-training methods, namely Ext-PIE-Net and MM-SimCLR that (i) employ off-the-shelf multi-modal hate-speech data during pre-training and (ii) perform self-supervised learning by incorporating multiple specialized pretext tasks, effectively catering to the required complex multi-modal representation learning for meme analysis. We experiment with different self-supervision strategies, including potential variants that could help learn rich cross-modality representations and evaluate using popular linear probing on the Hateful Memes task. The proposed solutions strongly compete with the fully supervised baseline via label-efficient training while distinctly outperforming them on all three tasks of the Memotion challenge with 0.18%, 23.64%, and 0.93% performance gain, respectively. Further, we demonstrate the generalizability of the proposed solutions by reporting competitive performance on the HarMeme task. Finally, we empirically establish the quality of the learned representations by analyzing task-specific learning, using fewer labeled training samples, and arguing that the complexity of the self-supervision strategy and downstream task at hand are correlated. Our efforts highlight the requirement of better multi-modal self-supervision methods involving specialized pretext tasks for efficient fine-tuning and generalizable performance.
Quantum-Inspired Tensor Neural Networks for Partial Differential Equations
Aug 10, 2022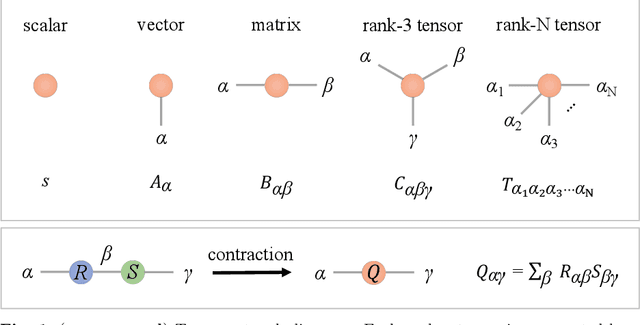
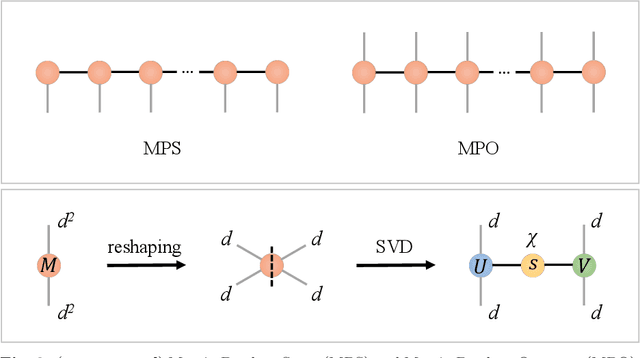
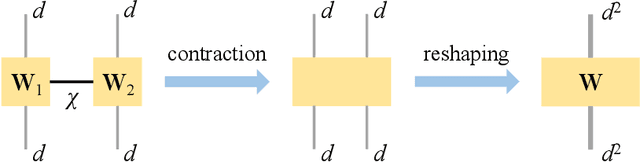
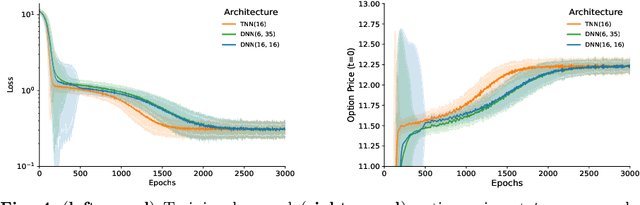
Partial Differential Equations (PDEs) are used to model a variety of dynamical systems in science and engineering. Recent advances in deep learning have enabled us to solve them in a higher dimension by addressing the curse of dimensionality in new ways. However, deep learning methods are constrained by training time and memory. To tackle these shortcomings, we implement Tensor Neural Networks (TNN), a quantum-inspired neural network architecture that leverages Tensor Network ideas to improve upon deep learning approaches. We demonstrate that TNN provide significant parameter savings while attaining the same accuracy as compared to the classical Dense Neural Network (DNN). In addition, we also show how TNN can be trained faster than DNN for the same accuracy. We benchmark TNN by applying them to solve parabolic PDEs, specifically the Black-Scholes-Barenblatt equation, widely used in financial pricing theory, empirically showing the advantages of TNN over DNN. Further examples, such as the Hamilton-Jacobi-Bellman equation, are also discussed.
