 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-level instance-group discrimination with pretext-invariant learning for colitis scoring
Jul 11, 2022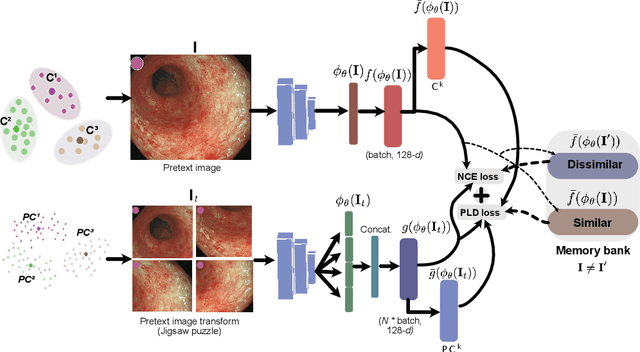
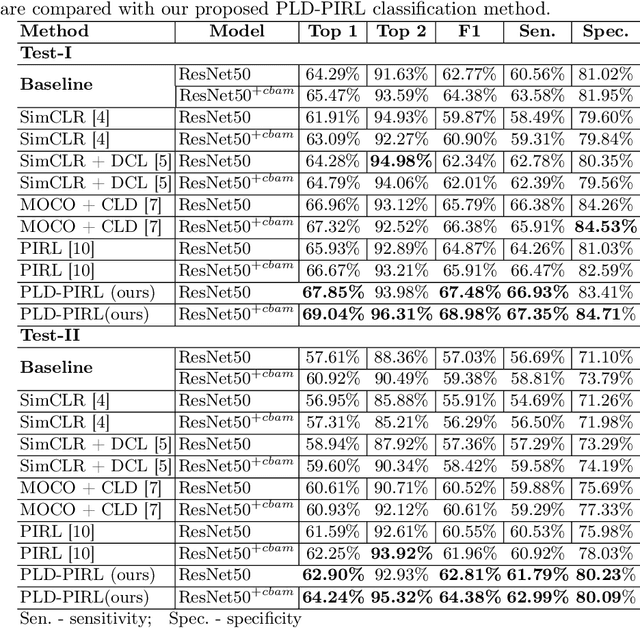
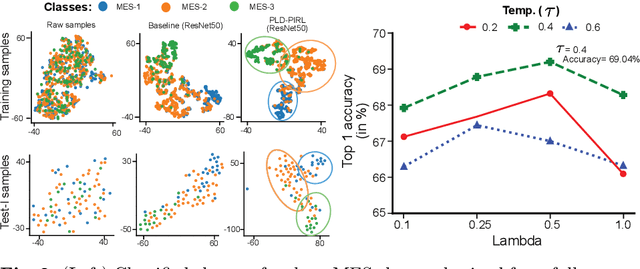
Inflammatory bowel disease (IBD), in particular ulcerative colitis (UC), is graded by endoscopists and this assessment is the basis for risk stratification and therapy monitoring. Presently, endoscopic characterisation is largely operator dependant leading to sometimes undesirable clinical outcomes for patients with IBD. We focus on the Mayo Endoscopic Scoring (MES) system which is widely used but requires the reliable identification of subtle changes in mucosal inflammation. Most existing deep learning classification methods cannot detect these fine-grained changes which make UC grading such a challenging task. In this work, we introduce a novel patch-level instance-group discrimination with pretext-invariant representation learning (PLD-PIRL) for self-supervised learning (SSL). Our experiments demonstrate both improved accuracy and robustness compared to the baseline supervised network and several state-of-the-art SSL methods. Compared to the baseline (ResNet50) supervised classification our proposed PLD-PIRL obtained an improvement of 4.75% on hold-out test data and 6.64% on unseen center test data for top-1 accuracy.
TGANet: Text-guided attention for improved polyp segmentation
May 09, 2022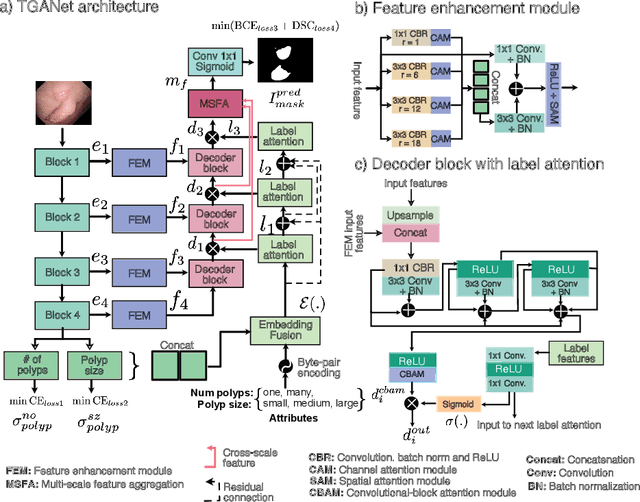
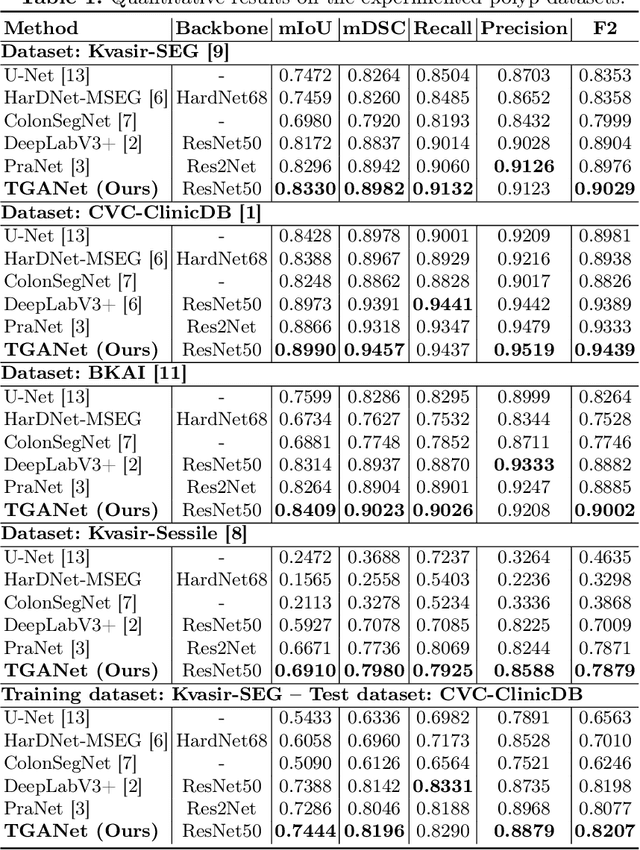
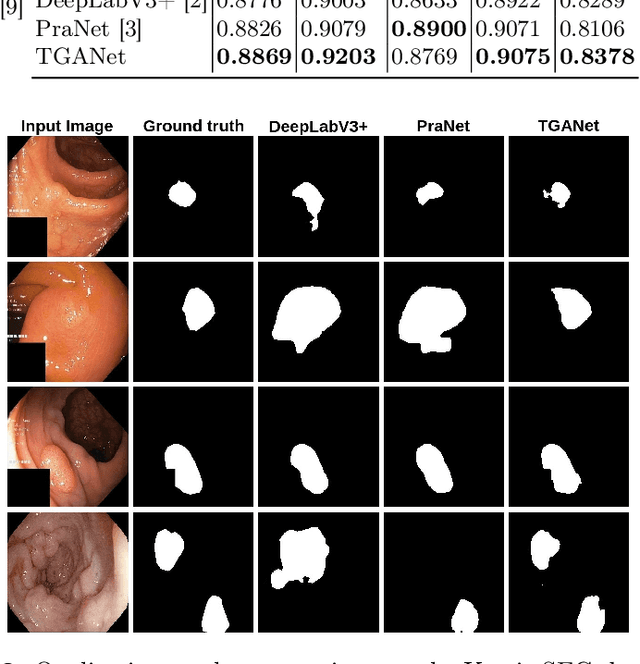
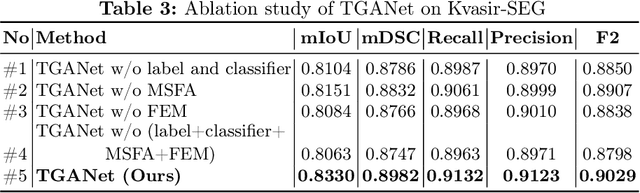
Colonoscopy is a gold standard procedure but is highly operator-dependent. Automated polyp segmentation, a precancerous precursor, can minimize missed rates and timely treatment of colon cancer at an early stage. Even though there are deep learning methods developed for this task, variability in polyp size can impact model training, thereby limiting it to the size attribute of the majority of samples in the training dataset that may provide sub-optimal results to differently sized polyps. In this work, we exploit size-related and polyp number-related