 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Spread-out Local Feature Descriptors
Aug 21, 2017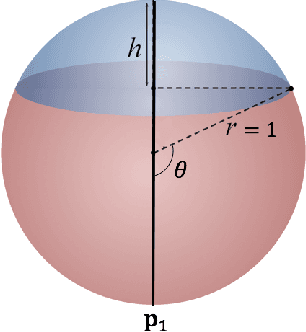
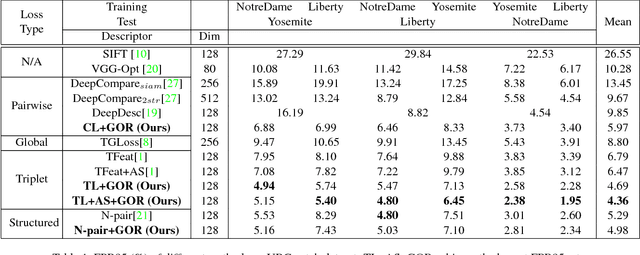
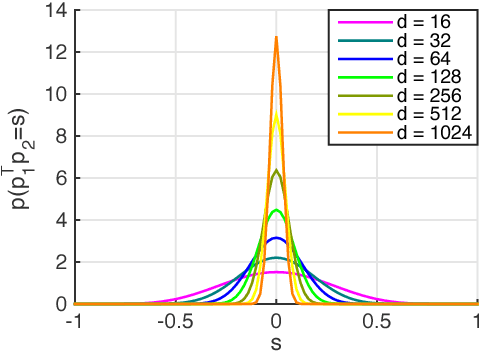
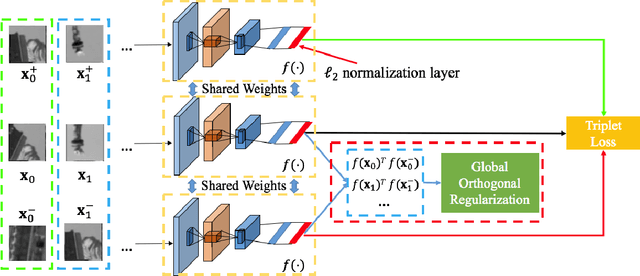
We propose a simple, yet powerful regularization technique that can be used to significantly improve both the pairwise and triplet losses in learning local feature descriptors. The idea is that in order to fully utilize the expressive power of the descriptor space, good local feature descriptors should be sufficiently "spread-out" over the space. In this work, we propose a regularization term to maximize the spread in feature descriptor inspired by the property of uniform distribution. We show that the proposed regularization with triplet loss outperforms existing Euclidean distance based descriptor learning techniques by a large margin. As an extension, the proposed regularization technique can also be used to improve image-level deep feature embedding.
More cat than cute? Interpretable Prediction of Adjective-Noun Pairs
Aug 21, 2017
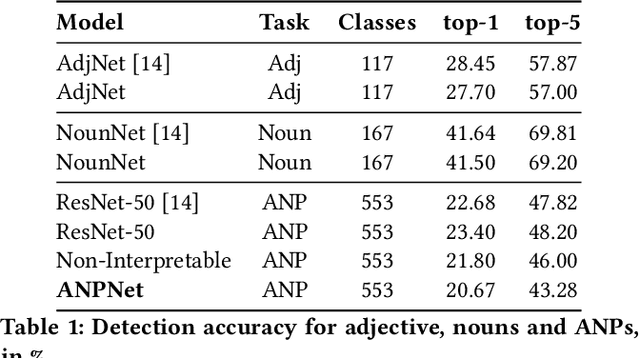
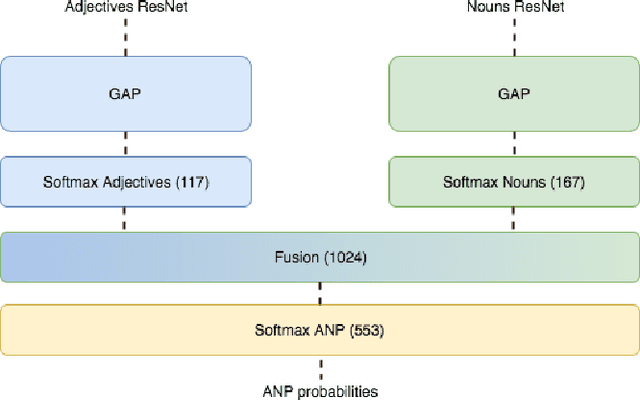
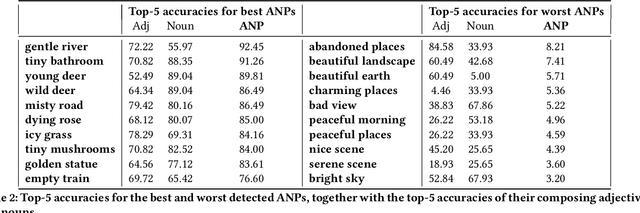
The increasing availability of affect-rich multimedia resources has bolstered interest in understanding sentiment and emotions in and from visual content. Adjective-noun pairs (ANP) are a popular mid-level semantic construct for capturing affect via visually detectable concepts such as "cute dog" or "beautiful landscape". Current state-of-the-art methods approach ANP