 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Tensor Decomposition via Neural Diffusion-Reaction Processes
Oct 30, 2023



Tensor decomposition is an important tool for multiway data analysis. In practice, the data is often sparse yet associated with rich temporal information. Existing methods, however, often under-use the time information and ignore the structural knowledge within the sparsely observed tensor entries. To overcome these limitations and to better capture the underlying temporal structure, we propose Dynamic EMbedIngs fOr dynamic Tensor dEcomposition (DEMOTE). We develop a neural diffusion-reaction process to estimate dynamic embeddings for the entities in each tensor mode. Specifically, based on the observed tensor entries, we build a multi-partite graph to encode the correlation between the entities. We construct a graph diffusion process to co-evolve the embedding trajectories of the correlated entities and use a neural network to construct a reaction process for each individual entity. In this way, our model can capture both the commonalities and personalities during the evolution of the embeddings for different entities. We then use a neural network to model the entry value as a nonlinear function of the embedding trajectories. For model estimation, we combine ODE solvers to develop a stochastic mini-batch learning algorithm. We propose a stratified sampling method to balance the cost of processing each mini-batch so as to improve the overall efficiency. We show the advantage of our approach in both simulation study and real-world applications. The code is available at https://github.com/wzhut/Dynamic-Tensor-Decomposition-via-Neural-Diffusion-Reaction-Processes.
Multi-Resolution Active Learning of Fourier Neural Operators
Oct 08, 2023



Fourier Neural Operator (FNO) is a popular operator learning framework, which not only achieves the state-of-the-art performance in many tasks, but also is highly efficient in training and prediction. However, collecting training data for the FNO is a costly bottleneck in practice, because it often demands expensive physical simulations. To overcome this problem, we propose Multi-Resolution Active learning of FNO (MRA-FNO), which can dynamically select the input functions and resolutions to lower the data cost as much as possible while optimizing the learning efficiency. Specifically, we propose a probabilistic multi-resolution FNO and use ensemble Monte-Carlo to develop an effective posterior inference algorithm. To conduct active learning, we maximize a utility-cost ratio as the acquisition function to acquire new examples and resolutions at each step. We use moment matching and the matrix determinant lemma to enable tractable, efficient utility computation. Furthermore, we develop a cost annealing framework to avoid over-penalizing high-resolution queries at the early stage. The over-penalization is severe when the cost difference is significant between the resolutions, which renders active learning often stuck at low-resolution queries and inferior performance. Our method overcomes this problem and applies to general multi-fidelity active learning and optimization problems. We have shown the advantage of our method in several benchmark operator learning tasks.
Batch Multi-Fidelity Active Learning with Budget Constraints
Oct 23, 2022



Learning functions with high-dimensional outputs is critical in many applications, such as physical simulation and engineering design. However, collecting training examples for these applications is often costly, e.g. by running numerical solvers. The recent work (Li et al., 2022) proposes the first multi-fidelity active learning approach for high-dimensional outputs, which can acquire examples at different fidelities to reduce the cost while improving the learning performance. However, this method only queries at one pair of fidelity and input at a time, and hence has a risk to bring in strongly correlated examples to reduce the learning efficiency. In this paper, we propose Batch Multi-Fidelity Active Learning with Budget Constraints (BMFAL-BC), which can promote the diversity of training examples to improve the benefit-cost ratio, while respecting a given budget constraint for batch queries. Hence, our method can be more practically useful. Specifically, we propose a novel batch acquisition function that measures the mutual information between a batch of multi-fidelity queries and the target function, so as to penalize highly correlated queries and encourages diversity. The optimization of the batch acquisition function is challenging in that it involves a combinatorial search over many fidelities while subject to the budget constraint. To address this challenge, we develop a weighted greedy algorithm that can sequentially identify each (fidelity, input) pair, while achieving a near $(1 - 1/e)$-approximation of the optimum. We show the advantage of our method in several computational physics and engineering applications.
