 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanoNet: Real-Time Polyp Segmentation in Video Capsule Endoscopy and Colonoscopy
Apr 22, 2021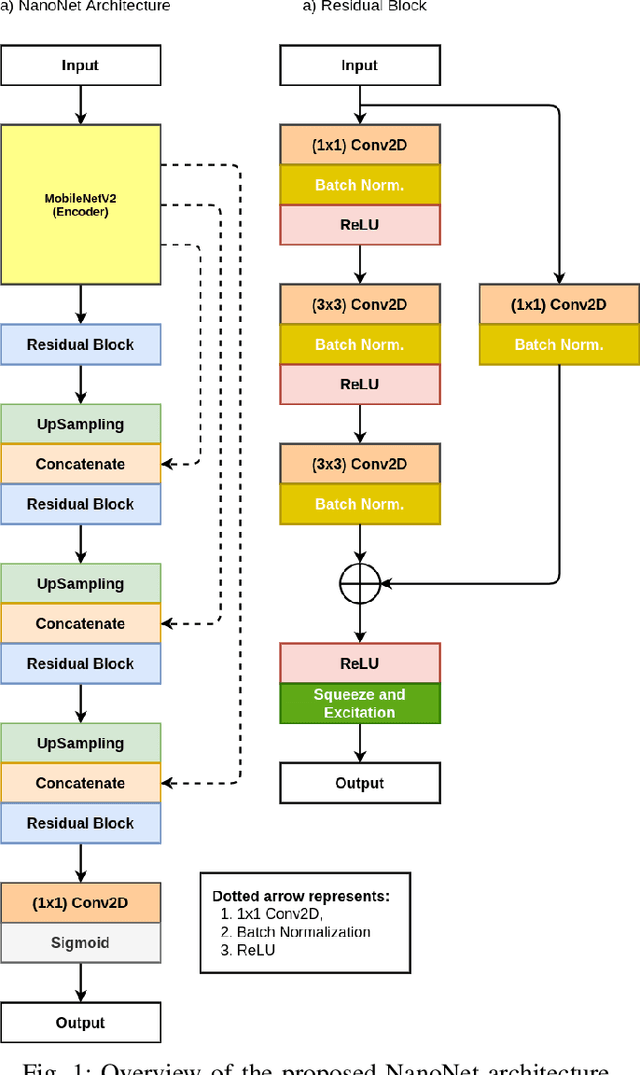
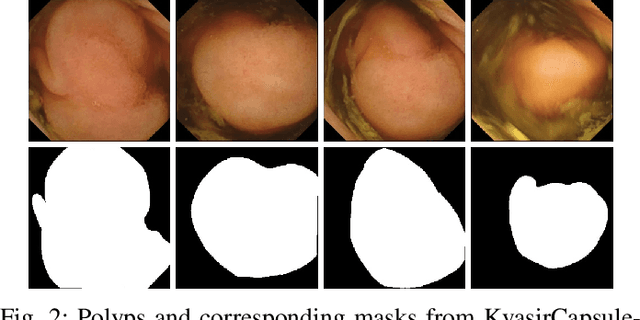
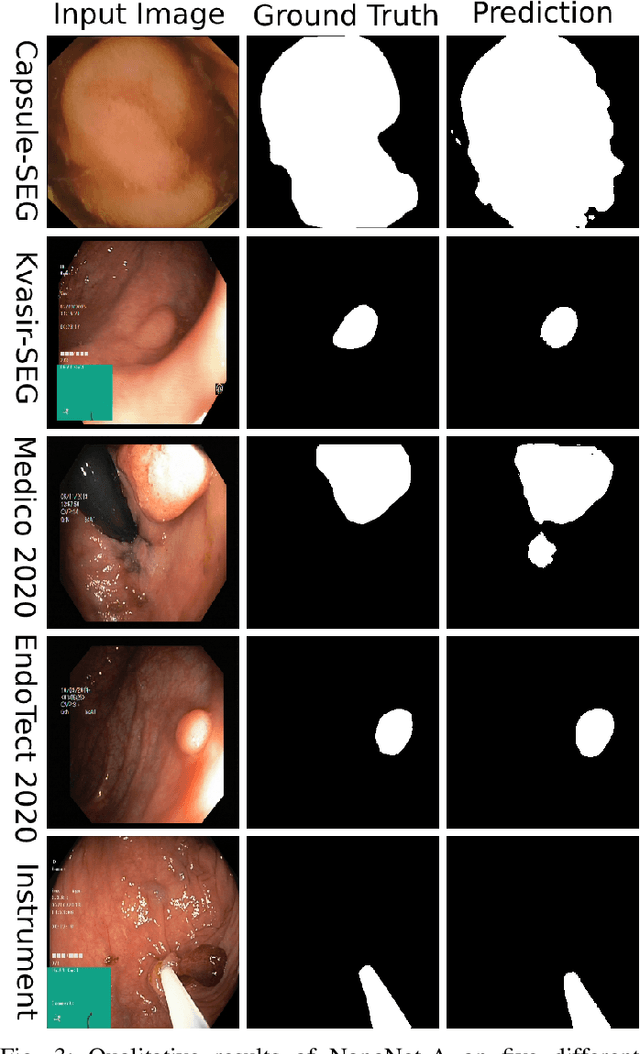

Deep learning in gastrointestinal endoscopy can assist to improve clinical performance and be helpful to assess lesions more accurately. To this extent, semantic segmentation methods that can perform automated real-time delineation of a region-of-interest, e.g., boundary identification of cancer or precancerous lesions, can benefit both diagnosis and interventions. However, accurate and real-time segmentation of endoscopic images is extremely challenging due to its high operator dependence and high-definition image quality. To utilize automated methods in clinical settings, it is crucial to design lightweight models with low latency such that they can be integrated with low-end endoscope hardware devices. In this work, we propose NanoNet, a novel architecture for the segmentation of video capsule endoscopy and colonoscopy images. Our proposed architecture allows real-time performance and has higher segmentation accuracy compared to other more complex ones. We use video capsule endoscopy and standard colonoscopy datasets with polyps, and a dataset consisting of endoscopy biopsies and surgical instruments, to evaluate the effectiveness of our approach. Our experiments demonstrate the increased performance of our architecture in terms of a trade-off between model complexity, speed, model parameters, and metric performances. Moreover, the resulting model size is relatively tiny, with only nearly 36,000 parameters compared to traditional deep learning approaches having millions of parameters.
Multi-class motion-based semantic segmentation for ureteroscopy and laser lithotripsy
Apr 02, 2021
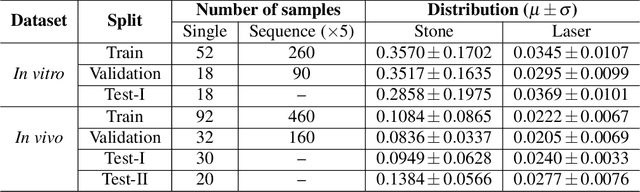
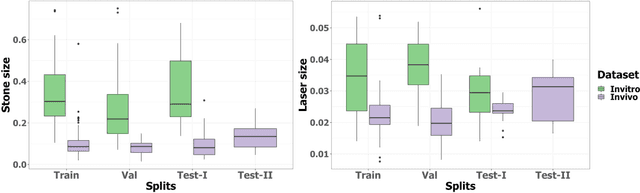