prediction by considering each of these compound concepts as individual tokens, ignoring the underlying relationships in ANPs. This work aims at disentangling the contributions of the `adjectives' and `nouns' in the visual prediction of ANPs. Two specialised classifiers, one trained for detecting adjectives and another for nouns, are fused to predict 553 different ANPs. The resulting ANP prediction model is more interpretable as it allows us to study contributions of the adjective and noun components. Source code and models are available at https://imatge-upc.github.io/affective-2017-musa2/ .
ConvNet Architecture Search for Spatiotemporal Feature Learning
Aug 16, 2017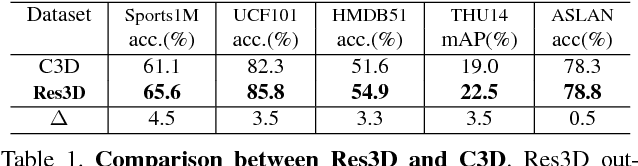
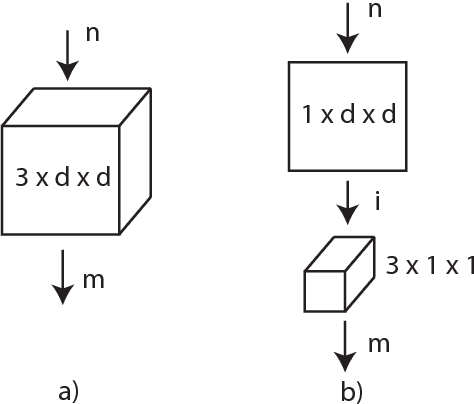
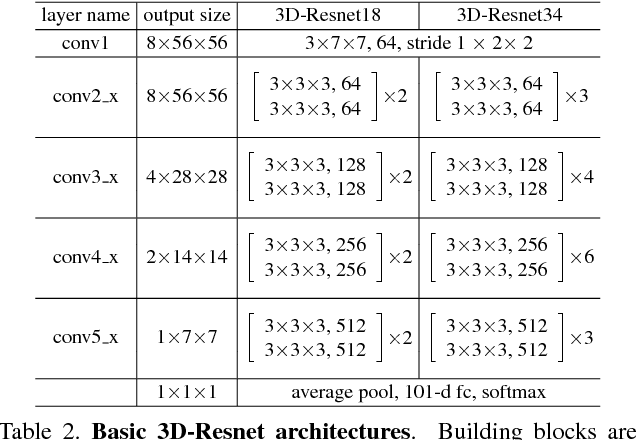

Learning image representations with ConvNets by pre-training on ImageNet has proven useful across many visual understanding tasks including object detection, semantic segmentation, and image captioning. Although any image representation can be applied to video frames, a dedicated spatiotemporal representation is still vital in order to incorporate motion patterns that cannot be captured by appearance based models alone. This paper presents an empirical ConvNet architecture search for spatiotemporal feature learning, culminating in a deep 3-dimensional (3D) Residual ConvNet. Our proposed architecture outperforms C3D by a good margin on Sports-1M, UCF101, HMDB51, THUMOS14, and ASLAN while being 2 times faster at inference time, 2 times smaller in model size, and having a more compact representation.