Meta Learning of Interface Conditions for Multi-Domain Physics-Informed Neural Networks
Oct 23, 2022



Physics-informed neural networks (PINNs) are emerging as popular mesh-free solvers for partial differential equations (PDEs). Recent extensions decompose the domain, applying different PINNs to solve the equation in each subdomain and aligning the solution at the interface of the subdomains. Hence, they can further alleviate the problem complexity, reduce the computational cost, and allow parallelization. However, the performance of the multi-domain PINNs is sensitive to the choice of the interface conditions for solution alignment. While quite a few conditions have been proposed, there is no suggestion about how to select the conditions according to specific problems. To address this gap, we propose META Learning of Interface Conditions (METALIC), a simple, efficient yet powerful approach to dynamically determine the optimal interface conditions for solving a family of parametric PDEs. Specifically, we develop two contextual multi-arm bandit models. The first one applies to the entire training procedure, and online updates a Gaussian process (GP) reward surrogate that given the PDE parameters and interface conditions predicts the solution error. The second one partitions the training into two stages, one is the stochastic phase and the other deterministic phase; we update a GP surrogate for each phase to enable different condition selections at the two stages so as to further bolster the flexibility and performance. We have shown the advantage of METALIC on four bench-mark PDE families.
An Interpretable and Efficient Infinite-Order Vector Autoregressive Model for High-Dimensional Time Series
Sep 16, 2022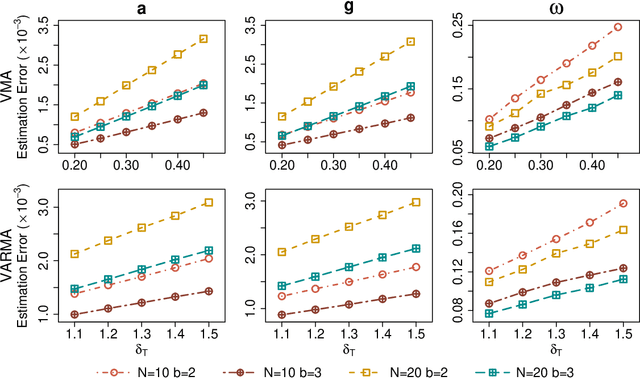
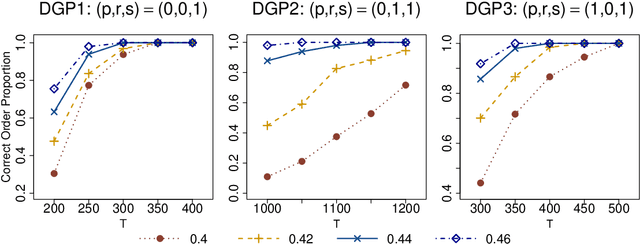
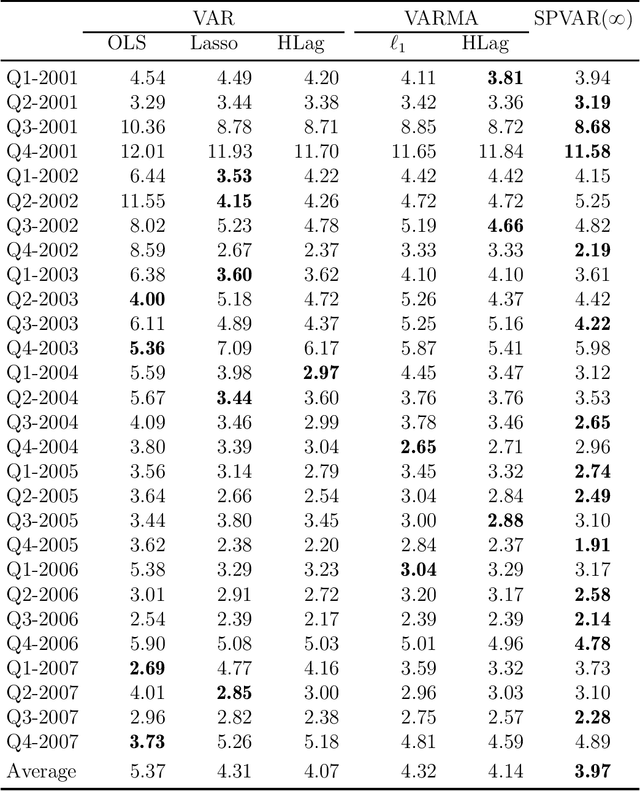
As a special infinite-order vector autoregressive (VAR) model, the vector autoregressive moving average (VARMA) model can capture much richer temporal patterns than the widely used finite-order VAR model. However, its practicality has long been hindered by its non-identifiability, computational intractability, and relative difficulty of interpretation. This paper introduces a novel infinite-order VAR model which, with only a little sacrifice of generality, inherits the essential temporal patterns of the VARMA model but avoids all of the above drawbacks. As another attractive feature, the temporal and cross-sectional dependence structures of this model can be interpreted separately, since they are characterized by different sets of parameters. For high-dimensional time series, this separation motivates us to impose sparsity on the parameters determining the cross-sectional dependence. As a result, greater statistical efficiency and interpretability can be achieved, while no loss of temporal information is incurred by the imposed sparsity. We introduce an $\ell_1$-regularized estimator for the proposed model and derive the corresponding nonasymptotic error bounds. An efficient block coordinate descent algorithm and a consistent model order selection method are developed. The merit of the proposed approach is supported by simulation studies and a real-world macroeconomic data analysis.