features in the form of text attention during training. We introduce an auxiliary classification task to weight the text-based embedding that allows network to learn additional feature representations that can distinctly adapt to differently sized polyps and can adapt to cases with multiple polyps. Our experimental results demonstrate that these added text embeddings improve the overall performance of the model compared to state-of-the-art segmentation methods. We explore four different datasets and provide insights for size-specific improvements. Our proposed text-guided attention network (TGANet) can generalize well to variable-sized polyps in different datasets.
Assessing generalisability of deep learning-based polyp detection and segmentation methods through a computer vision challenge
Feb 24, 2022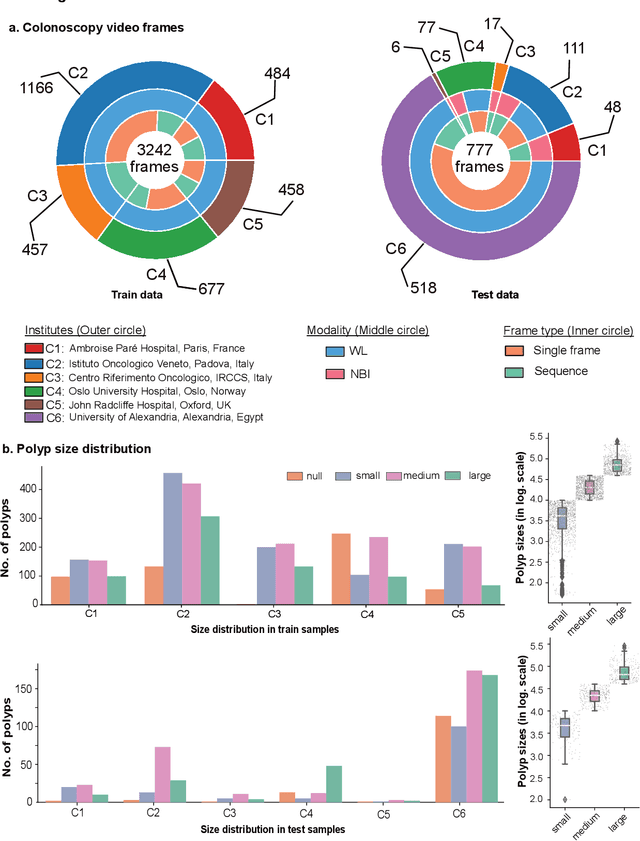
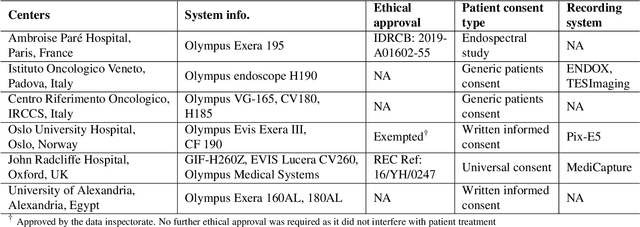
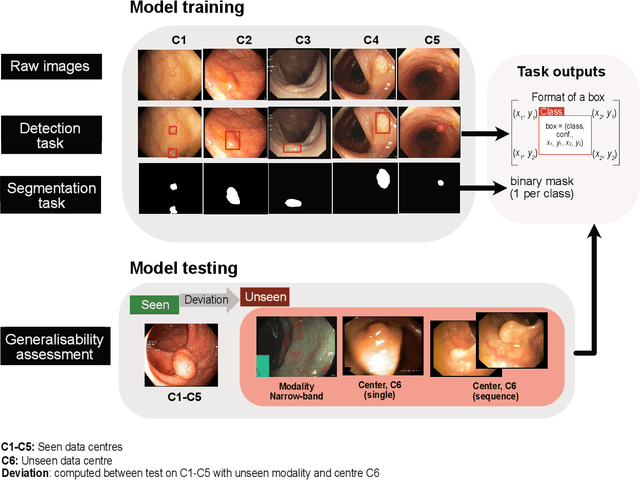
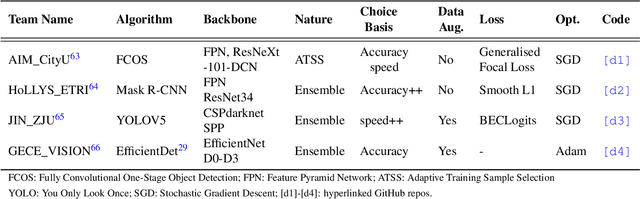
Polyps are well-known cancer precursors identified by colonoscopy. However, variability in their size, location, and surface largely affect identification, localisation, and characterisation. Moreover, colonoscopic surveillance and removal of polyps (referred to as polypectomy ) are highly operator-dependent procedures. There exist a high missed detection rate and incomplete removal of colonic polyps due to their variable nature, the difficulties to delineate the abnormality, the high recurrence rates, and the anatomical topography of the colon. There have been several developments in realising automated methods for both detection and segmentation of these polyps using machine learning. However, the major drawback in most of these methods is their ability to generalise to out-of-sample unseen datasets that come from different centres, modalities and acquisition systems. To test this hypothesis rigorously we curated a multi-centre and multi-population dataset acquired from multiple colonoscopy systems and challenged teams comprising machine learning experts to develop robust automated detection and segmentation methods as part of our crowd-sourcing Endoscopic computer vision challenge (EndoCV) 2021. In this