DISARM: Detecting the Victims Targeted by Harmful Memes
May 11, 2022
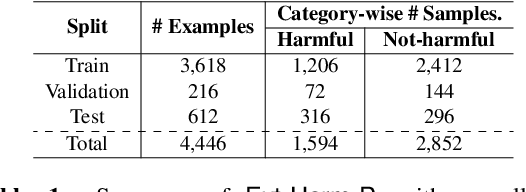

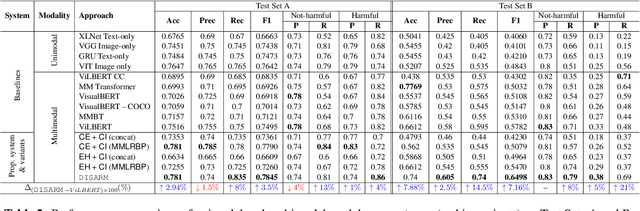
Internet memes have emerged as an increasingly popular means of communication on the Web. Although typically intended to elicit humour, they have been increasingly used to spread hatred, trolling, and cyberbullying, as well as to target specific individuals, communities, or society on political, socio-cultural, and psychological grounds. While previous work has focused on detecting harmful, hateful, and offensive memes, identifying whom they attack remains a challenging and underexplored area. Here we aim to bridge this gap. In particular, we create a dataset where we annotate each meme with its victim(s) such as the name of the targeted person(s), organization(s), and community(ies). We then propose DISARM (Detecting vIctimS targeted by hARmful Memes), a framework that uses named entity recognition and person identification to detect all entities a meme is referring to, and then, incorporates a novel contextualized multimodal deep neural network to classify whether the meme intends to harm these entities. We perform several systematic experiments on three test setups, corresponding to entities that are (a) all seen while training, (b) not seen as a harmful target on training, and (c) not seen at all on training. The evaluation results show that DISARM significantly outperforms ten unimodal and multimodal systems. Finally, we show that DISARM is interpretable and comparatively more generalizable and that it can reduce the relative error rate for harmful target identification by up to 9 points absolute over several strong multimodal rivals.
Detecting and Understanding Harmful Memes: A Survey
May 09, 2022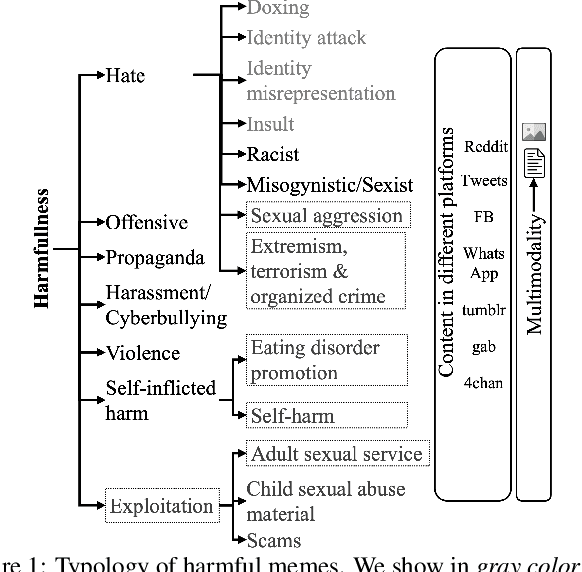
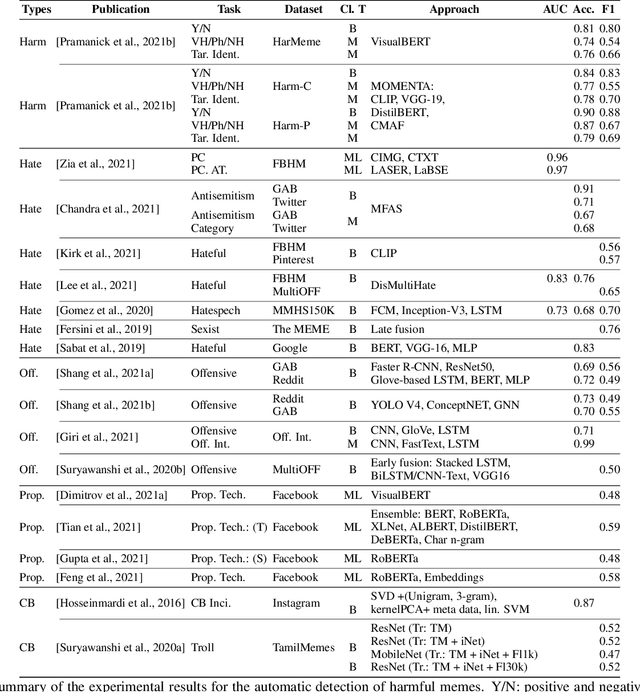

The automatic identification of harmful content online is of major concern for social media platforms, policymakers, and society. Researchers have studied textual, visual, and audio content, but typically in isolation. Yet, harmful content often combines multiple modalities, as in the case of memes, which are of particular interest due to their viral nature. With this in mind, here we offer a comprehensive survey with a focus on harmful memes. Based on a systematic analysis of recent literature, we first propose a new typology of harmful memes, and then we highlight and summarize the relevant state of the art. One interesting finding is that many types of harmful memes are not really studied, e.g., such featuring self-harm and extremism, partly due to the lack of suitable datasets. We further find that existing datasets mostly capture multi-class scenarios, which are not inclusive of the affective spectrum that memes can represent. Another observation is that memes can propagate globally through repackaging in different languages and that they can also be multilingual, blending different cultures. We conclude by highlighting several challenges related to multimodal semiotics, technological constraints and non-trivial social engagement, and we present several open-ended aspects such as delineating online harm and empirically examining related frameworks and assistive interventions, which we believe will motivate and drive future research.