A novel learning-based robust model predictive control energy management strategy for fuel cell electric vehicles
Sep 12, 2022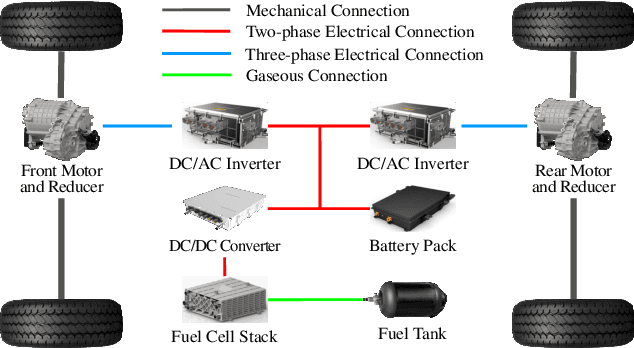
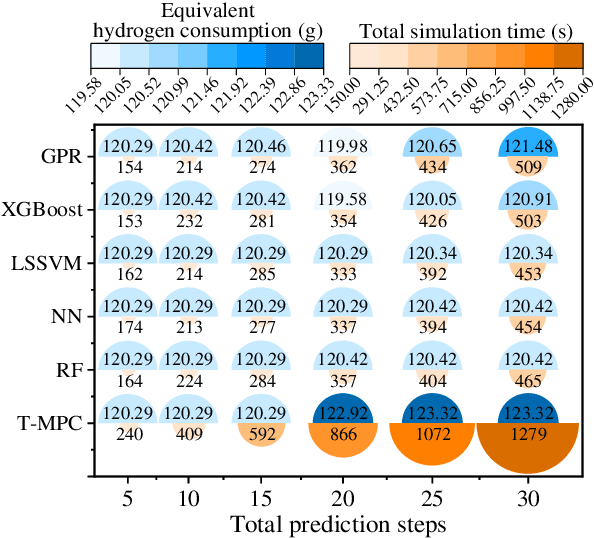
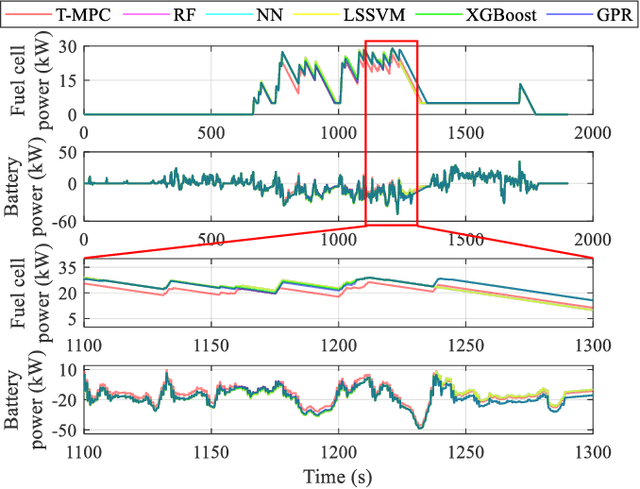
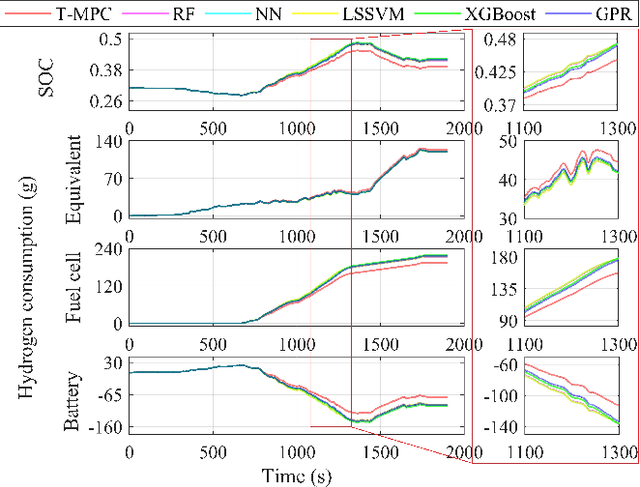
The multi-source electromechanical coupling makes the energy management of fuel cell electric vehicles (FCEVs) relatively nonlinear and complex especially in the types of 4-wheel-drive (4WD) FCEVs. Accurate state observing for complicated nonlinear system is the basis for fantastic energy managing in FCEVs. Aiming at releasing the energy-saving potential of FCEVs, a novel learning-based robust model predictive control (LRMPC) strategy is proposed for a 4WD FCEV, contributing to suitable power distribution among multiple energy sources. The well-designed strategy based on machine learning (ML) translates the knowledge of the nonlinear system to the explicit controlling scheme with superior robust performance. To start with, ML methods with high regression accuracy and superior generalization ability are trained offline to establish the precise state observer for SOC. Then, explicit data tables for SOC generated by state observer are used for grabbing accurate state changing, whose input features include the vehicle status and the states of vehicle components. To be specific, the vehicle velocity estimation for providing future speed reference is constructed by deep forest. Next, the components including explicit data tables and vehicle velocity estimation are combined with model predictive control (MPC) to release the state-of-the-art