 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effective Router for Vision-Language Model Selection
Jun 08, 2026Vision-language models (VLMs) with varying performance and resource requirements are widely deployed, making it difficult for users to select the most appropriate one among numerous VLM candidates. Existing work reveals the performance paradox phenomenon in language models and focuses on routing methods to solve it. However, developing a router for VLM selection is still a critical yet challenging problem, which primarily faces: 1) lack of specialized data, 2) ineffective feature representation, and 3) rigid model space and costly adaptation. In this paper, we construct a multimodal dataset for VLM selection, containing the outputs of seven mainstream VLMs on 32,626 unique image-text queries. We then propose ARMS, a router for VLM selection. ARMS enhances input signals with VLM profiles, employs a simple but effective architecture to improve representations of queries and VLM capabilities. To improve ARMS' adaptation to new VLMs, we propose two extension training strategies: incremental training and independent training. Experimental results on both in-distribution and out-of-distribution test sets demonstrate the effectiveness of ARMS. In particular, using our training strategy, ARMs (only 800M in size) can adapt to a broader VLM space and defeat commercial models like GPT-4o that are hundreds of times larger in scale. Our code, models, and datasets are available in the anonymous repository.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
Bridging Data Barriers among Participants: Assessing the Potential of Geoenergy through Federated Learning
Apr 29, 2024Machine learning algorithms emerge as a promising approach in energy fields, but its practical is hindered by data barriers, stemming from high collection costs and privacy concerns. This study introduces a novel federated learning (FL) framework based on XGBoost models, enabling safe collaborative modeling with accessible yet concealed data from multiple parties. Hyperparameter tuning of the models is achieved through Bayesian Optimization. To ascertain the merits of the proposed FL-XGBoost method, a comparative analysis is conducted between separate and centralized models to address a classical binary classification problem in geoenergy sector. The results reveal that the proposed FL framework strikes an optimal balance between privacy and accuracy. FL models demonstrate superior accuracy and generalization capabilities compared to separate models, particularly for participants with limited data or low correlation features and offers significant privacy benefits compared to centralized model. The aggregated optimization approach within the FL agreement proves effective in tuning hyperparameters. This study opens new avenues for assessing unconventional reservoirs through collaborative and privacy-preserving FL techniques.
Accelerate CU Partition in HEVC using Large-Scale Convolutional Neural Network
Sep 23, 2018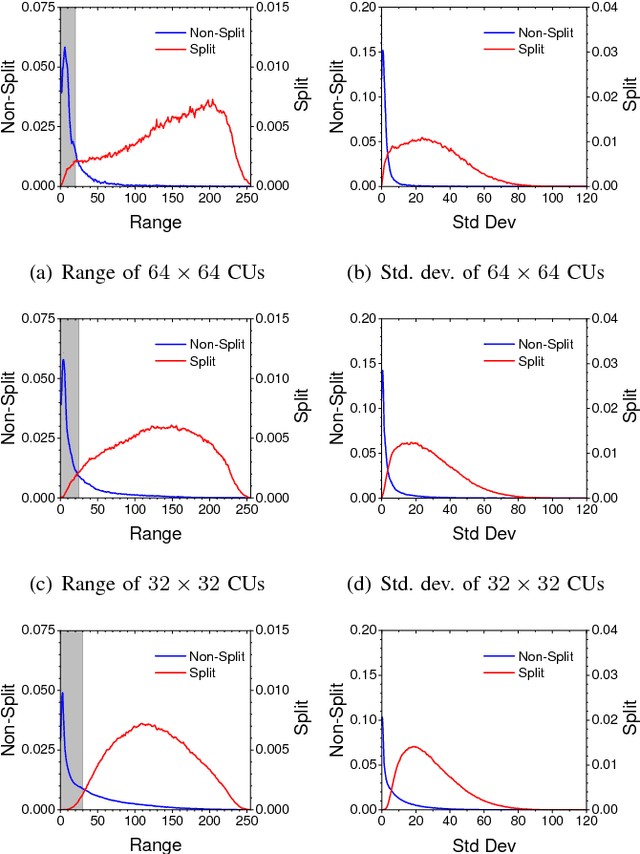
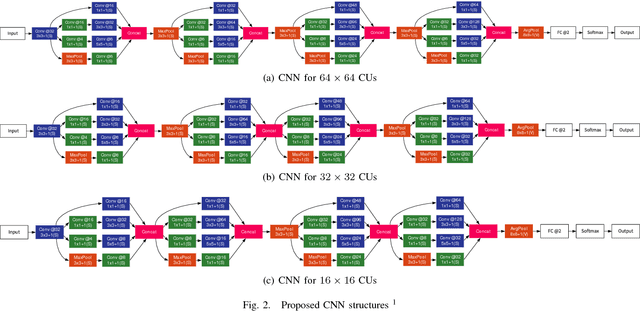
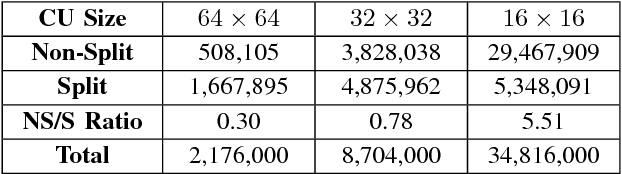
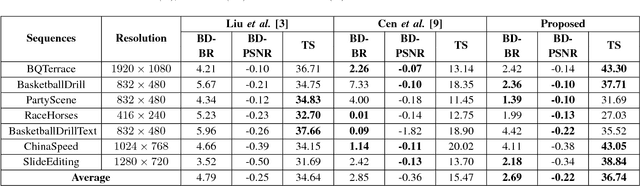
High efficiency video coding (HEVC) suffers high encoding computational complexity, partly attributed to the rate-distortion optimization quad-tree search in CU partition decision. Therefore, we propose a novel two-stage CU partition decision approach in HEVC intra-mode. In the proposed approach, CNN-based algorithm is designed to decide CU partition mode precisely in three depths. In order to alleviate computational complexity further, an auxiliary earl-termination mechanism is also proposed to filter obvious homogeneous CUs out of the subsequent CNN-based algorithm. Experimental results show that the proposed approach achieves about 37% encoding time saving on average and insignificant BD-Bitrate rise compared with the original HEVC encoder.