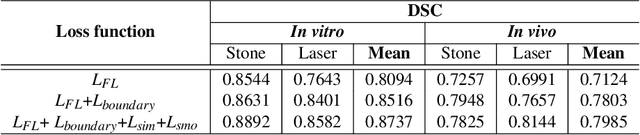
Kidney stones represent a considerable burden for public health-care systems. Ureteroscopy with laser lithotripsy has evolved as the most commonly used technique for the treatment of kidney stones. Automated segmentation of kidney stones and laser fiber is an important initial step to performing any automated quantitative analysis of the stones, particularly stone-size estimation, that helps the surgeon decide if the stone requires more fragmentation. Factors such as turbid fluid inside the cavity, specularities, motion blur due to kidney movements and camera motion, bleeding, and stone debris impact the quality of vision within the kidney and lead to extended operative times. To the best of our knowledge, this is the first attempt made towards multi-class segmentation in ureteroscopy and laser lithotripsy data. We propose an end-to-end CNN-based framework for the segmentation of stones and laser fiber. The proposed approach utilizes two sub-networks: HybResUNet, a version of residual U-Net, that uses residual connections in the encoder path of U-Net and a DVFNet that generates DVF predictions which are then used to prune the prediction maps. We also present ablation studies that combine dilated convolutions, recurrent and residual connections, ASPP and attention gate. We propose a compound loss function that improves our segmentation performance. We have also provided an ablation study to determine the optimal data augmentation strategy. Our qualitative and quantitative results illustrate that our proposed method outperforms SOTA methods such as UNet and DeepLabv3+ showing an improvement of 5.2% and 15.93%, respectively, for the combined mean of DSC and JI in our invivo test dataset. We also show that our proposed model generalizes better on a new clinical dataset showing a mean improvement of 25.4%, 20%, and 11% over UNet, HybResUNet, and DeepLabv3+, respectively, for the same metric.