PPR-FCN: Weakly Supervised Visual Relation Detection via Parallel Pairwise R-FCN
Aug 07, 2017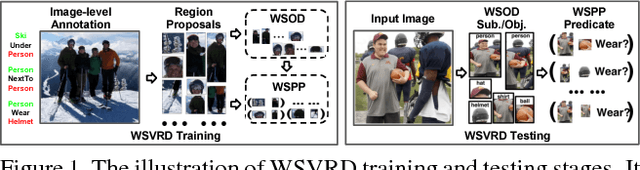
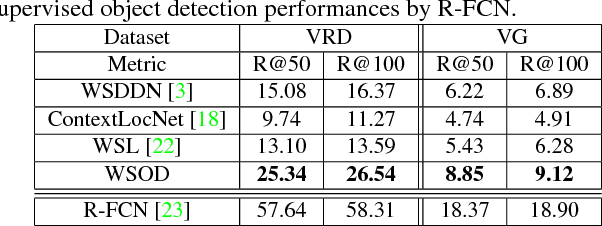
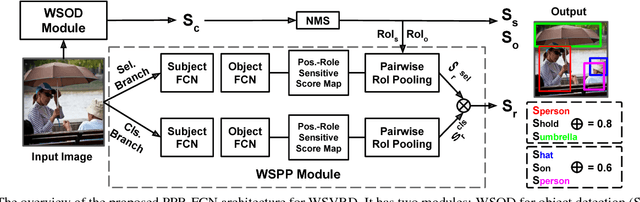
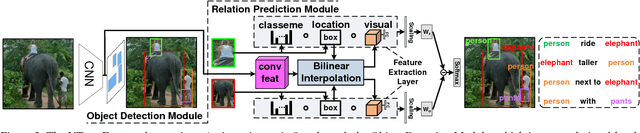
We aim to tackle a novel vision task called Weakly Supervised Visual Relation Detection (WSVRD) to detect "subject-predicate-object" relations in an image with object relation groundtruths available only at the image level. This is motivated by the fact that it is extremely expensive to label the combinatorial relations between objects at the instance level. Compared to the extensively studied problem, Weakly Supervised Object Detection (WSOD), WSVRD is more challenging as it needs to examine a large set of regions pairs, which is computationally prohibitive and more likely stuck in a local optimal solution such as those involving wrong spatial context. To this end, we present a Parallel, Pairwise Region-based, Fully Convolutional Network (PPR-FCN) for WSVRD. It uses a parallel FCN architecture that simultaneously performs pair selection and classification of single regions and region pairs for object and relation detection, while sharing almost all computation shared over the entire image. In particular, we propose a novel position-role-sensitive score map with pairwise RoI pooling to efficiently capture the crucial context associated with a pair of objects. We demonstrate the superiority of PPR-FCN over all baselines in solving the WSVRD challenge by using results of extensive experiments over two visual relation benchmarks.