paper, we analyse the detection results of the four top (among seven) teams and the segmentation results of the five top teams (among 16). Our analyses demonstrate that the top-ranking teams concentrated on accuracy (i.e., accuracy > 80% on overall Dice score on different validation sets) over real-time performance required for clinical applicability. We further dissect the methods and provide an experiment-based hypothesis that reveals the need for improved generalisability to tackle diversity present in multi-centre datasets.
GMSRF-Net: An improved generalizability with global multi-scale residual fusion network for polyp segmentation
Nov 20, 2021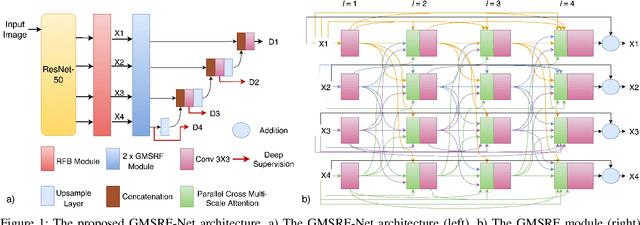
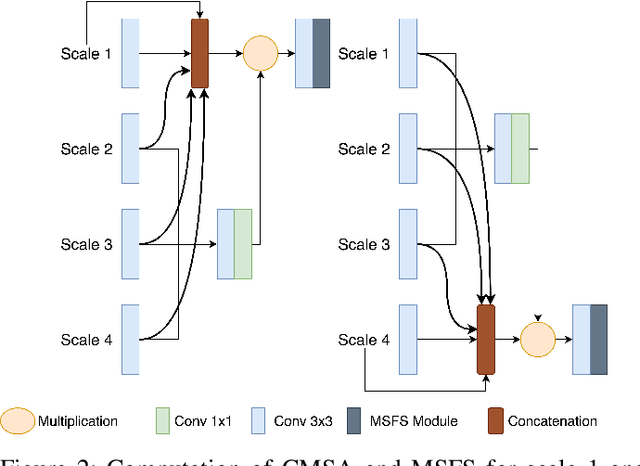
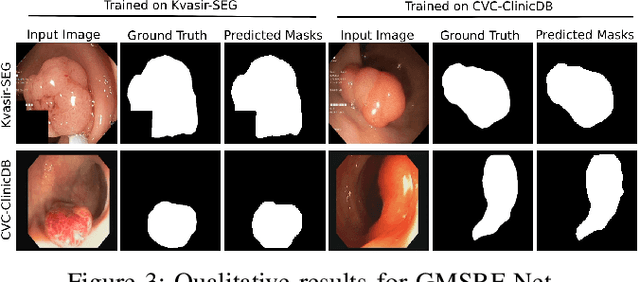
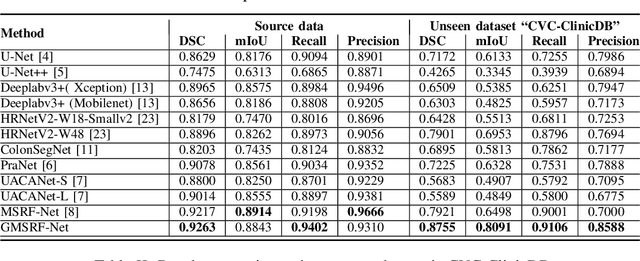
Colonoscopy is a gold standard procedure but is highly operator-dependent. Efforts have been made to automate the detection and segmentation of polyps, a precancerous precursor, to effectively minimize missed rate. Widely used computer-aided polyp segmentation systems actuated by encoder-decoder have achieved high performance in terms of accuracy. However, polyp segmentation datasets collected from varied centers can follow different imaging protocols leading to difference in data distribution. As a result, most methods suffer from performance drop and require re-training for each specific dataset. We address this generalizability issue by proposing a global multi-scale residual fusion network (GMSRF-Net). Our proposed network maintains high-resolution representations while performing multi-scale fusion operations for all resolution scales. To further leverage scale information, we design cross multi-scale attention (CMSA) and multi-scale feature selection (MSFS) modules within the GMSRF-Net. The repeated fusion operations gated by CMSA and MSFS demonstrate improved generalizability of the network. Experiments conducted on two different polyp segmentation datasets show that our proposed GMSRF-Net outperforms the previous top-performing state-of-the-art method by 8.34% and 10.31% on unseen CVC-ClinicDB and unseen Kvasir-SEG, in terms of dice coefficient.