FANet: A Feedback Attention Network for Improved Biomedical Image Segmentation
Mar 31, 2021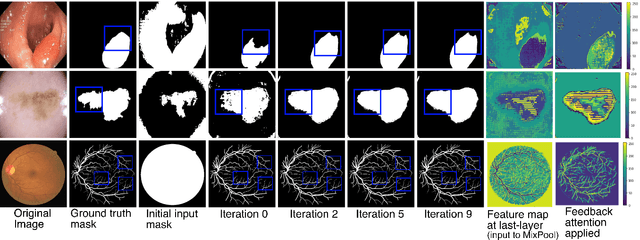
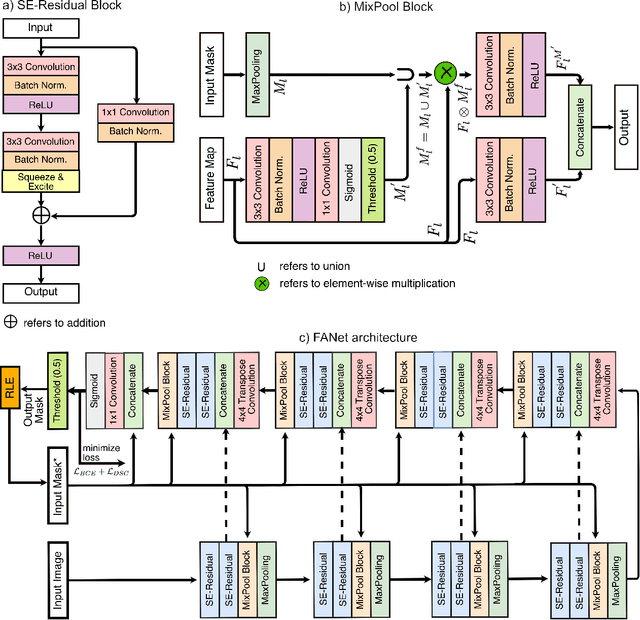
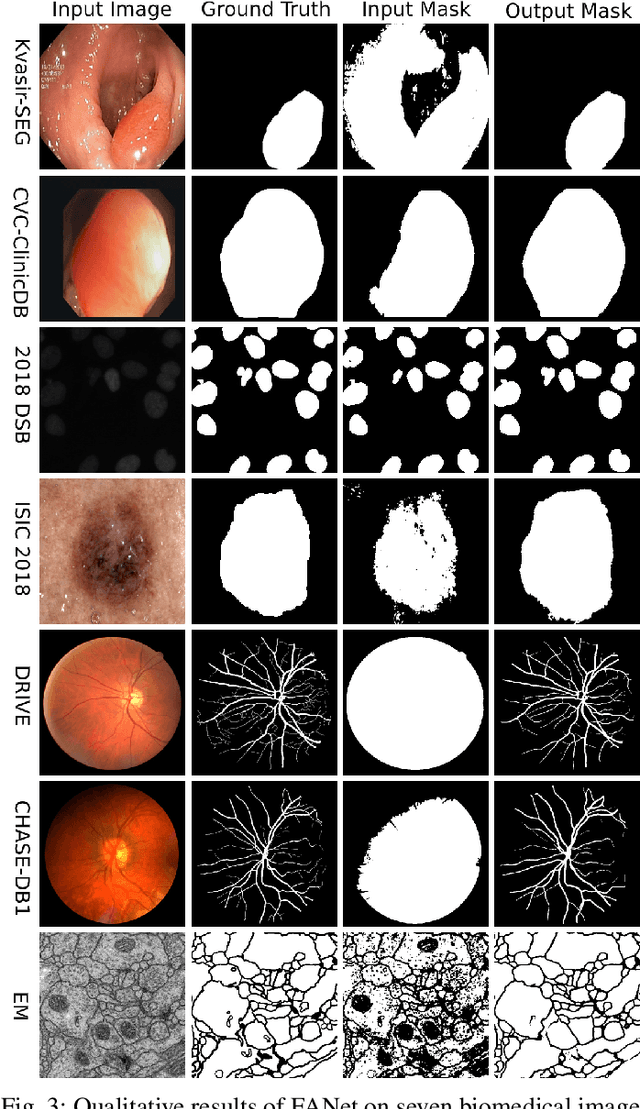
With the increase in available large clinical and experimental datasets, there has been substantial amount of work being done on addressing the challenges in the area of biomedical image analysis. Image segmentation, which is crucial for any quantitative analysis, has especially attracted attention. Recent hardware advancement has led to the success of deep learning approaches. However, although deep learning models are being trained on large datasets, existing methods do not use the information from different learning epochs effectively. In this work, we leverage the information of each training epoch to prune the prediction maps of the subsequent epochs. We propose a novel architecture called feedback attention network (FANet) that unifies the previous epoch mask with the feature map of the current training epoch. The previous epoch mask is then used to provide a hard attention to the learnt feature maps at different convolutional layers. The network also allows to rectify the predictions in an iterative fashion during the test time. We show that our proposed feedback attention model provides a substantial improvement on most segmentation metrics tested on seven publicly available biomedical imaging datasets demonstrating the effectiveness of the proposed FANet.
