 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular relaxation by reverse diffusion with time step prediction
Apr 16, 2024



Molecular relaxation, finding the equilibrium state of a non-equilibrium structure, is an essential component of computational chemistry to understand reactivity. Classical force field methods often rely on insufficient local energy minimization, while neural network force field models require large labeled datasets encompassing both equilibrium and non-equilibrium structures. As a remedy, we propose MoreRed, molecular relaxation by reverse diffusion, a conceptually novel and purely statistical approach where non-equilibrium structures are treated as noisy instances of their corresponding equilibrium states. To enable the denoising of arbitrarily noisy inputs via a generative diffusion model, we further introduce a novel diffusion time step predictor. Notably, MoreRed learns a simpler pseudo potential energy surface instead of the complex physical potential energy surface. It is trained on a significantly smaller, and thus computationally cheaper, dataset consisting of solely unlabeled equilibrium structures, avoiding the computation of non-equilibrium structures altogether. We compare MoreRed to classical force fields, equivariant neural network force fields trained on a large dataset of equilibrium and non-equilibrium data, as well as a semi-empirical tight-binding model. To assess this quantitatively, we evaluate the root-mean-square deviation between the found equilibrium structures and the reference equilibrium structures as well as their DFT energies.
Solution Simplex Clustering for Heterogeneous Federated Learning
Mar 05, 2024We tackle a major challenge in federated learning (FL) -- achieving good performance under highly heterogeneous client distributions. The difficulty partially arises from two seemingly contradictory goals: learning a common model by aggregating the information from clients, and learning local personalized models that should be adapted to each local distribution. In this work, we propose Solution Simplex Clustered Federated Learning (SosicFL) for dissolving such contradiction. Based on the recent ideas of learning solution simplices, SosicFL assigns a subregion in a simplex to each client, and performs FL to learn a common solution simplex. This allows the client models to possess their characteristics within the degrees of freedom in the solution simplex, and at the same time achieves the goal of learning a global common model. Our experiments show that SosicFL improves the performance and accelerates the training process for global and personalized FL with minimal computational overhead.
Labeling Neural Representations with Inverse Recognition
Nov 22, 2023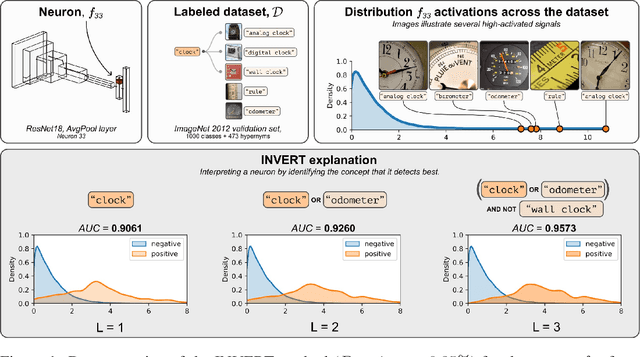

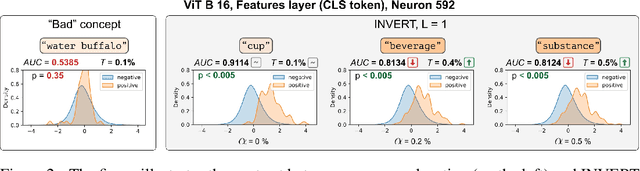
Deep Neural Networks (DNNs) demonstrated remarkable capabilities in learning complex hierarchical data representations, but the nature of these representations remains largely unknown. Existing global explainability methods, such as Network Dissection, face limitations such as reliance on segmentation masks, lack of statistical significance testing, and high computational demands. We propose Inverse Recognition (INVERT), a scalable approach for connecting learned representations with human-understandable concepts by leveraging their capacity to discriminate between these concepts. In contrast to prior work, INVERT is capable of handling diverse types of neurons, exhibits less computational complexity, and does not rely on the availability of segmentation masks. Moreover, INVERT provides an interpretable metric assessing the alignment between the representation and its corresponding explanation and delivering a measure of statistical significance, emphasizing its utility and credibility. We demonstrate the applicability of INVERT in various scenarios, including the identification of representations affected by spurious correlations, and the interpretation of the hierarchical structure of decision-making within the models.
* 24 pages, 16 figures
Generative Fractional Diffusion Models
Oct 26, 2023



We generalize the continuous time framework for score-based generative models from an underlying Brownian motion (BM) to an approximation of fractional Brownian motion (FBM). We derive a continuous reparameterization trick and the reverse time model by representing FBM as a stochastic integral over a family of Ornstein-Uhlenbeck processes to define generative fractional diffusion models (GFDM) with driving noise converging to a non-Markovian process of infinite quadratic variation. The Hurst index $H\in(0,1)$ of FBM enables control of the roughness of the distribution transforming path. To the best of our knowledge, this is the first attempt to build a generative model upon a stochastic process with infinite quadratic variation.