Localizing Actions from Video Labels and Pseudo-Annotations
Jul 28, 2017
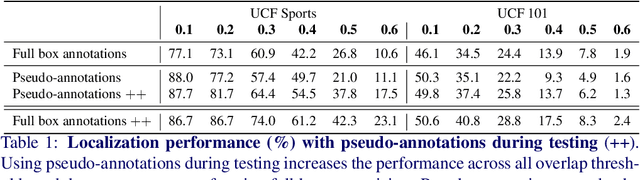

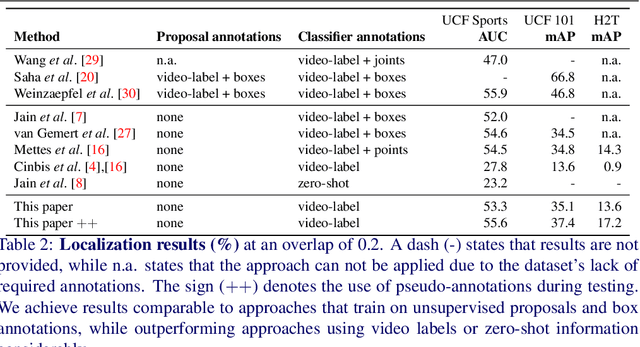
The goal of this paper is to determine the spatio-temporal location of actions in video. Where training from hard to obtain box annotations is the norm, we propose an intuitive and effective algorithm that localizes actions from their class label only. We are inspired by recent work showing that unsupervised action proposals selected with human point-supervision perform as well as using expensive box annotations. Rather than asking users to provide point supervision, we propose fully automatic visual cues that replace manual point annotations. We call the cues pseudo-annotations, introduce five of them, and propose a correlation metric for automatically selecting and combining them. Thorough evaluation on challenging action localization datasets shows that we reach results comparable to results with full box supervision. We also show that pseudo-annotations can be leveraged during testing to improve weakly- and strongly-supervised localizers.
Modeling Multimodal Clues in a Hybrid Deep Learning Framework for Video Classification
Jun 14, 2017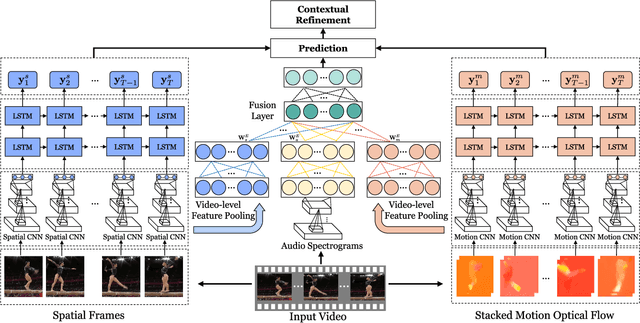
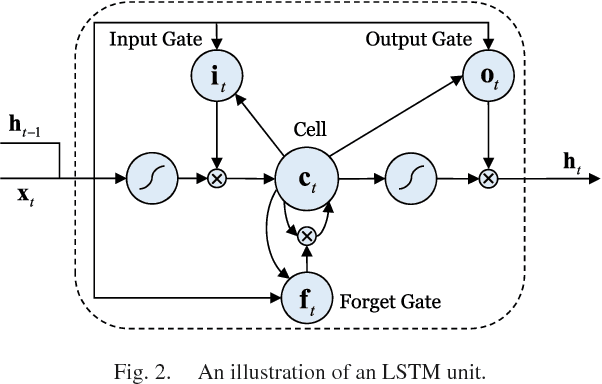

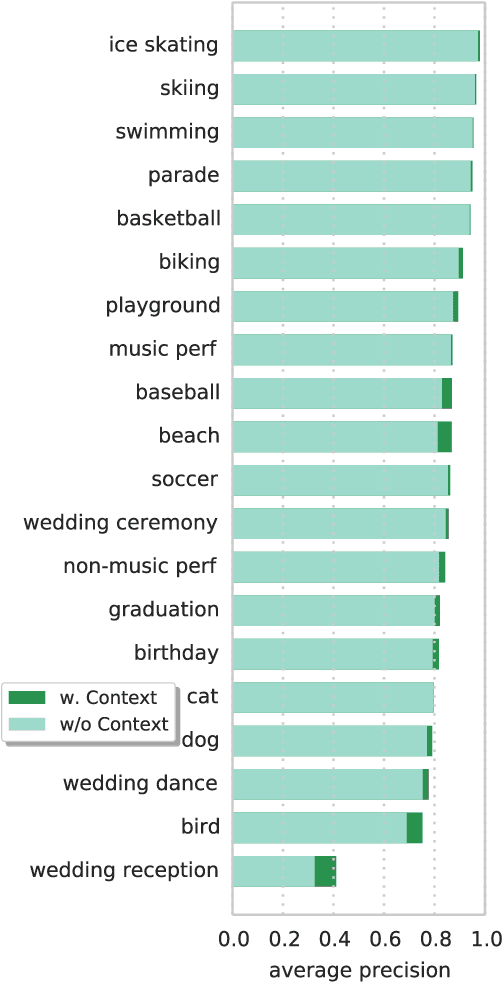
Videos are inherently multimodal. This paper studies the problem of how to fully exploit the abundant multimodal clues for improved video categorization. We introduce a hybrid deep learning framework that integrates useful clues from multiple modalities, including static spatial appearance information, motion