Real-time Instance Segmentation of Surgical Instruments using Attention and Multi-scale Feature Fusion
Nov 10, 2021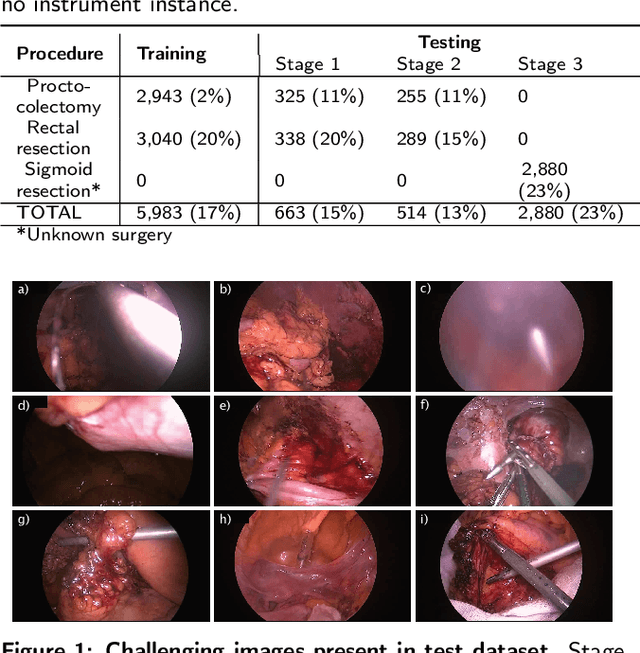
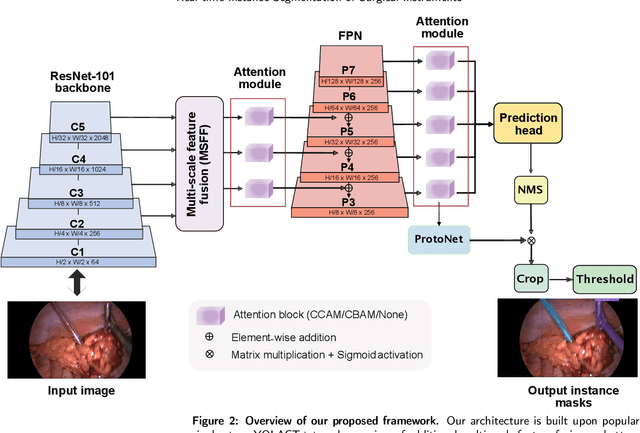
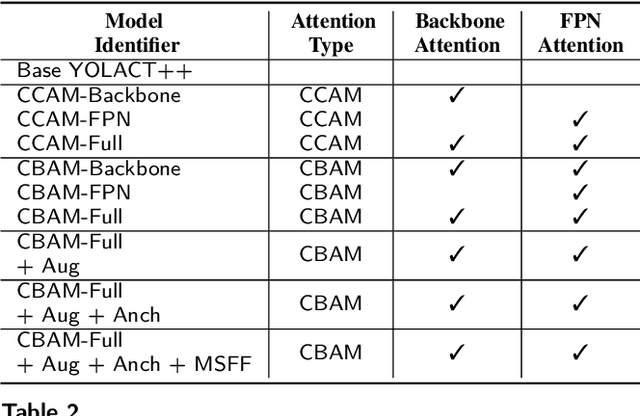
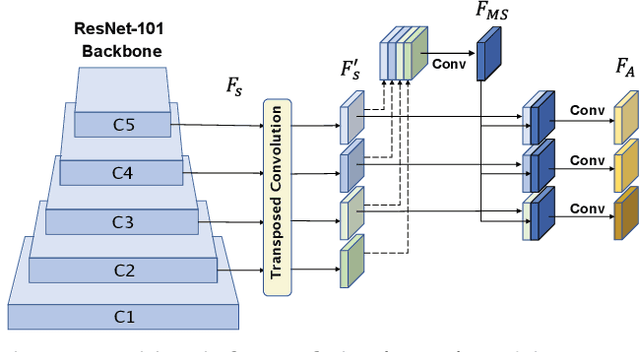
Precise instrument segmentation aid surgeons to navigate the body more easily and increase patient safety. While accurate tracking of surgical instruments in real-time plays a crucial role in minimally invasive computer-assisted surgeries, it is a challenging task to achieve, mainly due to 1) complex surgical environment, and 2) model design with both optimal accuracy and speed. Deep learning gives us the opportunity to learn complex environment from large surgery scene environments and placements of these instruments in real world scenarios. The Robust Medical Instrument Segmentation 2019 challenge (ROBUST-MIS) provides more than 10,000 frames with surgical tools in different clinical settings. In this paper, we use a light-weight single stage instance segmentation model complemented with a convolutional block attention module for achieving both faster and accurate inference. We further improve accuracy through data augmentation and optimal anchor localisation strategies. To our knowledge, this is the first work that explicitly focuses on both real-time performance and improved accuracy. Our approach out-performed top team performances in the ROBUST-MIS challenge with over 44% improvement on both area-based metric MI_DSC and distance-based metric MI_NSD. We also demonstrate real-time performance (> 60 frames-per-second) with different but competitive variants of our final approach.
Exploring Deep Learning Methods for Real-Time Surgical Instrument Segmentation in Laparoscopy
Aug 03, 2021
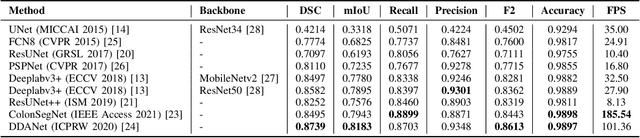
Minimally invasive surgery is a surgical intervention used to examine the organs inside the abdomen and has been widely used due to its effectiveness over open surgery. Due to the hardware improvements such as high definition cameras, this procedure has significantly improved and new software methods have demonstrated potential for computer-assisted procedures. However, there exists