Detecting and Mitigating Mode-Collapse for Flow-based Sampling of Lattice Field Theories
Feb 27, 2023



We study the consequences of mode-collapse of normalizing flows in the context of lattice field theory. Normalizing flows allow for independent sampling. For this reason, it is hoped that they can avoid the tunneling problem of local-update MCMC algorithms for multi-modal distributions. In this work, we first point out that the tunneling problem is also present for normalizing flows but is shifted from the sampling to the training phase of the algorithm. Specifically, normalizing flows often suffer from mode-collapse for which the training process assigns vanishingly low probability mass to relevant modes of the physical distribution. This may result in a significant bias when the flow is used as a sampler in a Markov-Chain or with Importance Sampling. We propose a metric to quantify the degree of mode-collapse and derive a bound on the resulting bias. Furthermore, we propose various mitigation strategies in particular in the context of estimating thermodynamic observables, such as the free energy.
Domain-Specific Word Embeddings with Structure Prediction
Oct 06, 2022
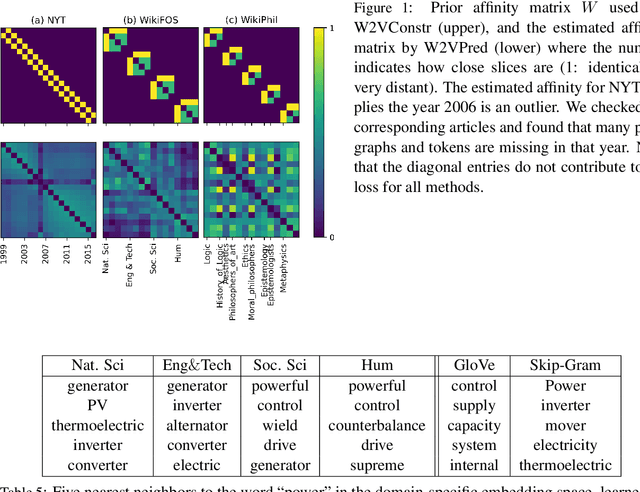
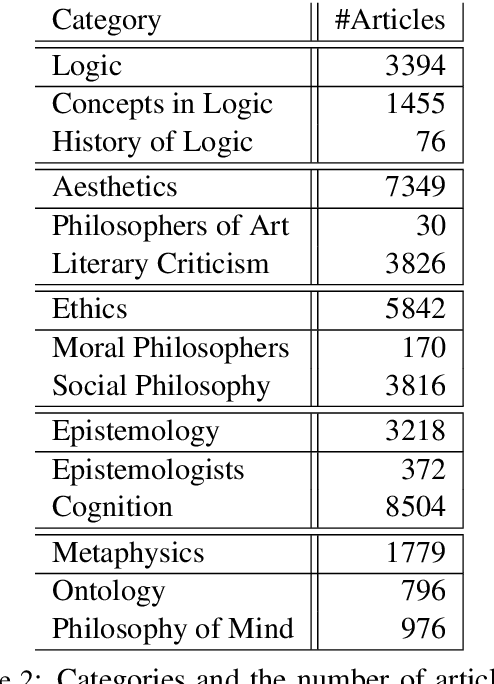
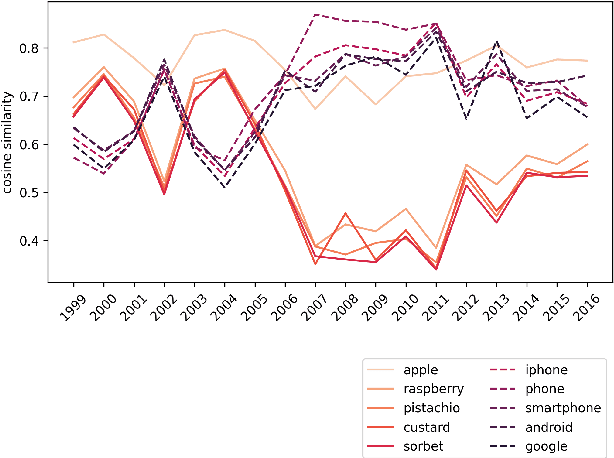
Complementary to finding good general word embeddings, an important question for representation learning is to find dynamic word embeddings, e.g., across time or domain. Current methods do not offer a way to use or predict information on structure between sub-corpora, time or domain and dynamic embeddings can only be compared after post-alignment. We propose novel word embedding methods that provide general word representations for the whole corpus, domain-specific representations for each sub-corpus, sub-corpus structure, and embedding alignment simultaneously. We present an empirical evaluation on New York Times articles and two English Wikipedia datasets with articles on science and philosophy. Our method, called Word2Vec with Structure Prediction (W2VPred), provides better performance than baselines in terms of the general analogy tests, domain-specific analogy tests, and multiple specific word embedding evaluations as well as structure prediction performance when no structure is given a priori. As a use case in the field of Digital Humanities we demonstrate how to raise novel research questions for high literature from the German Text Archive.