patterns within a short time window, audio information as well as long-range temporal dynamics. More specifically, we utilize three Convolutional Neural Networks (CNNs) operating on appearance, motion and audio signals to extract their corresponding features. We then employ a feature fusion network to derive a unified representation with an aim to capture the relationships among features. Furthermore, to exploit the long-range temporal dynamics in videos, we apply two Long Short Term Memory networks with extracted appearance and motion features as inputs. Finally, we also propose to refine the prediction scores by leveraging contextual relationships among video semantics. The hybrid deep learning framework is able to exploit a comprehensive set of multimodal features for video classification. Through an extensive set of experiments, we demonstrate that (1) LSTM networks which model sequences in an explicitly recurrent manner are highly complementary with CNN models; (2) the feature fusion network which produces a fused representation through modeling feature relationships outperforms alternative fusion strategies; (3) the semantic context of video classes can help further refine the predictions for improved performance. Experimental results on two challenging benchmarks, the UCF-101 and the Columbia Consumer Videos (CCV), provide strong quantitative evidence that our framework achieves promising results: $93.1\%$ on the UCF-101 and $84.5\%$ on the CCV, outperforming competing methods with clear margins.
CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos
Jun 13, 2017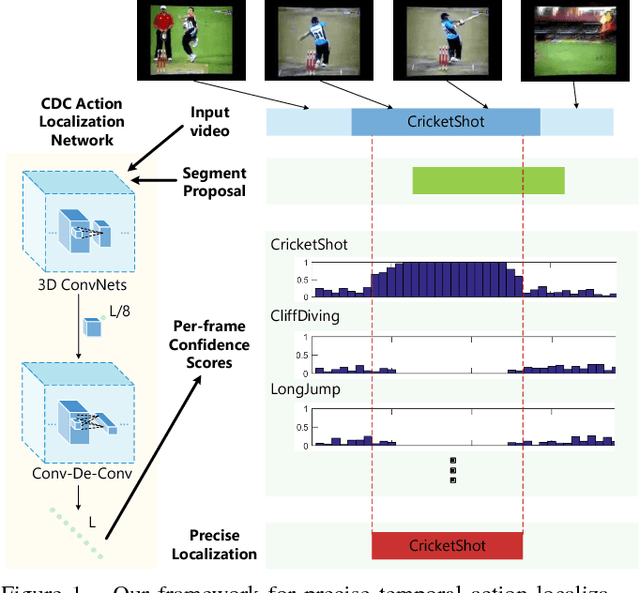