challenges and requirements to improve detection and tracking of the position of the instruments during these surgical procedures. To this end, we evaluate and compare some popular deep learning methods that can be explored for the automated segmentation of surgical instruments in laparoscopy, an important step towards tool tracking. Our experimental results exhibit that the Dual decoder attention network (DDANet) produces a superior result compared to other recent deep learning methods. DDANet yields a Dice coefficient of 0.8739 and mean intersection-over-union of 0.8183 for the Robust Medical Instrument Segmentation (ROBUST-MIS) Challenge 2019 dataset, at a real-time speed of 101.36 frames-per-second that is critical for such procedures.
EndoUDA: A modality independent segmentation approach for endoscopy imaging
Jul 12, 2021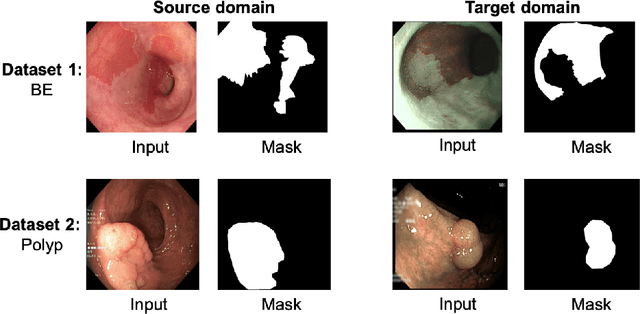
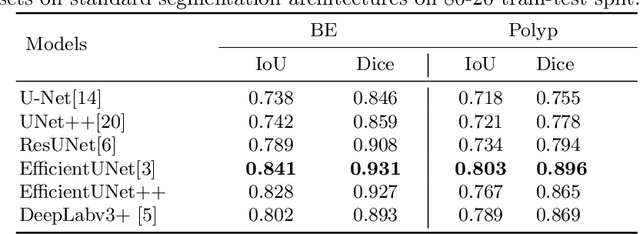
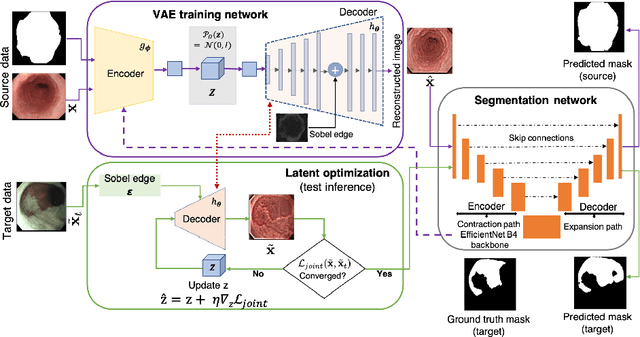
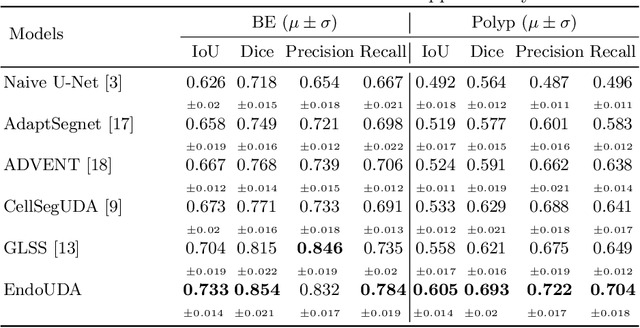
Gastrointestinal (GI) cancer precursors require frequent monitoring for risk stratification of patients. Automated segmentation methods can help to assess risk areas more accurately, and assist in therapeutic procedures or even removal. In clinical practice, addition to the conventional white-light imaging (WLI), complimentary modalities such as narrow-band imaging (NBI) and fluorescence imaging are used. While, today most segmentation approaches are supervised and only concentrated on a single modality dataset, this work exploits to use a target-independent unsupervised domain adaptation (UDA) technique that is capable to generalize to an unseen target modality. In this context, we propose a novel UDA-based segmentation method that couples the variational autoencoder and U-Net with a common EfficientNet-B4 backbone, and uses a joint loss for latent-space optimization for target samples. We show that our model can generalize to unseen target NBI (target) modality when trained using only WLI (source) modality. Our experiments on both upper and lower GI endoscopy data show the effectiveness of our approach compared to naive supervised approach and state-of-the-art UDA segmentation methods.
