 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Reinforcement Learning in Contextual MDPs
May 29, 2019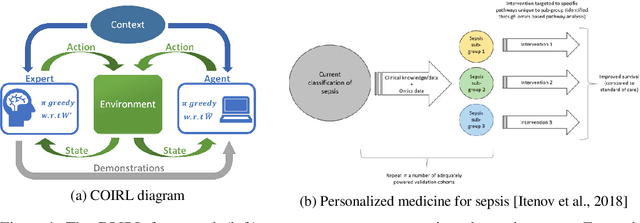
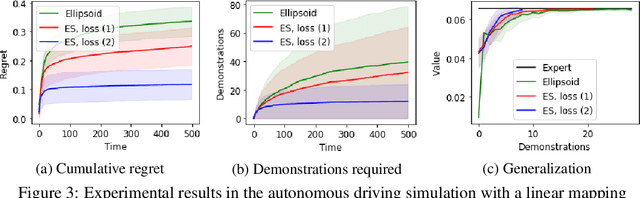
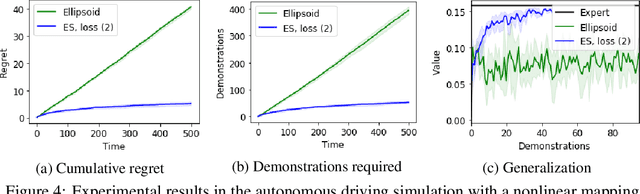
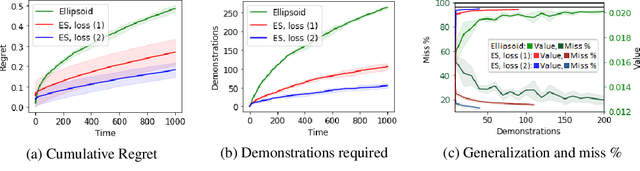
We consider the Inverse Reinforcement Learning (IRL) problem in Contextual Markov Decision Processes (CMDPs). Here, the reward of the environment, which is not available to the agent, depends on a static parameter referred to as the context. Each context defines an MDP (with a different reward signal), and the agent is provided demonstrations by an expert, for different contexts. The goal is to learn a mapping from contexts to rewards, such that planning with respect to the induced reward will perform similarly to the expert, even for unseen contexts. We suggest two learning algorithms for this scenario. (1) For rewards that are a linear function of the context, we provide a method that is guaranteed to return an $\epsilon$-optimal solution after a polynomial number of demonstrations. (2) For general reward functions, we propose black-box descent methods based on evolutionary strategies capable of working with nonlinear estimators (e.g., neural networks). We evaluate our algorithms in autonomous driving and medical treatment simulations and demonstrate their ability to learn and generalize to unseen contexts.
Tight Regret Bounds for Model-Based Reinforcement Learning with Greedy Policies
May 27, 2019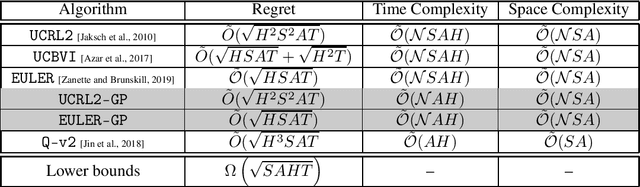
State-of-the-art efficient model-based Reinforcement Learning (RL) algorithms typically act by iteratively solving empirical models, i.e., by performing \emph{full-planning} on Markov Decision Processes (MDPs) built by the gathered experience. In this paper, we focus on model-based RL in the finite-state finite-horizon MDP setting and establish that exploring with \emph{greedy policies} -- act by \emph{1-step planning} -- can achieve tight minimax performance in terms of regret, $\tilde{\mathcal{O}}(\sqrt{HSAT})$. Thus, full-planning in model-based RL can be avoided altogether without any performance degradation, and, by doing so, the computational complexity decreases by a factor of $S$. The results are based on a novel analysis of real-time dynamic programming, then extended to model-based RL. Specifically, we generalize existing algorithms that perform full-planning to such that act by 1-step planning. For these generalizations, we prove regret bounds with the same rate as their full-planning counterparts.