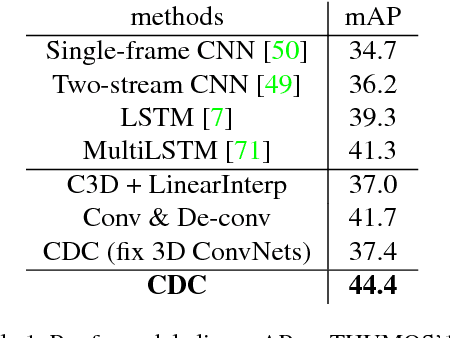
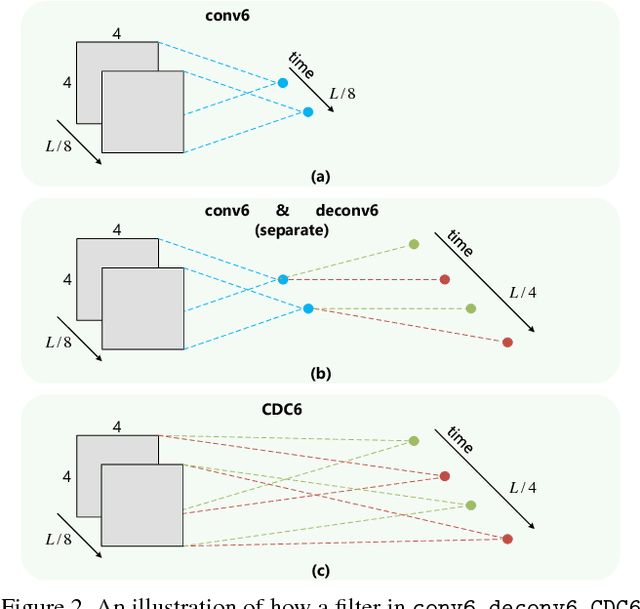
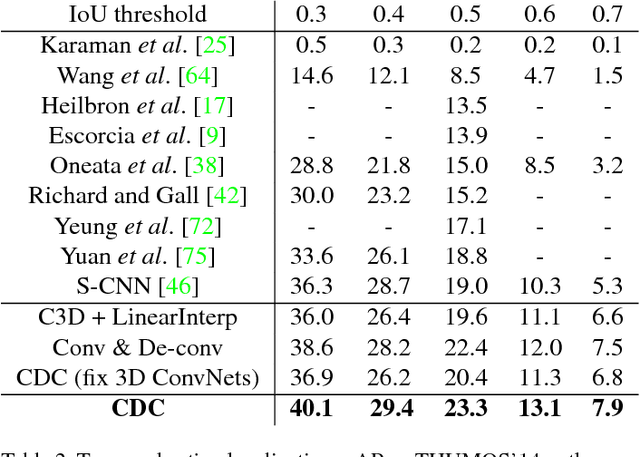
Temporal action localization is an important yet challenging problem. Given a long, untrimmed video consisting of multiple action instances and complex background contents, we need not only to recognize their action categories, but also to localize the start time and end time of each instance. Many state-of-the-art systems use segment-level classifiers to select and rank proposal segments of pre-determined boundaries. However, a desirable model should move beyond segment-level and make dense predictions at a fine granularity in time to determine precise temporal boundaries. To this end, we design a novel Convolutional-De-Convolutional (CDC) network that places CDC filters on top of 3D ConvNets, which have been shown to be effective for abstracting action semantics but reduce the temporal length of the input data. The proposed CDC filter performs the required temporal upsampling and spatial downsampling operations simultaneously to predict actions at the frame-level granularity. It is unique in jointly modeling action semantics in space-time and fine-grained temporal dynamics. We train the CDC network in an end-to-end manner efficiently. Our model not only achieves superior performance in detecting actions in every frame, but also significantly boosts the precision of localizing temporal boundaries. Finally, the CDC network demonstrates a very high efficiency with the ability to process 500 frames per second on a single GPU server. We will update the camera-ready version and publish the source codes online soon.