Gradients should stay on Path: Better Estimators of the Reverse- and Forward KL Divergence for Normalizing Flows
Jul 17, 2022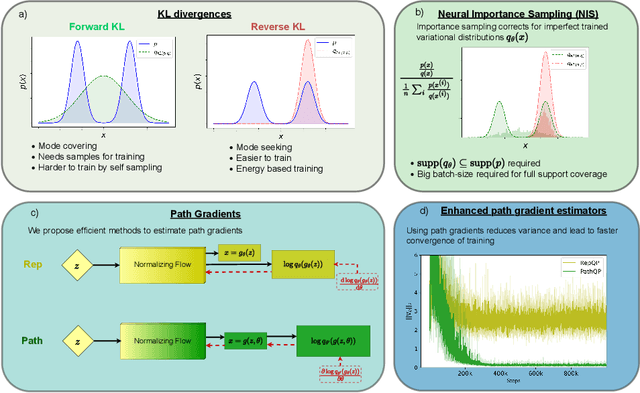
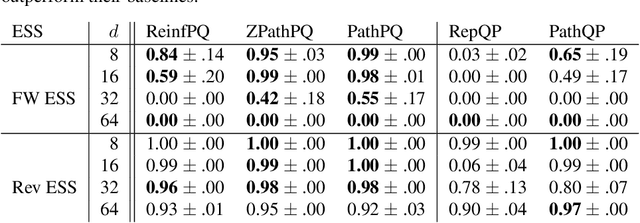
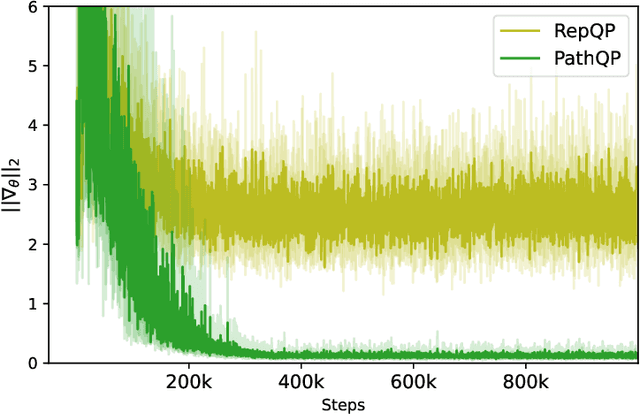
We propose an algorithm to estimate the path-gradient of both the reverse and forward Kullback-Leibler divergence for an arbitrary manifestly invertible normalizing flow. The resulting path-gradient estimators are straightforward to implement, have lower variance, and lead not only to faster convergence of training but also to better overall approximation results compared to standard total gradient estimators. We also demonstrate that path-gradient training is less susceptible to mode-collapse. In light of our results, we expect that path-gradient estimators will become the new standard method to train normalizing flows for variational inference.