energy-saving ability for the multi-freedom system in FCEVs, whose name is LRMPC. At last, the detailed assessment is performed in simulation test to validate the advancing performance of LRMPC. The corresponding results highlight the optimal control effect in energy-saving potential and strong real-time application ability of LRMPC.
Nonparametric Embeddings of Sparse High-Order Interaction Events
Jul 08, 2022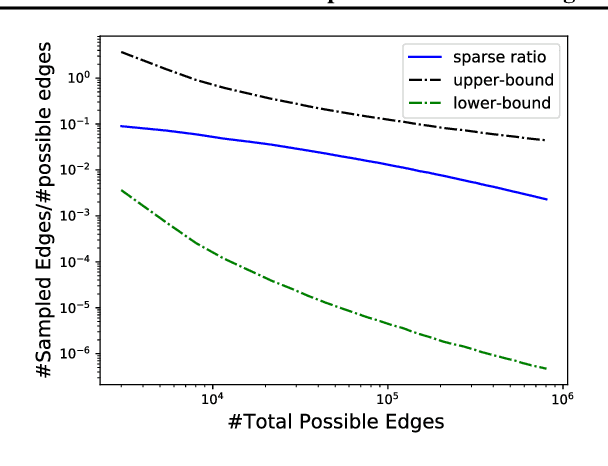
High-order interaction events are common in real-world applications. Learning embeddings that encode the complex relationships of the participants from these events is of great importance in knowledge mining and predictive tasks. Despite the success of existing approaches, e.g. Poisson tensor factorization, they ignore the sparse structure underlying the data, namely the occurred interactions are far less than the possible interactions among all the participants. In this paper, we propose Nonparametric Embeddings of Sparse High-order interaction events (NESH). We hybridize a sparse hypergraph (tensor) process and a matrix Gaussian process to capture both the asymptotic structural sparsity within the interactions and nonlinear temporal relationships between the participants. We prove strong asymptotic bounds (including both a lower and an upper bound) of the sparsity ratio, which reveals the asymptotic properties of the sampled structure. We use batch-normalization, stick-breaking construction, and sparse variational GP approximations to develop an efficient, scalable model inference algorithm. We demonstrate the advantage of our approach in several real-world applications.