Assessing YOLACT++ for real time and robust instance segmentation of medical instruments in endoscopic procedures
Mar 30, 2021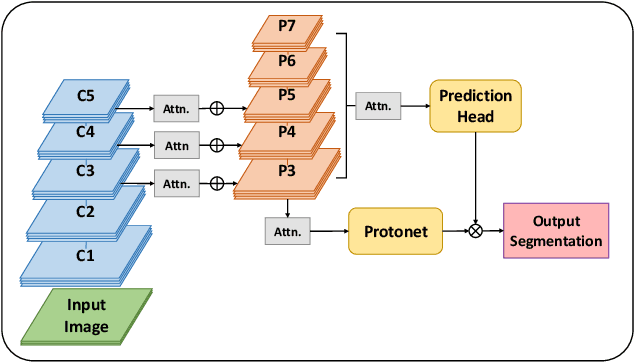
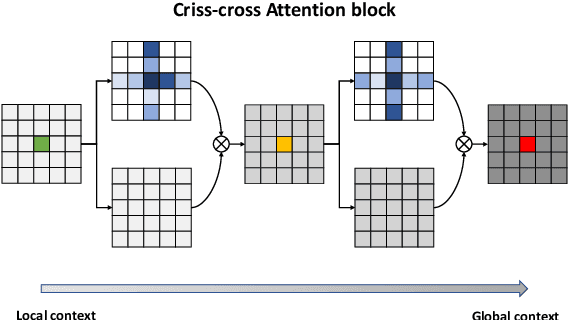
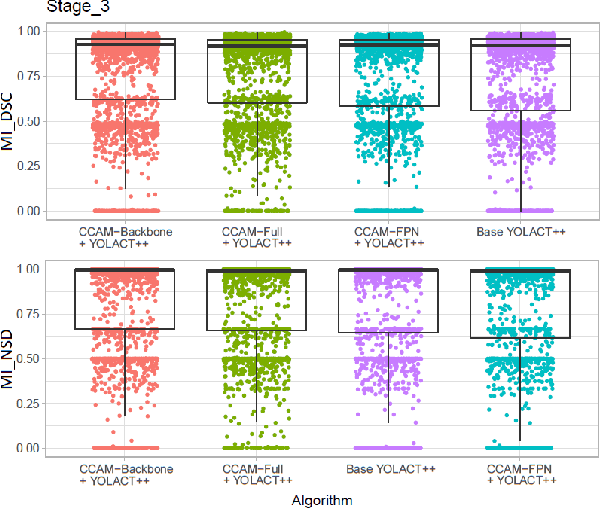
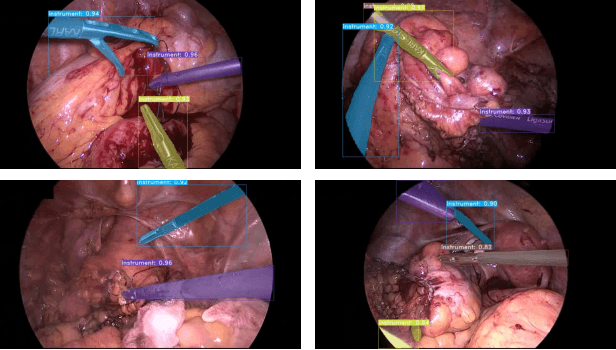
Image-based tracking of laparoscopic instruments plays a fundamental role in computer and robotic-assisted surgeries by aiding surgeons and increasing patient safety. Computer vision contests, such as the Robust Medical Instrument Segmentation (ROBUST-MIS) Challenge, seek to encourage the development of robust models for such purposes, providing large, diverse, and annotated datasets. To date, most of the existing models for instance segmentation of medical instruments were based on two-stage detectors, which provide robust results but are nowhere near to the real-time (5 frames-per-second (fps)at most). However, in order for the method to be clinically applicable, real-time capability is utmost required along with high accuracy. In this paper, we propose the addition of attention mechanisms to the YOLACT architecture that allows real-time instance segmentation of instrument with improved accuracy on the ROBUST-MIS dataset. Our proposed approach achieves competitive performance compared to the winner ofthe 2019 ROBUST-MIS challenge in terms of robustness scores,obtaining 0.313 MI_DSC and 0.338 MI_NSD, while achieving real-time performance (37 fps)
DDANet: Dual Decoder Attention Network for Automatic Polyp Segmentation
Dec 30, 2020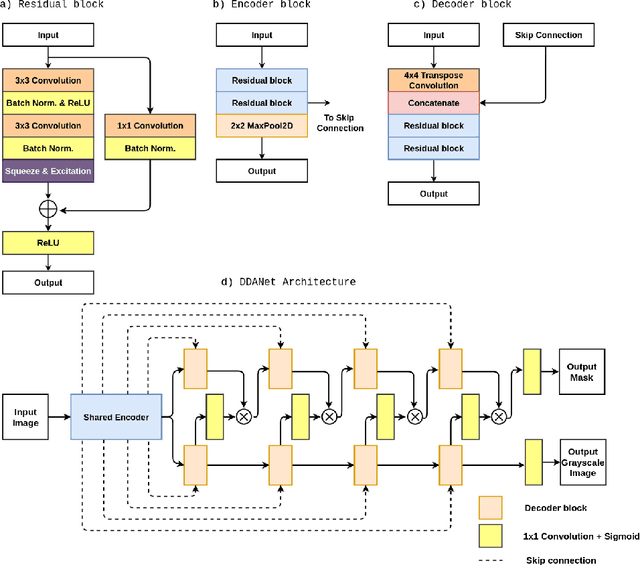
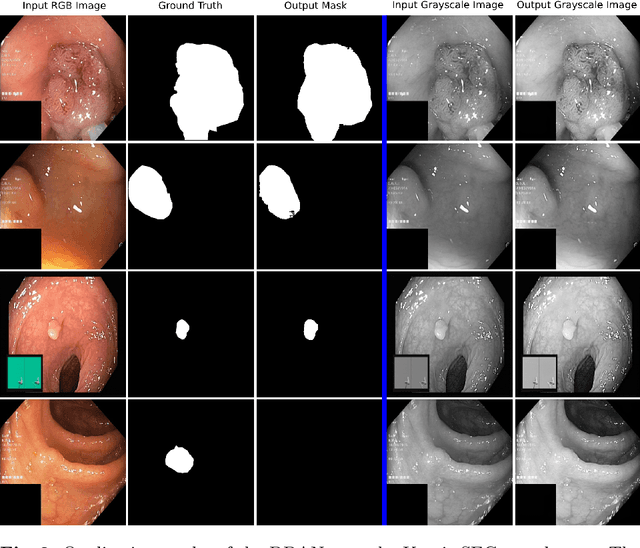
Colonoscopy is the gold standard for examination and detection of colorectal polyps. Localization and delineation of polyps can play a vital role in treatment (e.g., surgical planning) and prognostic decision making. Polyp segmentation can provide detailed boundary information for clinical analysis. Convolutional neural networks have improved the performance in colonoscopy. However, polyps usually possess various challenges, such as intra-and inter-class variation and noise. While manual labeling for polyp assessment requires time from experts and is prone to human error (e.g., missed lesions), an automated, accurate, and fast segmentation can improve the quality of delineated lesion boundaries and reduce missed rate. The Endotect challenge provides an opportunity to benchmark computer vision methods by training on the publicly available Hyperkvasir and testing on a separate unseen dataset. In this paper, we propose a novel architecture called ``DDANet'' based on a dual decoder attention network. Our experiments demonstrate that the model trained on the Kvasir-SEG dataset and tested on an unseen dataset achieves a dice coefficient of 0.7874, mIoU of 0.7010, recall of 0.7987, and a precision of 0.8577, demonstrating the generalization ability of our model.
Unsupervised Adversarial Domain Adaptation For Barrett's Segmentation
Dec 09, 2020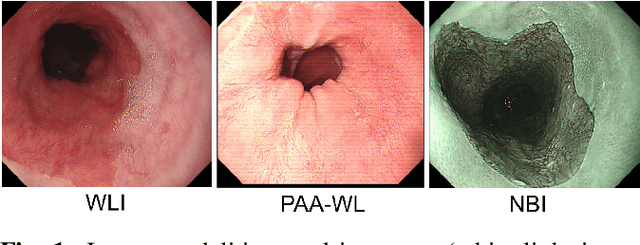

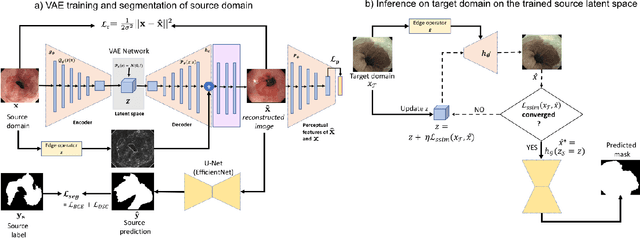

Barrett's oesophagus (BE) is one of the early indicators of esophageal cancer. Patients with BE are monitored and undergo ablation therapies to minimise the risk, thereby making it eminent to identify the BE area precisely. Automated segmentation can help clinical endoscopists to assess and treat BE area more accurately. Endoscopy imaging of BE can include multiple modalities in addition to the conventional white light (WL) modality. Supervised models require large amount of manual annotations incorporating all data variability in the training data. However, it becomes cumbersome, tedious and labour intensive work to generate manual annotations, and additionally modality specific expertise is required. In this work, we aim to alleviate this problem by applying an unsupervised domain adaptation technique (UDA). Here, UDA is trained on white light endoscopy images as source domain and are well-adapted to generalise to produce segmentation on different imaging modalities as target domain, namely narrow band imaging and post acetic-acid WL imaging. Our dataset consists of a total of 871 images consisting of both source and target domains. Our results show that the UDA-based approach outperforms traditional supervised U-Net segmentation by nearly 10% on both Dice similarity coefficient and intersection-over-union.