PolypGen: A multi-center polyp detection and segmentation dataset for generalisability assessment
Jun 08, 2021
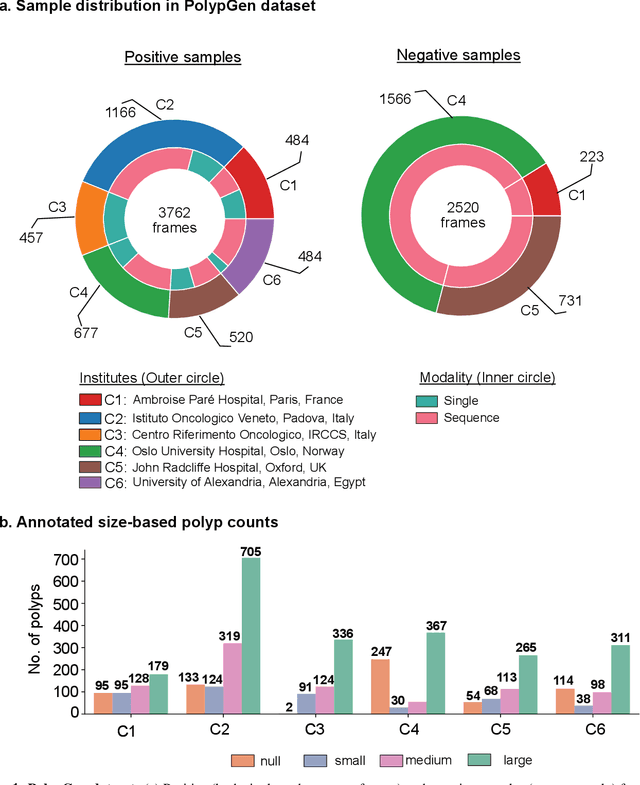
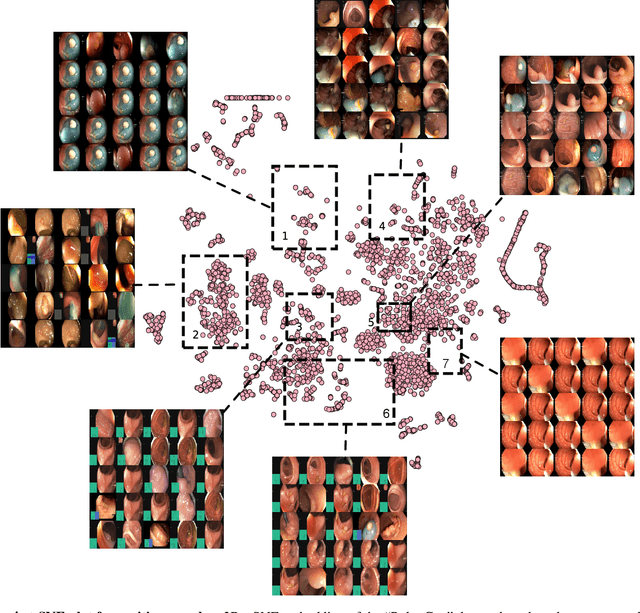
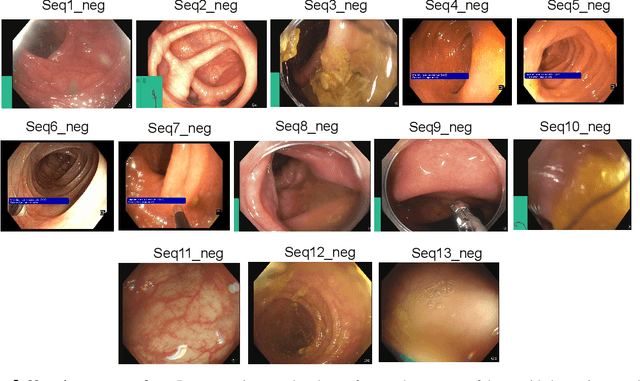
Polyps in the colon are widely known as cancer precursors identified by colonoscopy either related to diagnostic work-up for symptoms, colorectal cancer screening or systematic surveillance of certain diseases. Whilst most polyps are benign, the number, size and the surface structure of the polyp are tightly linked to the risk of colon cancer. There exists a high missed detection rate and incomplete removal of colon polyps due to the variable nature, difficulties to delineate the abnormality, high recurrence rates and the anatomical topography of the colon. In the past, several methods have been built to automate polyp detection and segmentation. However, the key issue of most methods is that they have not been tested rigorously on a large multi-center purpose-built dataset. Thus, these methods may not generalise to different population datasets as they overfit to a specific population and endoscopic surveillance. To this extent, we have curated a dataset from 6 different centers incorporating more than 300 patients. The dataset includes both single frame and sequence data with 3446 annotated polyp labels with precise delineation of polyp boundaries verified by six senior gastroenterologists. To our knowledge, this is the most comprehensive detection and pixel-level segmentation dataset curated by a team of computational scientists and expert gastroenterologists. This dataset has been originated as the part of the Endocv2021 challenge aimed at addressing generalisability in polyp detection and segmentation. In this paper, we provide comprehensive insight into data construction and annotation strategies, annotation quality assurance and technical validation for our extended EndoCV2021 dataset which we refer to as PolypGen.