Infinite-Fidelity Coregionalization for Physical Simulation
Jul 01, 2022
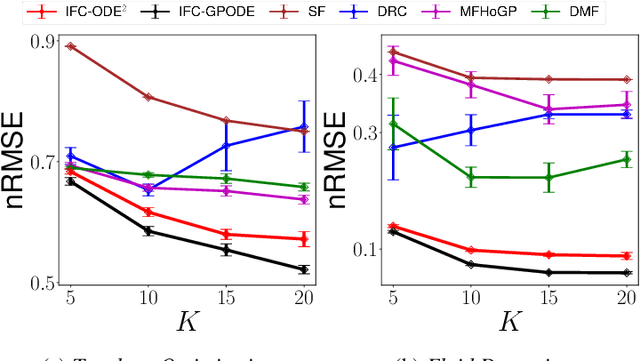
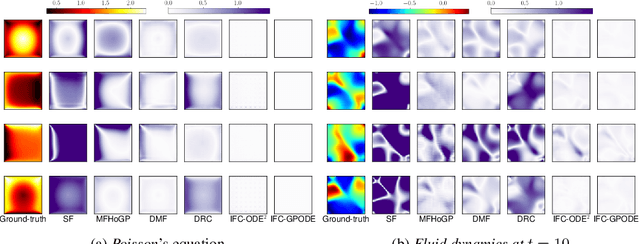
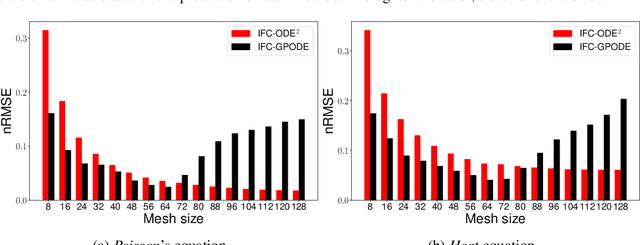
Multi-fidelity modeling and learning are important in physical simulation-related applications. It can leverage both low-fidelity and high-fidelity examples for training so as to reduce the cost of data generation while still achieving good performance. While existing approaches only model finite, discrete fidelities, in practice, the fidelity choice is often continuous and infinite, which can correspond to a continuous mesh spacing or finite element length. In this paper, we propose Infinite Fidelity Coregionalization (IFC). Given the data, our method can extract and exploit rich information within continuous, infinite fidelities to bolster the prediction accuracy. Our model can interpolate and/or extrapolate the predictions to novel fidelities, which can be even higher than the fidelities of training data. Specifically, we introduce a low-dimensional latent output as a continuous function of the fidelity and input, and multiple it with a basis matrix to predict high-dimensional solution outputs. We model the latent output as a neural Ordinary Differential Equation (ODE) to capture the complex relationships within and integrate information throughout the continuous fidelities. We then use Gaussian processes or another ODE to estimate the fidelity-varying bases. For efficient inference, we reorganize the bases as a tensor, and use a tensor-Gaussian variational posterior to develop a scalable inference algorithm for massive outputs. We show the advantage of our method in several benchmark tasks in computational physics.
A Self-Guided Framework for Radiology Report Generation
Jun 19, 2022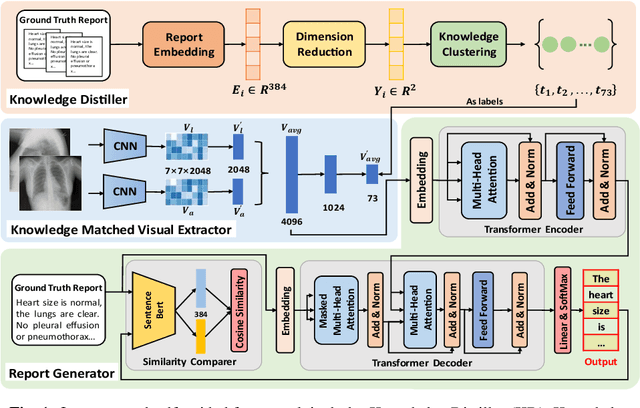
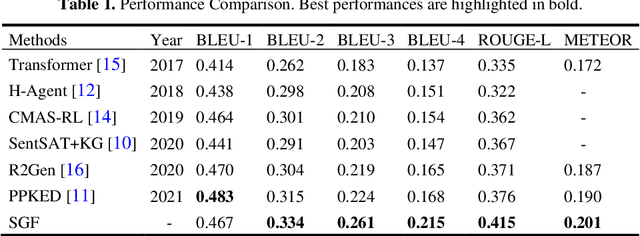
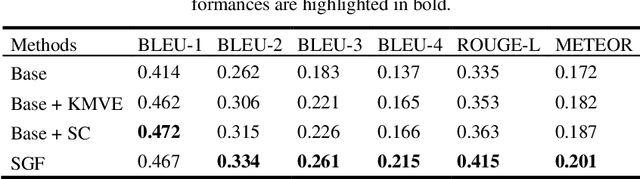
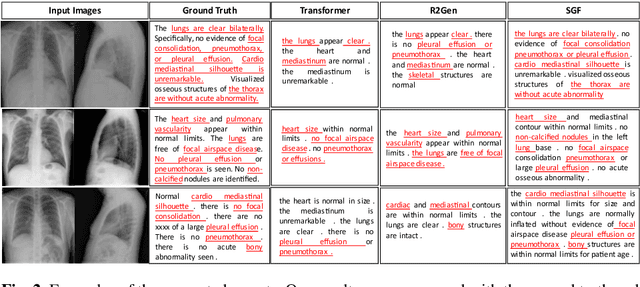
Automatic radiology report generation is essential to computer-aided diagnosis. Through the success of image captioning, medical report generation has been achievable. However, the lack of annotated disease labels is still the bottleneck of this area. In addition, the image-text data bias problem and complex sentences make it more difficult to generate accurate reports. To address these gaps, we pre-sent a self-guided framework (SGF), a suite of unsupervised and supervised deep learning methods to mimic the process of human learning and writing. In detail, our framework obtains the domain knowledge from medical reports with-out extra disease labels and guides itself to extract fined-grain visual features as-sociated with the text. Moreover, SGF successfully improves the accuracy and length of medical report generation by incorporating a similarity comparison mechanism that imitates the process of human self-improvement through compar-ative practice. Extensive experiments demonstrate the utility of our SGF in the majority of cases, showing its superior performance over state-of-the-art meth-ods. Our results highlight the capacity of the proposed framework to distinguish fined-grained visual details between words and verify its advantage in generating medical reports.