Real-Time Polyp Detection, Localisation and Segmentation in Colonoscopy Using Deep Learning
Nov 15, 2020
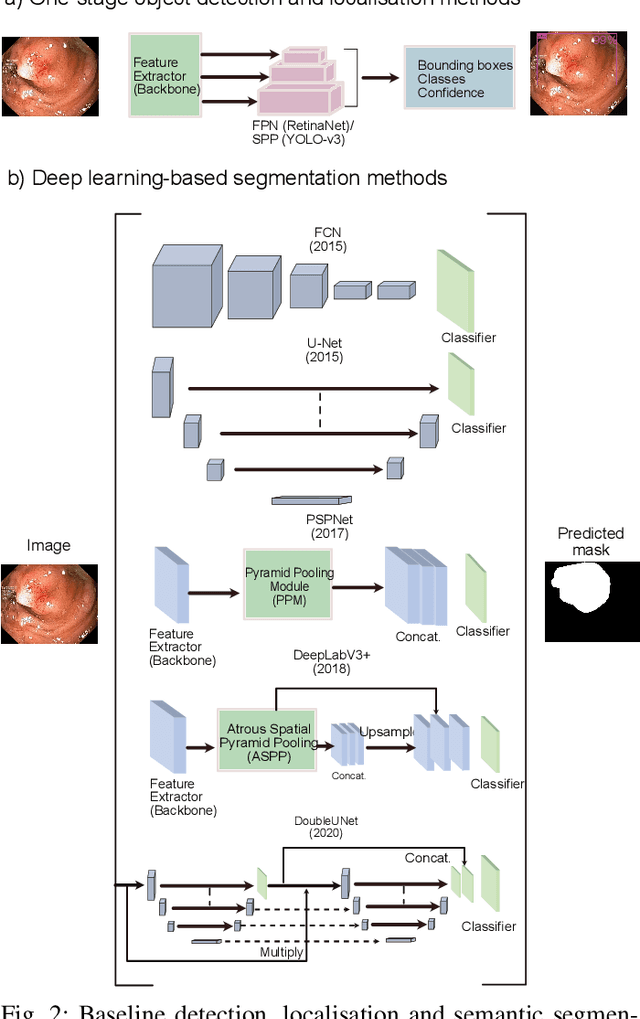
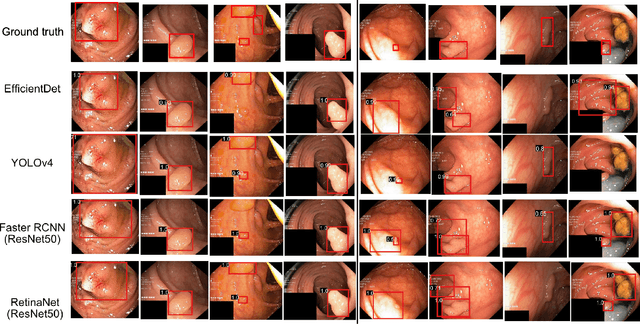

Computer-aided detection, localisation, and segmentation methods can help improve colonoscopy procedures. Even though many methods have been built to tackle automatic detection and segmentation of polyps, benchmarking of state-of-the-art methods still remains an open problem. This is due to the increasing number of researched computer-vision methods that can be applied to polyp datasets. Benchmarking of novel methods can provide a direction to the development of automated polyp detection and segmentation tasks. Furthermore, it ensures that the produced results in the community are reproducible and provide a fair comparison of developed methods. In this paper, we benchmark several recent state-of-the-art methods using Kvasir-SEG, an open-access dataset of colonoscopy images, for polyp detection, localisation, and segmentation evaluating both method accuracy and speed. Whilst, most methods in literature have competitive performance over accuracy, we show that YOLOv4 with a Darknet53 backbone and cross-stage-partial connections achieved a better trade-off between an average precision of 0.8513 and mean IoU of 0.8025, and the fastest speed of 48 frames per second for the detection and localisation task. Likewise, UNet with a ResNet34 backbone achieved the highest dice coefficient of 0.8757 and the best average speed of 35 frames per second for the segmentation task. Our comprehensive comparison with various state-of-the-art methods reveal the importance of benchmarking the deep learning methods for automated real-time polyp identification and delineations that can potentially transform current clinical practices and minimise miss-detection rates.