EXPERT: Public Benchmarks for Dynamic Heterogeneous Academic Graphs
Apr 14, 2022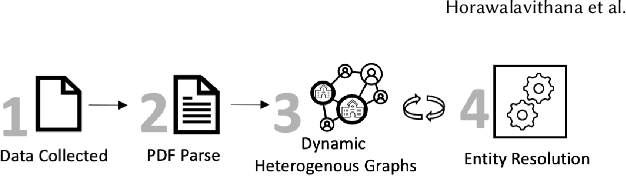
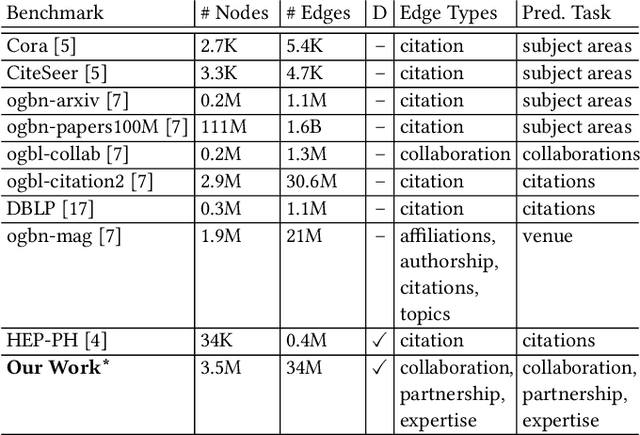

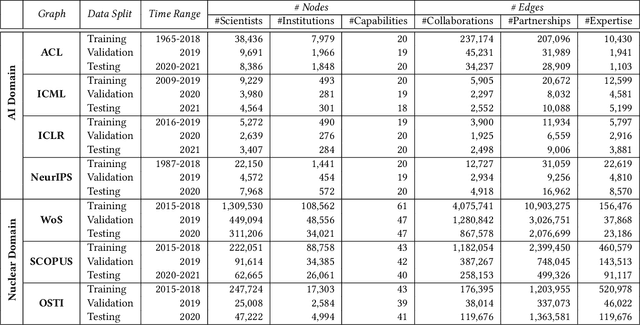
Machine learning models that learn from dynamic graphs face nontrivial challenges in learning and inference as both nodes and edges change over time. The existing large-scale graph benchmark datasets that are widely used by the community primarily focus on homogeneous node and edge attributes and are static. In this work, we present a variety of large scale, dynamic heterogeneous academic graphs to test the effectiveness of models developed for multi-step graph forecasting tasks. Our novel datasets cover both context and content information extracted from scientific publications across two communities: Artificial Intelligence (AI) and Nuclear Nonproliferation (NN). In addition, we propose a systematic approach to improve the existing evaluation procedures used in the graph forecasting models.
Detecting Harmful Memes and Their Targets
Sep 24, 2021
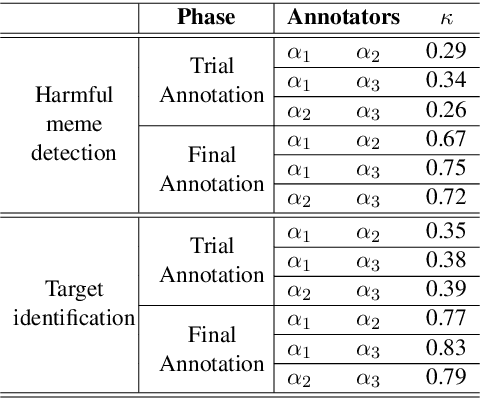
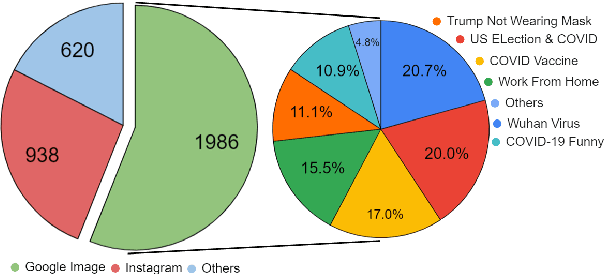

Among the various modes of communication in social media, the use of Internet memes has emerged as a powerful means to convey political, psychological, and socio-cultural opinions. Although memes are typically humorous in nature, recent days have witnessed a proliferation of harmful memes targeted to abuse various social entities. As most harmful memes are highly satirical and abstruse without appropriate contexts, off-the-shelf multimodal models may not be adequate to understand their underlying semantics. In this work, we propose two novel problem formulations: detecting harmful memes and the social entities that these harmful memes target. To this end, we present HarMeme, the first benchmark dataset, containing 3,544 memes related to COVID-19. Each meme went through a rigorous two-stage annotation process. In the first stage, we labeled a meme as very harmful, partially harmful, or harmless; in the second stage, we further annotated the type of target(s) that each harmful meme points to: individual, organization, community, or society/general public/other. The evaluation results using ten unimodal and multimodal models highlight the importance of using multimodal signals for both tasks. We further discuss the limitations of these models and we argue that more research is needed to address these problems.
* harmful memes, multimodality, social media