Few-shot segmentation of medical images based on meta-learning with implicit gradients
Jun 06, 2021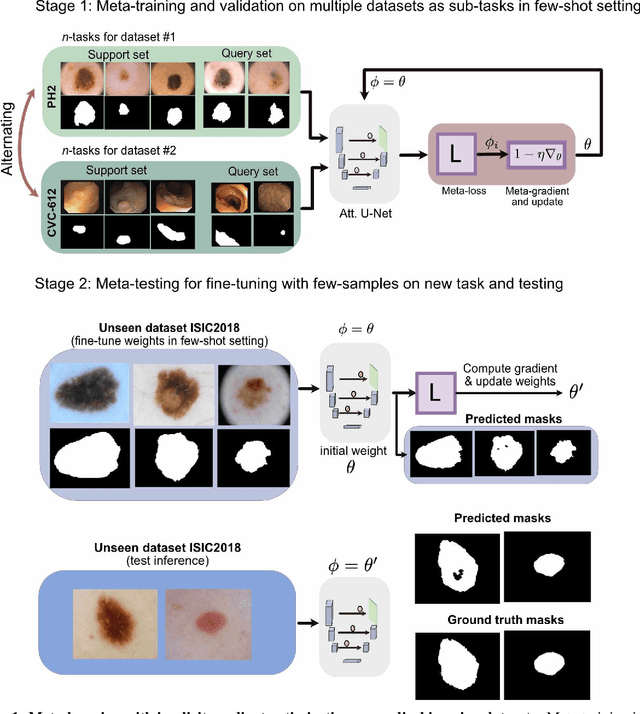
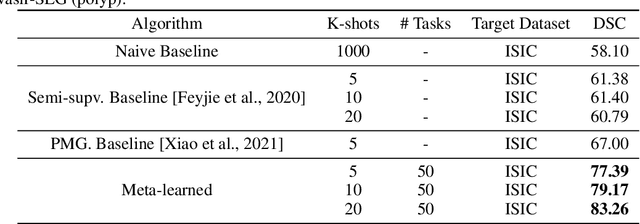
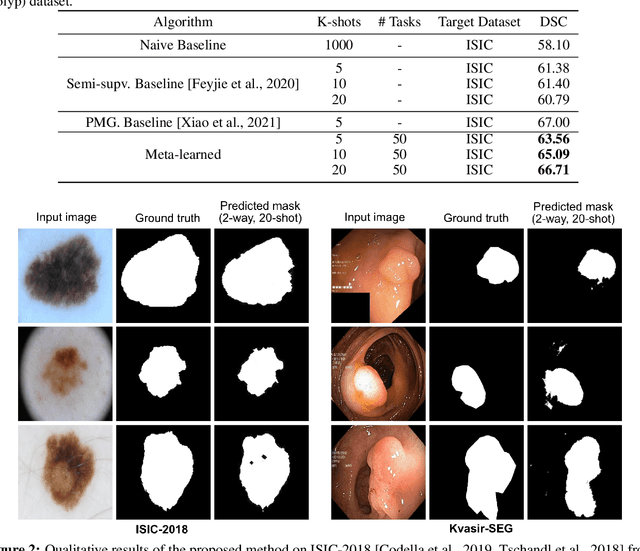
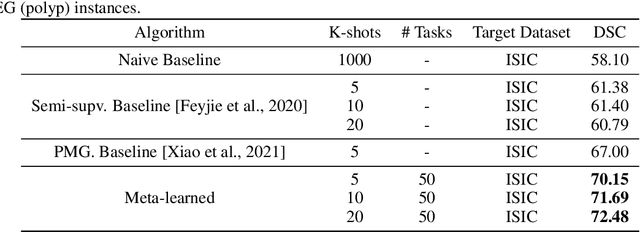
Classical supervised methods commonly used often suffer from the requirement of an abudant number of training samples and are unable to generalize on unseen datasets. As a result, the broader application of any trained model is very limited in clinical settings. However, few-shot approaches can minimize the need for enormous reliable ground truth labels that are both labor intensive and expensive. To this end, we propose to exploit an optimization-based implicit model agnostic meta-learning {iMAML} algorithm in a few-shot setting for medical image segmentation. Our approach can leverage the learned weights from a diverse set of training samples and can be deployed on a new unseen dataset. We show that unlike classical few-shot learning approaches, our method has improved generalization capability. To our knowledge, this is the first work that exploits iMAML for medical image segmentation. Our quantitative results on publicly available skin and polyp datasets show that the proposed method outperforms the naive supervised baseline model and two recent few-shot segmentation approaches by large margins.