Distributional Policy Optimization: An Alternative Approach for Continuous Control
May 23, 2019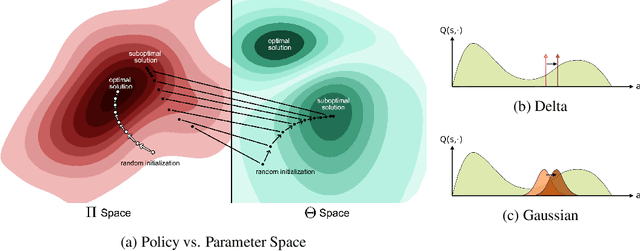

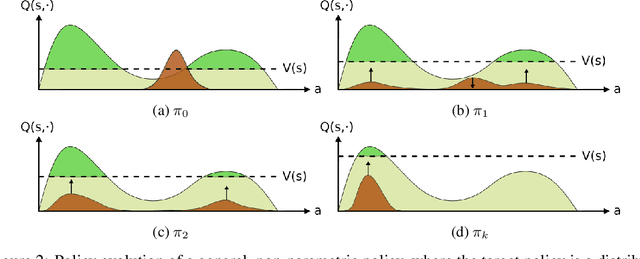

We identify a fundamental problem in policy gradient-based methods in continuous control. As policy gradient methods require the agent's underlying probability distribution, they limit policy representation to parametric distribution classes. We show that optimizing over such sets results in local movement in the action space and thus convergence to sub-optimal solutions. We suggest a novel distributional framework, able to represent arbitrary distribution functions over the continuous action space. Using this framework, we construct a generative scheme, trained using an off-policy actor-critic paradigm, which we call the Generative Actor Critic (GAC). Compared to policy gradient methods, GAC does not require knowledge of the underlying probability distribution, thereby overcoming these limitations. Empirical evaluation shows that our approach is comparable and often surpasses current state-of-the-art baselines in continuous domains.
Action Assembly: Sparse Imitation Learning for Text Based Games with Combinatorial Action Spaces
May 23, 2019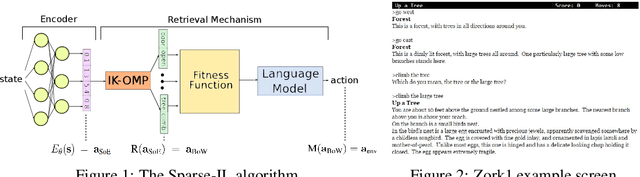
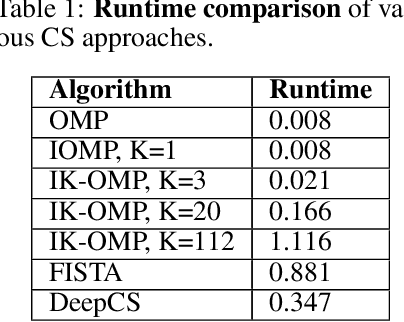
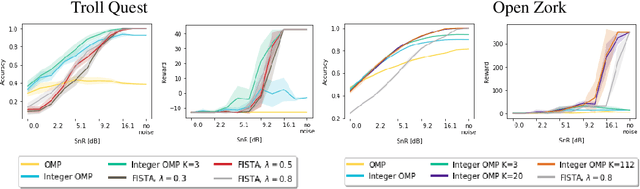
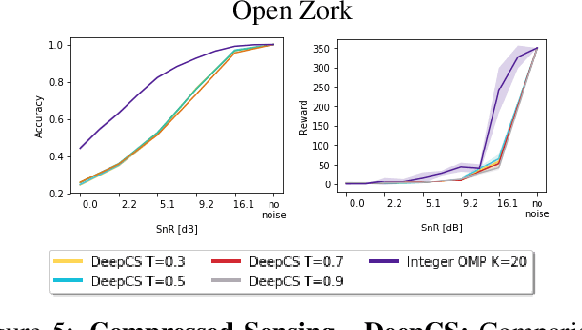
We propose a computationally efficient algorithm that combines compressed sensing with imitation learning to solve sequential decision making text-based games with combinatorial action spaces. We propose a variation of the compressed sensing algorithm Orthogonal Matching Pursuit (OMP), that we call IK-OMP, and show that it can recover a bag-of-words from a sum of the individual word embeddings, even in the presence of noise. We incorporate IK-OMP into a supervised imitation learning setting and show that this algorithm, called Sparse Imitation Learning (Sparse-IL), solves the entire text-based game of Zork1 with an action space of approximately 10 million actions using imperfect, noisy demonstrations.