A translational pathway of deep learning methods in GastroIntestinal Endoscopy
Oct 12, 2020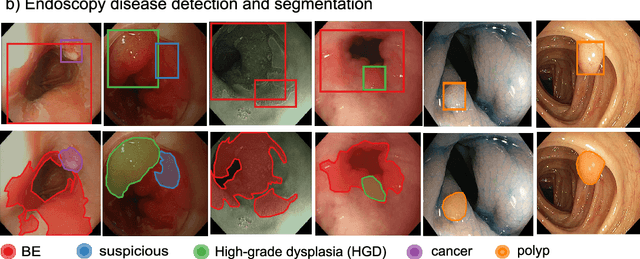
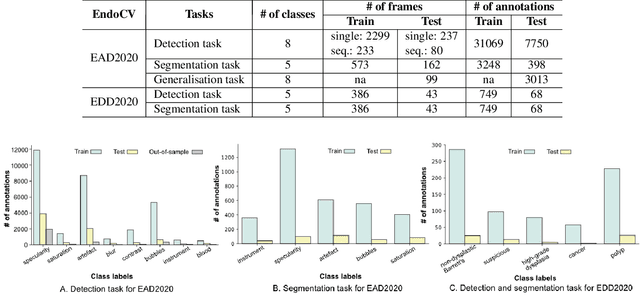
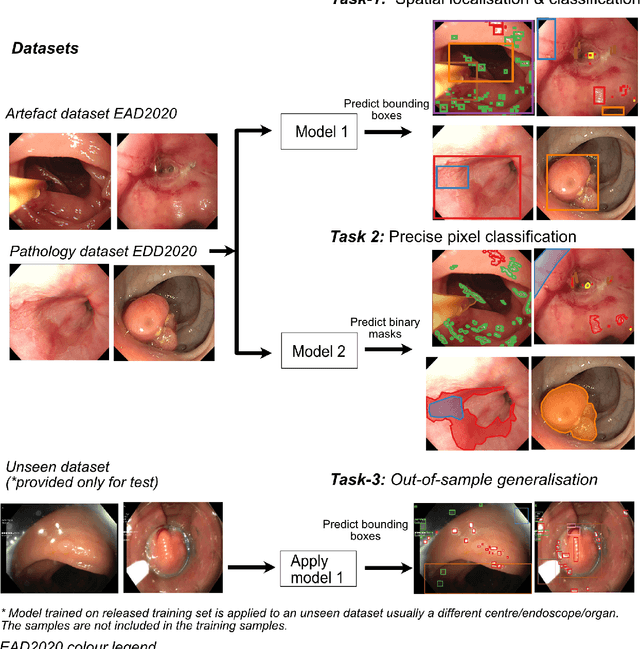
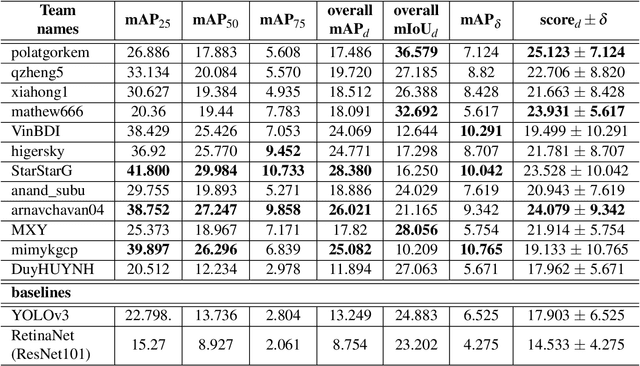
The Endoscopy Computer Vision Challenge (EndoCV) is a crowd-sourcing initiative to address eminent problems in developing reliable computer aided detection and diagnosis endoscopy systems and suggest a pathway for clinical translation of technologies. Whilst endoscopy is a widely used diagnostic and treatment tool for hollow-organs, there are several core challenges often faced by endoscopists, mainly: 1) presence of multi-class artefacts that hinder their visual interpretation, and 2) difficulty in identifying subtle precancerous precursors and cancer abnormalities. Artefacts often affect the robustness of deep learning methods applied to the gastrointestinal tract organs as they can be confused with tissue of interest. EndoCV2020 challenges are designed to address research questions in these remits. In this paper, we present a summary of methods developed by the top 17 teams and provide an objective comparison of state-of-the-art methods and methods designed by the participants for two sub-challenges: i) artefact detection and segmentation (EAD2020), and ii) disease detection and segmentation (EDD2020). Multi-center, multi-organ, multi-class, and multi-modal clinical endoscopy datasets were compiled for both EAD2020 and EDD2020 sub-challenges. An out-of-sample generalisation ability of detection algorithms was also evaluated. Whilst most teams focused on accuracy improvements, only a few methods hold credibility for clinical usability. The best performing teams provided solutions to tackle class imbalance, and variabilities in size, origin, modality and occurrences by exploring data augmentation, data fusion, and optimal class thresholding techniques.