Path-Gradient Estimators for Continuous Normalizing Flows
Jun 17, 2022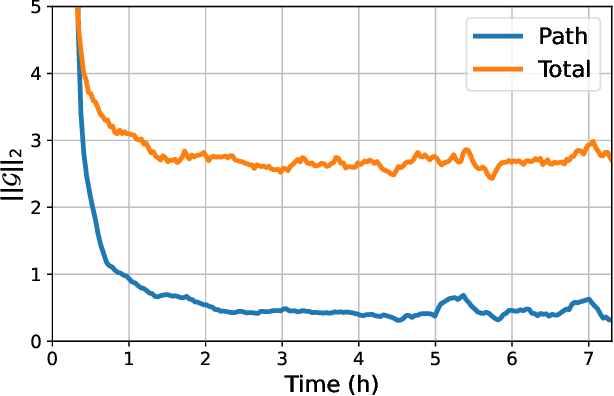

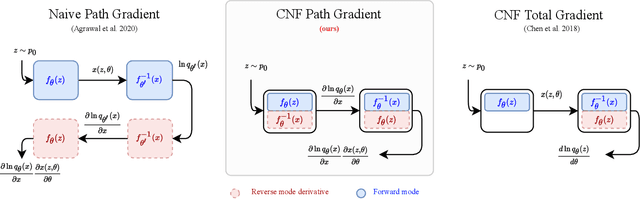
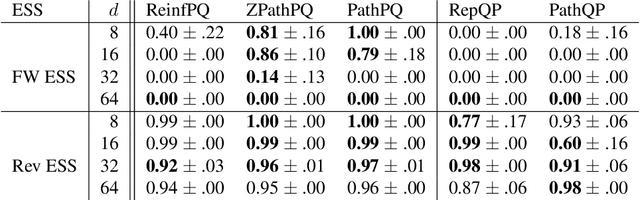
Recent work has established a path-gradient estimator for simple variational Gaussian distributions and has argued that the path-gradient is particularly beneficial in the regime in which the variational distribution approaches the exact target distribution. In many applications, this regime can however not be reached by a simple Gaussian variational distribution. In this work, we overcome this crucial limitation by proposing a path-gradient estimator for the considerably more expressive variational family of continuous normalizing flows. We outline an efficient algorithm to calculate this estimator and establish its superior performance empirically.
Mixture-of-experts VAEs can disregard variation in surjective multimodal data
Apr 11, 2022
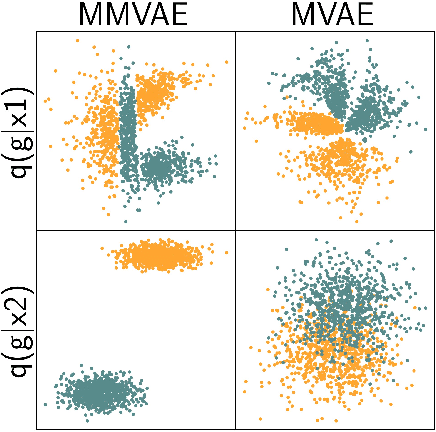
Machine learning systems are often deployed in domains that entail data from multiple modalities, for example, phenotypic and genotypic characteristics describe patients in healthcare. Previous works have developed multimodal variational autoencoders (VAEs) that generate several modalities. We consider subjective data, where single datapoints from one modality (such as class labels) describe multiple datapoints from another modality (such as images). We theoretically and empirically demonstrate that multimodal VAEs with a mixture of experts posterior can struggle to capture variability in such surjective data.
Visualizing the diversity of representations learned by Bayesian neural networks
Jan 26, 2022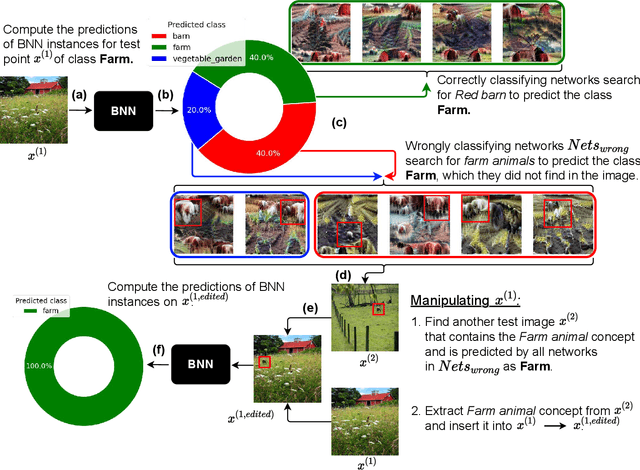


Explainable artificial intelligence (XAI) aims to make learning machines less opaque, and offers researchers and practitioners various tools to reveal the decision-making strategies of neural networks. In this work, we investigate how XAI methods can be used for exploring and visualizing the diversity of feature representations learned by Bayesian neural networks (BNNs). Our goal is to provide a global understanding of BNNs by making their decision-making strategies a) visible and tangible through feature visualizations and b) quantitatively measurable with a distance measure learned by contrastive learning. Our work provides new insights into the posterior distribution in terms of human-understandable feature information with regard to the underlying decision-making strategies. Our main findings are the following: 1) global XAI methods can be applied to explain the diversity of decision-making strategies of BNN instances, 2) Monte Carlo dropout exhibits increased diversity in feature representations compared to the multimodal posterior approximation of MultiSWAG, 3) the diversity of learned feature representations highly correlates with the uncertainty estimates, and 4) the inter-mode diversity of the multimodal posterior decreases as the network width increases, while the intra-mode diversity increases. Our findings are consistent with the recent deep neural networks theory, providing additional intuitions about what the theory implies in terms of humanly understandable concepts.