A Bayesian Approach to Robust Reinforcement Learning
May 20, 2019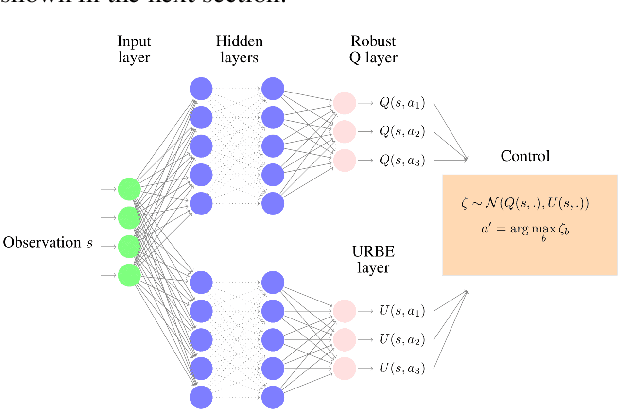

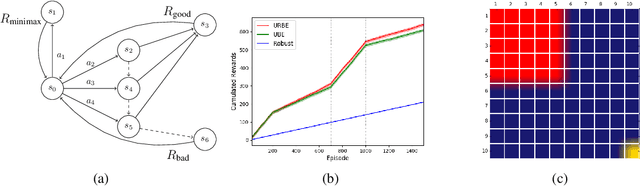
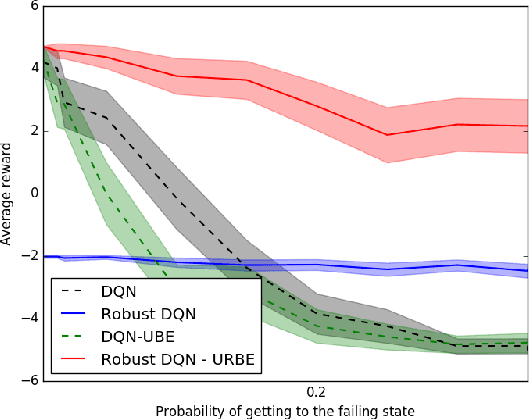
Robust Markov Decision Processes (RMDPs) intend to ensure robustness with respect to changing or adversarial system behavior. In this framework, transitions are modeled as arbitrary elements of a known and properly structured uncertainty set and a robust optimal policy can be derived under the worst-case scenario. In this study, we address the issue of learning in RMDPs using a Bayesian approach. We introduce the Uncertainty Robust Bellman Equation (URBE) which encourages safe exploration for adapting the uncertainty set to new observations while preserving robustness. We propose a URBE-based algorithm, DQN-URBE, that scales this method to higher dimensional domains. Our experiments show that the derived URBE-based strategy leads to a better trade-off between less conservative solutions and robustness in the presence of model misspecification. In addition, we show that the DQN-URBE algorithm can adapt significantly faster to changing dynamics online compared to existing robust techniques with fixed uncertainty sets.
Image Matters: Detecting Offensive and Non-Compliant Content / Logo in Product Images
May 06, 2019
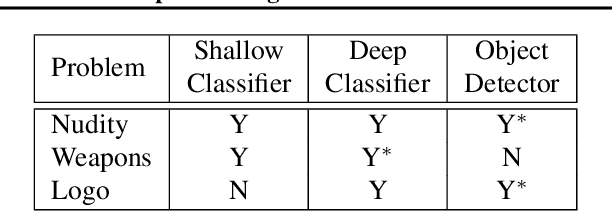

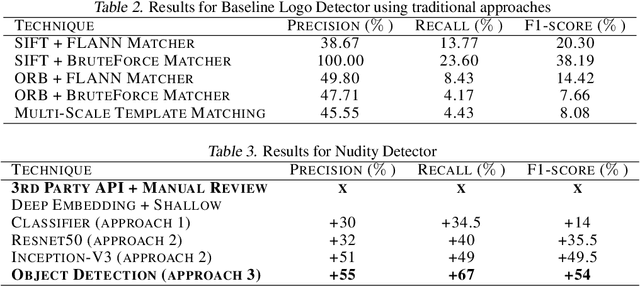
In e-commerce, product content, especially product images have a significant influence on a customer's journey from product discovery to evaluation and finally, purchase decision. Since many e-commerce retailers sell items from other third-party marketplace sellers besides their own, the content published by both internal and external content creators needs to be monitored and enriched, wherever possible. Despite guidelines and warnings, product listings that contain offensive and non-compliant images continue to enter catalogs. Offensive and non-compliant content can include a wide range of objects, logos, and banners conveying violent, sexually explicit, racist, or promotional messages. Such images can severely damage the customer experience, lead to legal issues, and erode the company brand. In this paper, we present a machine learning driven offensive and non-compliant image detection system for extremely large e-commerce catalogs. This system proactively detects and removes such content before they are published to the customer-facing website. This paper delves into the unique challenges of applying machine learning to real-world data from retail domain with hundreds of millions of product images. We demonstrate how we resolve the issue of non-compliant content that appears across tens of thousands of product categories. We also describe how we deal with the sheer variety in which each single non-compliant scenario appears. This paper showcases a number of practical yet unique approaches such as representative training data creation that are critical to solve an extremely rarely occurring problem. In summary, our system combines state-of-the-art image classification and object detection techniques, and fine tunes them with internal data to develop a solution customized for a massive, diverse, and constantly evolving product catalog.