MSRF-Net: A Multi-Scale Residual Fusion Network for Biomedical Image Segmentation
May 16, 2021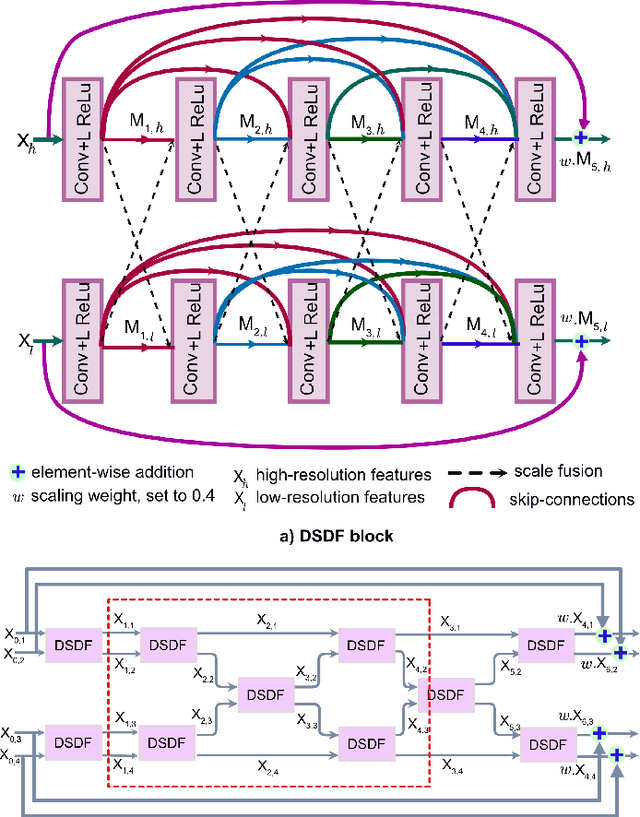
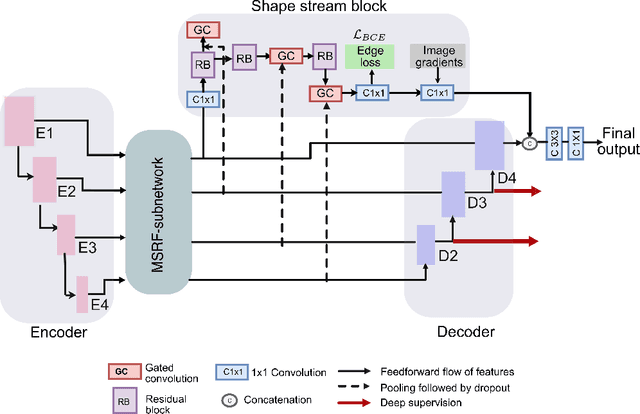
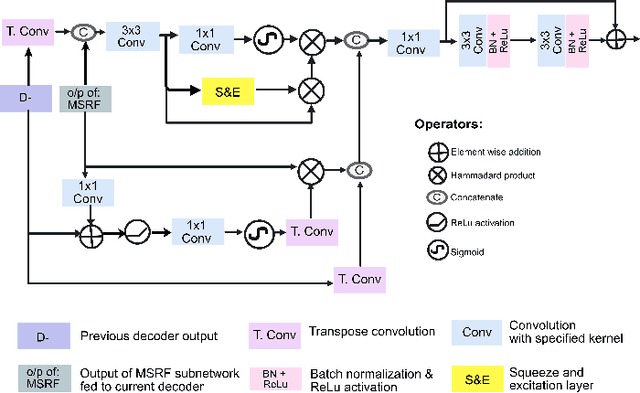
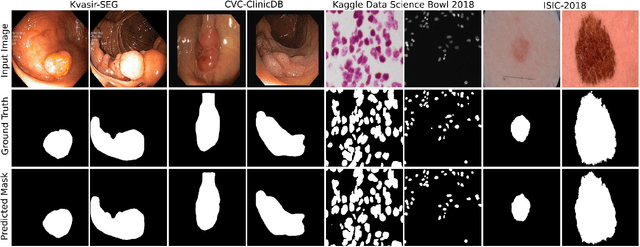
Methods based on convolutional neural networks have improved the performance of biomedical image segmentation. However, most of these methods cannot efficiently segment objects of variable sizes and train on small and biased datasets, which are common in biomedical use cases. While methods exist that incorporate multi-scale fusion approaches to address the challenges arising with variable sizes, they usually use complex models that are more suitable for general semantic segmentation computer vision problems. In this paper, we propose a novel architecture called MSRF-Net, which is specially designed for medical image segmentation tasks. The proposed MSRF-Net is able to exchange multi-scale features of varying receptive fields using a dual-scale dense fusion block (DSDF). Our DSDF block can exchange information rigorously across two different resolution scales, and our MSRF sub-network uses multiple DSDF blocks in sequence to perform multi-scale fusion. This allows the preservation of resolution, improved information flow, and propagation of both high- and low-level features to obtain accurate segmentation maps. The proposed MSRF-Net allows to capture object variabilities and provides improved results on different biomedical datasets. Extensive experiments on MSRF-Net demonstrate that the proposed method outperforms most of the cutting-edge medical image segmentation state-of-the-art methods. MSRF-Net advances the performance on four publicly available datasets, and also, MSRF-Net is more generalizable as compared to state-of-the-art methods.