Additive Angular Margin for Few Shot Learning to Classify Clinical Endoscopy Images
Mar 26, 2020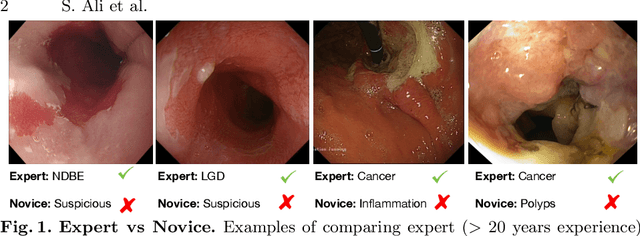
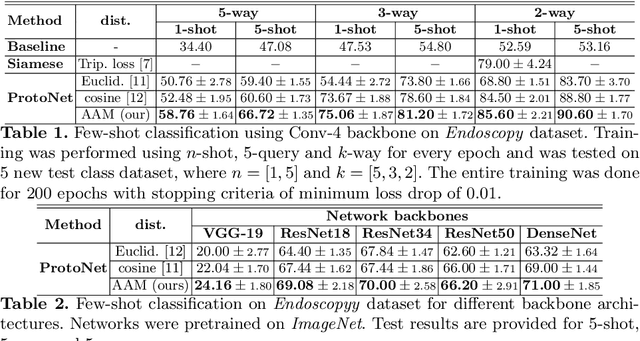
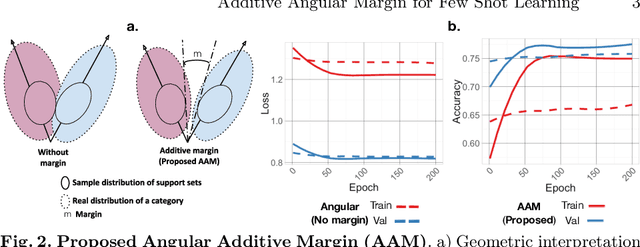
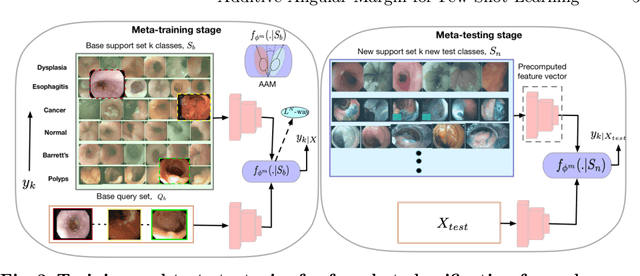
Endoscopy is a widely used imaging modality to diagnose and treat diseases in hollow organs as for example the gastrointestinal tract, the kidney and the liver. However, due to varied modalities and use of different imaging protocols at various clinical centers impose significant challenges when generalising deep learning models. Moreover, the assembly of large datasets from different clinical centers can introduce a huge label bias that renders any learnt model unusable. Also, when using new modality or presence of images with rare patterns, a bulk amount of similar image data and their corresponding labels are required for training these models. In this work, we propose to use a few-shot learning approach that requires less training data and can be used to predict label classes of test samples from an unseen dataset. We propose a novel additive angular margin metric in the framework of prototypical network in few-shot learning setting. We compare our approach to the several established methods on a large cohort of multi-center, multi-organ, and multi-modal endoscopy data. The proposed algorithm outperforms existing state-of-the-art methods.
Endoscopy disease detection challenge 2020
Mar 07, 2020
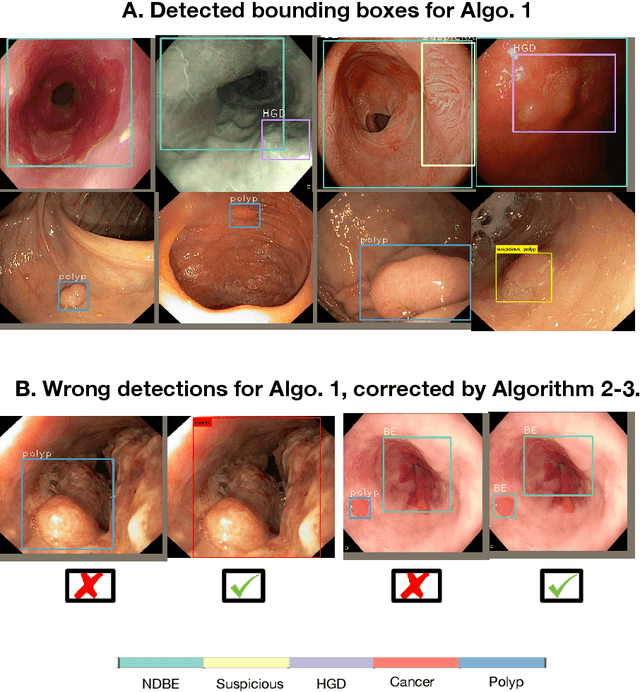
Whilst many technologies are built around endoscopy, there is a need to have a comprehensive dataset collected from multiple centers to address the generalization issues with most deep learning frameworks. What could be more important than disease detection and localization? Through our extensive network of clinical and computational experts, we have collected, curated and annotated gastrointestinal endoscopy video frames. We have released this dataset and have launched disease detection and segmentation challenge EDD2020 https://edd2020.grand-challenge.org to address the limitations and explore new directions. EDD2020 is a crowd sourcing initiative to test the feasibility of recent deep learning methods and to promote research for building robust technologies. In this paper, we provide an overview of the EDD2020 dataset, challenge tasks, evaluation strategies and a short summary of results on test data. A detailed paper will be drafted after the challenge workshop with more detailed analysis of the results.