A Problem-Adaptive Algorithm for Resource Allocation
Feb 12, 2019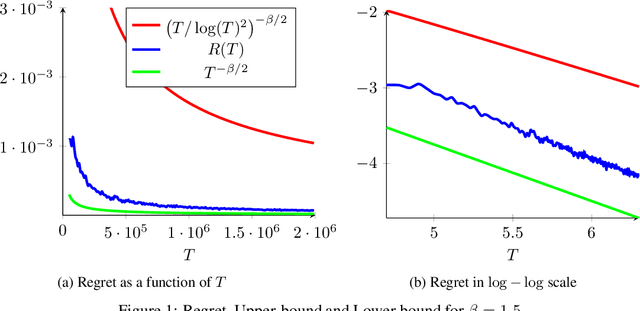
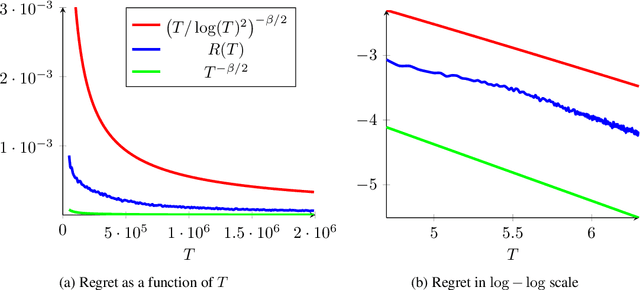
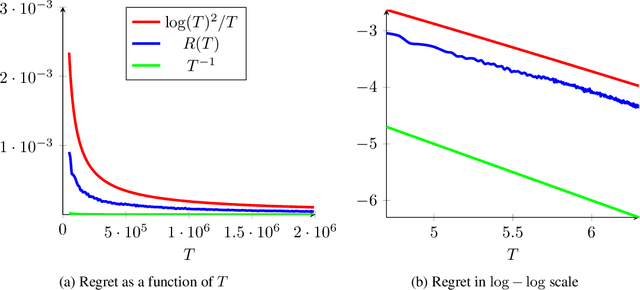
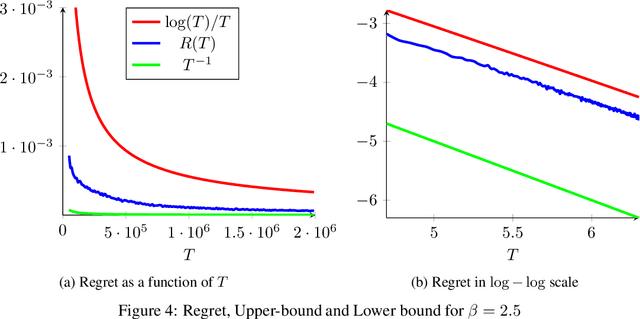
We consider a sequential stochastic resource allocation problem under the gradient feedback, where the reward of each resource is concave. We construct a generic algorithm that is adaptive to the complexity of the problem, which is measured using the exponent in {\L}ojasiewicz inequality. Our algorithm interpolates between the non-strongly concave and the strongly-concave rates without depending on the strong-concavity parameter and recover the fast rate of classical multi-armed bandit (corresponding roughly to linear reward functions).