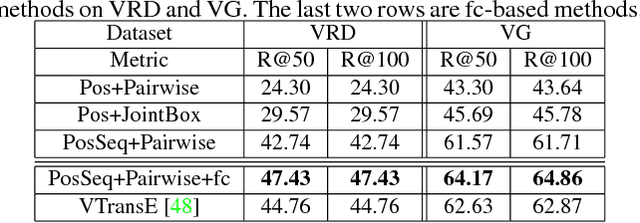
Visual Translation Embedding Network for Visual Relation Detection
Feb 27, 2017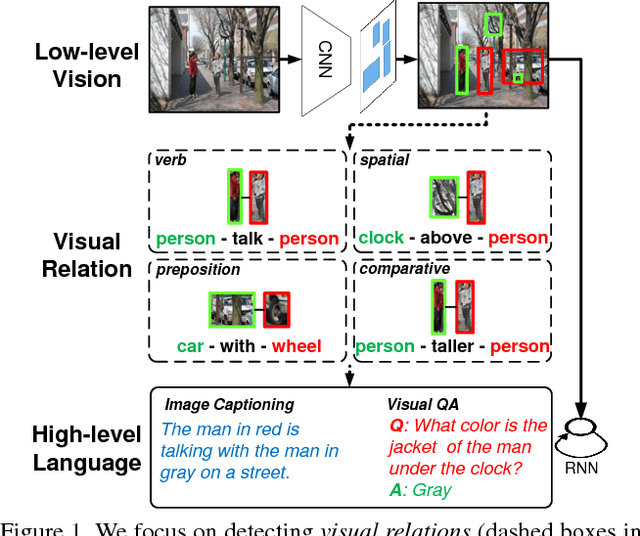
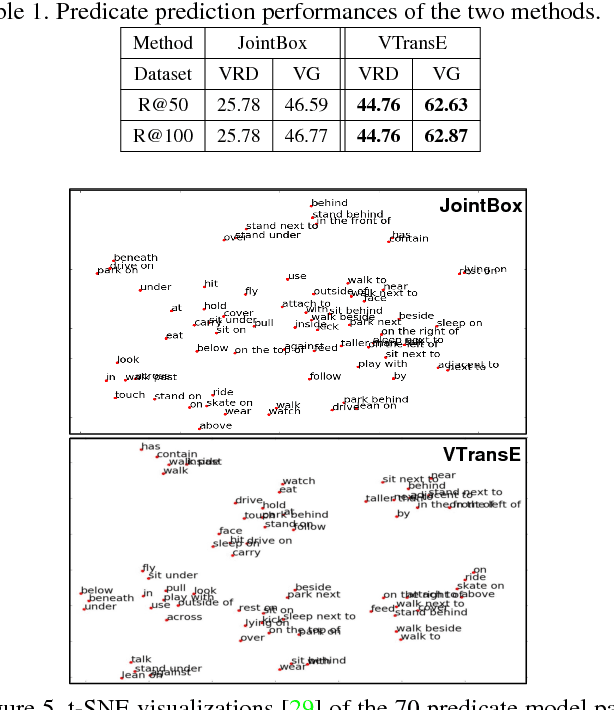
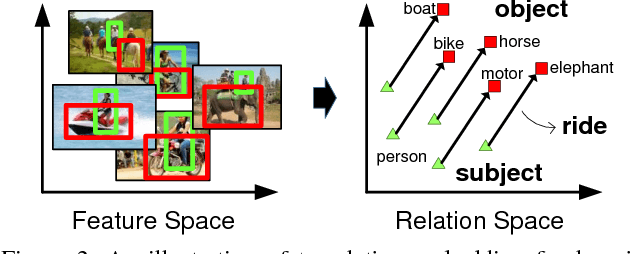
Visual relations, such as "person ride bike" and "bike next to car", offer a comprehensive scene understanding of an image, and have already shown their great utility in connecting computer vision and natural language. However, due to the challenging combinatorial complexity of modeling subject-predicate-object relation triplets, very little work has been done to localize and predict visual relations. Inspired by the recent advances in relational representation learning of knowledge bases and convolutional object detection networks, we propose a Visual Translation Embedding network (VTransE) for visual relation detection. VTransE places objects in a low-dimensional relation space where a relation can be modeled as a simple vector translation, i.e., subject + predicate $\approx$ object. We propose a novel feature extraction layer that enables object-relation knowledge transfer in a fully-convolutional fashion that supports training and inference in a single forward/backward pass. To the best of our knowledge, VTransE is the first end-to-end relation detection network. We demonstrate the effectiveness of VTransE over other state-of-the-art methods on two large-scale datasets: Visual Relationship and Visual Genome. Note that even though VTransE is a purely visual model, it is still competitive to the Lu's multi-modal model with language priors.