Meta-Learning with Adjoint Methods
Oct 16, 2021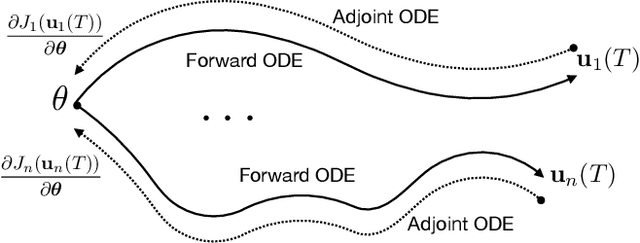
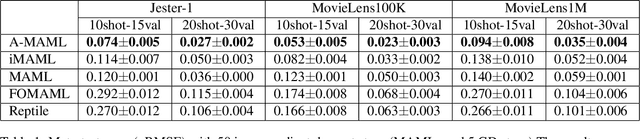
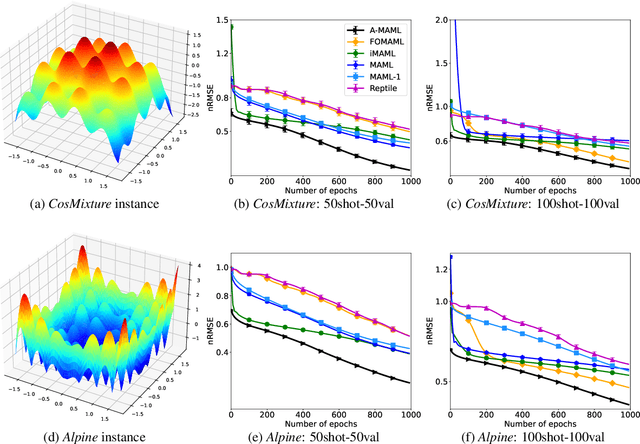
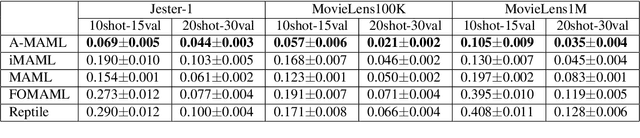
Model Agnostic Meta-Learning (MAML) is widely used to find a good initialization for a family of tasks. Despite its success, a critical challenge in MAML is to calculate the gradient w.r.t the initialization of a long training trajectory for the sampled tasks, because the computation graph can rapidly explode and the computational cost is very expensive. To address this problem, we propose Adjoint MAML (A-MAML). We view gradient descent in the inner optimization as the evolution of an Ordinary Differential Equation (ODE). To efficiently compute the gradient of the validation loss w.r.t the initialization, we use the adjoint method to construct a companion, backward ODE. To obtain the gradient w.r.t the initialization, we only need to run the standard ODE solver twice -- one is forward in time that evolves a long trajectory of gradient flow for the sampled task; the other is backward and solves the adjoint ODE. We need not create or expand any intermediate computational graphs, adopt aggressive approximations, or impose proximal regularizers in the training loss. Our approach is cheap, accurate, and adaptable to different trajectory lengths. We demonstrate the advantage of our approach in both synthetic and real-world meta-learning tasks.