The Natural Language of Actions
Feb 04, 2019
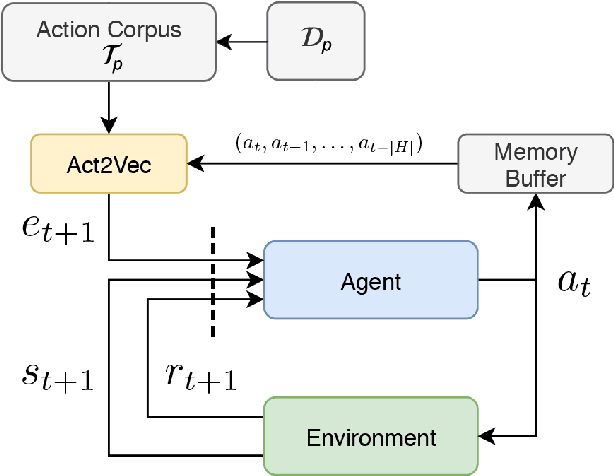
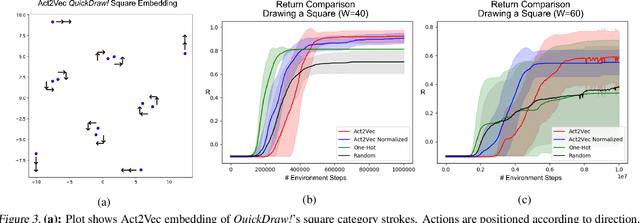
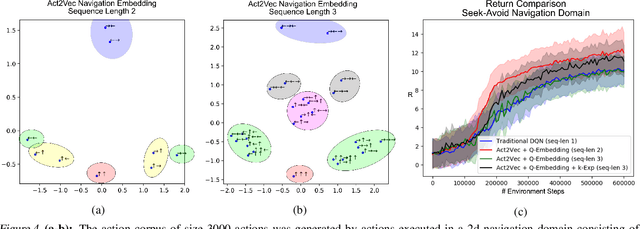
We introduce Act2Vec, a general framework for learning context-based action representation for Reinforcement Learning. Representing actions in a vector space help reinforcement learning algorithms achieve better performance by grouping similar actions and utilizing relations between different actions. We show how prior knowledge of an environment can be extracted from demonstrations and injected into action vector representations that encode natural compatible behavior. We then use these for augmenting state representations as well as improving function approximation of Q-values. We visualize and test action embeddings in three domains including a drawing task, a high dimensional navigation task, and the large action space domain of StarCraft II.
Value Propagation for Decentralized Networked Deep Multi-agent Reinforcement Learning
Jan 27, 2019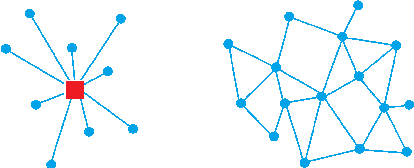
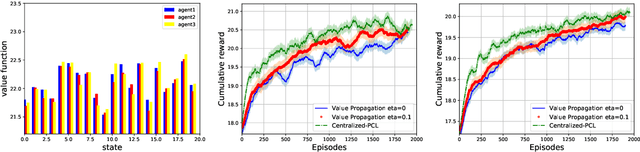
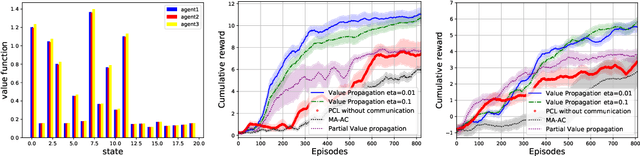
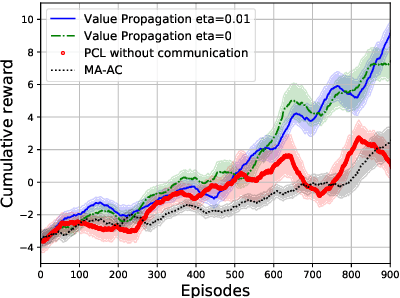
We consider the networked multi-agent reinforcement learning (MARL) problem in a fully decentralized setting, where agents learn to coordinate to achieve the joint success. This problem is widely encountered in many areas including traffic control, distributed control, and smart grids. We assume that the reward function for each agent can be different and observed only locally by the agent itself. Furthermore, each agent is located at a node of a communication network and can exchanges information only with its neighbors. Using softmax temporal consistency and a decentralized optimization method, we obtain a principled and data-efficient iterative algorithm. In the first step of each iteration, an agent computes its local policy and value gradients and then updates only policy parameters. In the second step, the agent propagates to its neighbors the messages based on its value function and then updates its own value function. Hence we name the algorithm value propagation. We prove a non-asymptotic convergence rate 1/T with the nonlinear function approximation. To the best of our knowledge, it is the first MARL algorithm with convergence guarantee in the control, off-policy and non-linear function approximation setting. We empirically demonstrate the effectiveness of our approach in experiments.
