 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFC-MIR: A Mobile Screen Awareness Framework for Intent-Aware Recommendation based on Frame-Compressed Multimodal Trajectory Reasoning
Dec 22, 2025Identifying user intent from mobile UI operation trajectories is critical for advancing UI understanding and enabling task automation agents. While Multimodal Large Language Models (MLLMs) excel at video understanding tasks, their real-time mobile deployment is constrained by heavy computational costs and inefficient redundant frame processing. To address these issues, we propose the FC-MIR framework: leveraging keyframe sampling and adaptive concatenation, it cuts visual redundancy to boost inference efficiency, while integrating state-of-the-art closed-source MLLMs or fine-tuned models (e.g., Qwen3-VL) for trajectory summarization and intent prediction. We further expand task scope to explore generating post-prediction operations and search suggestions, and introduce a fine-grained metric to evaluate the practical utility of summaries, predictions, and suggestions. For rigorous assessment, we construct a UI trajectory dataset covering scenarios from UI-Agents (Agent-I) and real user interactions (Person-I). Experimental results show our compression method retains performance at 50%-60% compression rates; both closed-source and fine-tuned MLLMs demonstrate strong intent summarization, supporting potential lightweight on-device deployment. However, MLLMs still struggle with useful and "surprising" suggestions, leaving room for improvement. Finally, we deploy the framework in a real-world setting, integrating UI perception and UI-Agent proxies to lay a foundation for future progress in this field.
RCLane: Relay Chain Prediction for Lane Detection
Jul 19, 2022
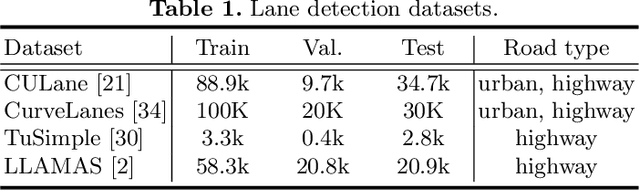
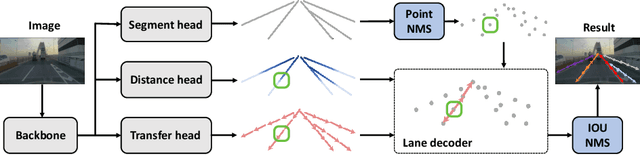
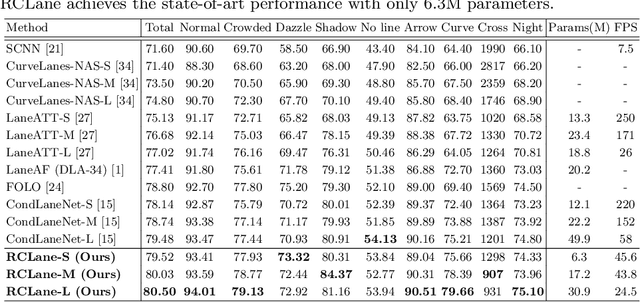
Lane detection is an important component of many real-world autonomous systems. Despite a wide variety of lane detection approaches have been proposed, reporting steady benchmark improvements over time, lane detection remains a largely unsolved problem. This is because most of the existing lane detection methods either treat the lane detection as a dense prediction or a detection task, few of them consider the unique topologies (Y-shape, Fork-shape, nearly horizontal lane) of the lane markers, which leads to sub-optimal solution. In this paper, we present a new method for lane detection based on relay chain prediction. Specifically, our model predicts a segmentation map to classify the foreground and background region. For each pixel point in the foreground region, we go through the forward branch and backward branch to recover the whole lane. Each branch decodes a transfer map and a distance map to produce the direction moving to the next point, and how many steps to progressively predict a relay station (next point). As such, our model is able to capture the keypoints along the lanes. Despite its simplicity, our strategy allows us to establish new state-of-the-art on four major benchmarks including TuSimple, CULane, CurveLanes and LLAMAS.