Deep Image Set Hashing
Oct 01, 2016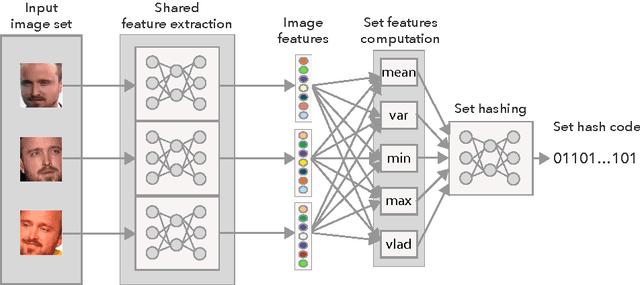
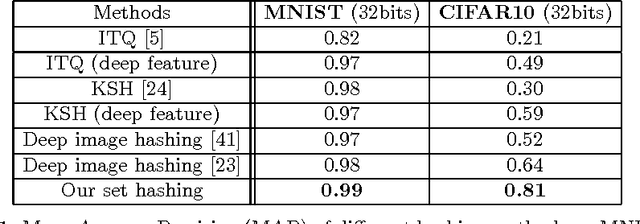

In applications involving matching of image sets, the information from multiple images must be effectively exploited to represent each set. State-of-the-art methods use probabilistic distribution or subspace to model a set and use specific distance measure to compare two sets. These methods are slow to compute and not compact to use in a large scale scenario. Learning-based hashing is often used in large scale image retrieval as they provide a compact representation of each sample and the Hamming distance can be used to efficiently compare two samples. However, most hashing methods encode each image separately and discard knowledge that multiple images in the same set represent the same object or person. We investigate the set hashing problem by combining both set representation and hashing in a single deep neural network. An image set is first passed to a CNN module to extract image features, then these features are aggregated using two types of set feature to capture both set specific and database-wide distribution information. The computed set feature is then fed into a multilayer perceptron to learn a compact binary embedding. Triplet loss is used to train the network by forming set similarity relations using class labels. We extensively evaluate our approach on datasets used for image matching and show highly competitive performance compared to state-of-the-art methods.
EventNet Version 1.1 Technical Report
Sep 11, 2016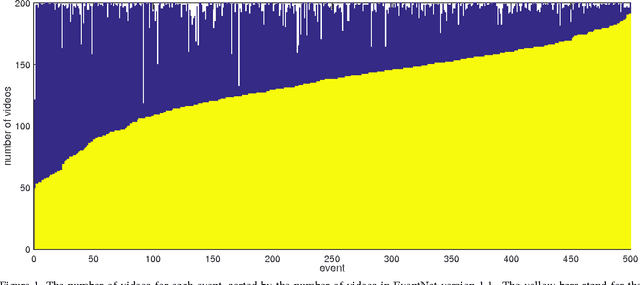
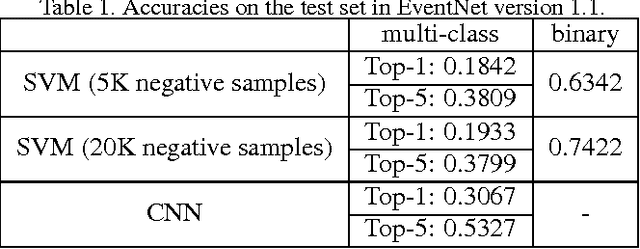
EventNet is a large-scale video corpus and event ontology consisting of 500 events associated with event-specific concepts. In order to improve the quality of the current EventNet, we conduct the following steps and introduce EventNet version 1.1: (1) manually verify the correctness of event labels for all videos; (2) remove the YouTube user bias by limiting the maximum number of videos in each event from the same YouTube user as 3; (3) remove the videos which are currently not accessible online; (4) remove the video belonging to multiple event categories. After the above procedure, some events may contain only a small number of videos, and therefore we crawl more videos for those events to ensure every event will contain more than 50 videos. Finally, EventNet version 1.1 contains 67,641 videos, 500 events, and 5,028 event-specific concepts. In addition, we train a Convolutional Neural Network (CNN) model for event classification via fine-tuning AlexNet using EventNet version 1.1. Then we use the trained CNN model to extract FC7 layer feature and train binary classifiers using linear SVM for each event-specific concept. We believe this new version of EventNet will significantly facilitate research in computer vision and multimedia, and will put it online for public downloading in the future.