Action Robust Reinforcement Learning and Applications in Continuous Control
Jan 26, 2019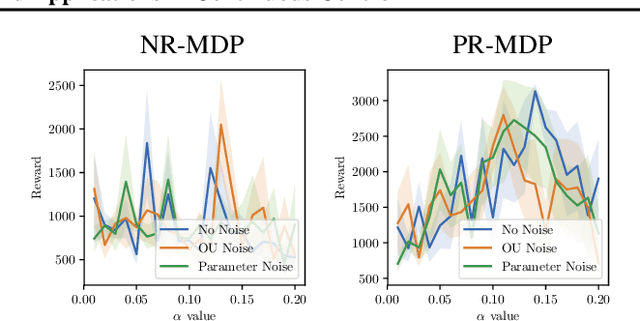

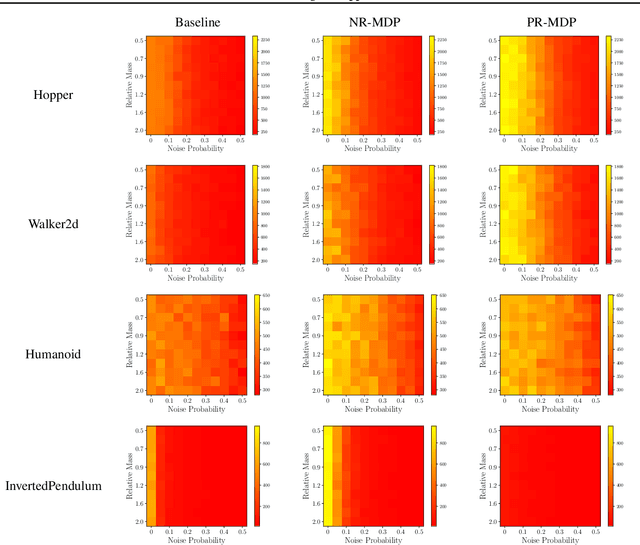
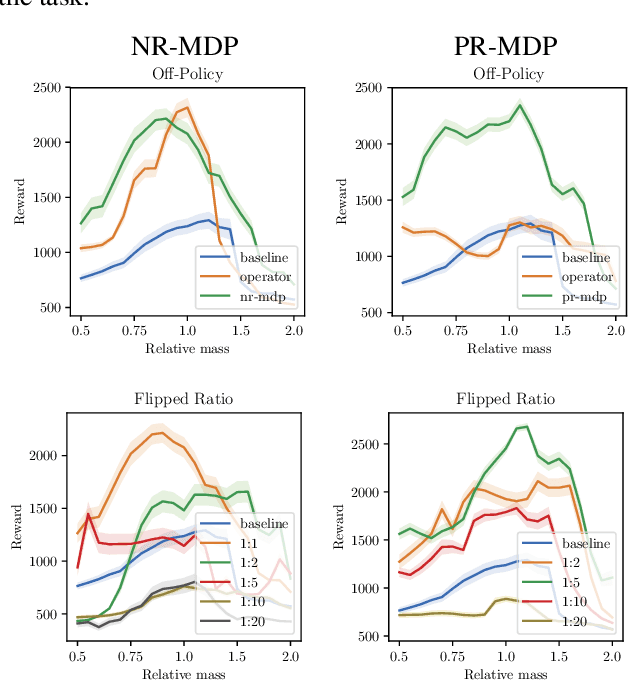
A policy is said to be robust if it maximizes the reward while considering a bad, or even adversarial, model. In this work we formalize two new criteria of robustness to action uncertainty. Specifically, we consider two scenarios in which the agent attempts to perform an action $\mathbf{a}$, and (i) with probability $\alpha$, an alternative adversarial action $\bar{\mathbf{a}}$ is taken, or (ii) an adversary adds a perturbation to the selected action in the case of continuous action space. We show that our criteria are related to common forms of uncertainty in robotics domains, such as the occurrence of abrupt forces, and suggest algorithms in the tabular case. Building on the suggested algorithms, we generalize our approach to deep reinforcement learning (DRL) and provide extensive experiments in the various MuJoCo domains. Our experiments show that not only does our approach produce robust policies, but it also improves the performance in the absence of perturbations. This generalization indicates that action-robustness can be thought of as implicit regularization in RL problems.