 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPS: Multi-Anchor Projection Similarity for Joint Vision-Language Geo-Localization
Jun 21, 2026Humans localize places by integrating perceptual cues from vision with semantic reasoning from language, forming a scene understanding that is both intuitive and structured. Although existing geo-localization models have made substantial progress in cross-view and cross-modal settings, they are largely built upon point-to-point alignment, which is insufficient for joint vision-language queries. In such queries, visual and textual cues do not simply act as independent references, but jointly define a semantic subspace for locating the target. In this paper, we formulate vision-language geo-localization (VLGL) with joint image-text queries as a multi-anchor geometric alignment problem and propose a unified framework for this setting. To realize this formulation, we propose Multi-Anchor Projection Similarity (MAPS), a new metric which constructs an anchor plane from visual and textual query features in a high-dimensional space and measures similarity by the projection length of the target feature onto this plane. Unlike cosine similarity which evaluates isolated pairwise relations, MAPS captures the geometric consistency between the target feature and the joint query subspace, providing a more discriminative ranking criterion during retrieval. To make the learned representation consistent with this geometry, we further introduce a MAPS-based contrastive loss that drives target features toward the corresponding anchor plane. The proposed framework, similarity metric, and training objective jointly yield state-of-the-art performance in VLGL.
Model-Agnostic Lifelong LLM Safety via Externalized Attack-Defense Co-Evolution
May 13, 2026Large language models remain vulnerable to adversarial prompts that elicit harmful outputs. Existing safety paradigms typically couple red-teaming and post-training in a closed, policy-centric loop, causing attack discovery to suffer from rapid saturation and limiting the exposure of novel failure modes, while leaving defenses inefficient, rigid, and difficult to transfer across victim models. To this end, we propose EvoSafety, an LLM safety framework built around persistent, inspectable, and reusable external structures. For red teaming, EvoSafety equips the attack policy with an adversarial skill library, enabling continued vulnerability probing through simple library expansion after saturation, while supporting the evolution of adversarial vectors. For defense learning, EvoSafety replaces model-specific safety fine-tuning with a lightweight auxiliary defense model augmented with memory retrieval. This enables efficient, transferable, and model-agnostic safety improvements, while allowing robustness to be enhanced solely through memory updates. With a single training procedure, the defense policy can operate in both Steer and Guard modes: the former activates the victim model's intrinsic defense mechanisms, while the latter directly filters harmful inputs. Extensive experiments demonstrate the superiority of EvoSafety: in Guard mode, it achieves a 99.61% defense success rate, outperforming Qwen3Guard-8B by 14.13% with only 37.5% of its parameters, while preserving reasoning performance on benign queries. Warning: This paper contains potentially harmful text.
ULF-Loc: Unbiased Landmark Feature for Robust Visual Localization with 3D Gaussian Splatting
May 06, 2026Visual localization is a core technology for augmented reality and autonomous navigation. Recent methods combine the efficient rendering of 3D Gaussian Splatting (3DGS) with feature-based localization. These methods rely on direct matching between 2D query features and the 3D Gaussian feature field, but this often results in mismatches due to an inherent bias in the learned Gaussian feature. We theoretically analyze the feature learning process in 3DGS, revealing that the widely adopted $α$-blending optimization inherently introduces bias into 3D point features. This bias stems from the entanglement between individual Gaussians and their neighboring Gaussians, making the learned features unsuitable for precise matching tasks. Motivated by these findings, we propose ULF-Loc, an unbiased landmark feature framework that replaces biased feature optimization with geometry-weighted feature fusion. We further introduce keypoint-consensus landmark sampling to select reliable Gaussians and local geometric consistency verification to reject mismatches caused by rendering artifacts. On the Cambridge Landmarks dataset, ULF-Loc reduces the mean median translation error by 17\% compared to the state-of-the-art, while achieving superior efficiency with only 1/10 the training time and 1/6 the GPU memory of STDLoc.
Global Cross-Modal Geo-Localization: A Million-Scale Dataset and a Physical Consistency Learning Framework
Mar 09, 2026Cross-modal Geo-localization (CMGL) matches ground-level text descriptions with geo-tagged aerial imagery, which is crucial for pedestrian navigation and emergency response. However, existing researches are constrained by narrow geographic coverage and simplistic scene diversity, failing to reflect the immense spatial heterogeneity of global architectural styles and topographic features. To bridge this gap and facilitate universal positioning, we introduce CORE, the first million-scale dataset dedicated to global CMGL. CORE comprises 1,034,786 cross-view images sampled from 225 distinct geographic regions across all continents, offering an unprecedented variety of perspectives in varying environmental conditions and urban layouts. We leverage the zero-shot reasoning of Large Vision-Language Models (LVLMs) to synthesize high-quality scene descriptions rich in discriminative cues. Furthermore, we propose a physical-law-aware network (PLANET) for cross-modal geo-localization. PLANET introduces a novel contrastive learning paradigm to guide textual representations in capturing the intrinsic physical signatures of satellite imagery. Extensive experiments across varied geographic regions demonstrate that PLANet significantly outperforms state-of-the-art methods, establishing a new benchmark for robust, global-scale geo-localization. The dataset and source code will be released at https://github.com/YtH0823/CORE.
Advances in Global Solvers for 3D Vision
Feb 16, 2026Global solvers have emerged as a powerful paradigm for 3D vision, offering certifiable solutions to nonconvex geometric optimization problems traditionally addressed by local or heuristic methods. This survey presents the first systematic review of global solvers in geometric vision, unifying the field through a comprehensive taxonomy of three core paradigms: Branch-and-Bound (BnB), Convex Relaxation (CR), and Graduated Non-Convexity (GNC). We present their theoretical foundations, algorithmic designs, and practical enhancements for robustness and scalability, examining how each addresses the fundamental nonconvexity of geometric estimation problems. Our analysis spans ten core vision tasks, from Wahba problem to bundle adjustment, revealing the optimality-robustness-scalability trade-offs that govern solver selection. We identify critical future directions: scaling algorithms while maintaining guarantees, integrating data-driven priors with certifiable optimization, establishing standardized benchmarks, and addressing societal implications for safety-critical deployment. By consolidating theoretical foundations, practical advances, and broader impacts, this survey provides a unified perspective and roadmap toward certifiable, trustworthy perception for real-world applications. A continuously-updated literature summary and companion code tutorials are available at https://github.com/ericzzj1989/Awesome-Global-Solvers-for-3D-Vision.
TurboReg: TurboClique for Robust and Efficient Point Cloud Registration
Jul 02, 2025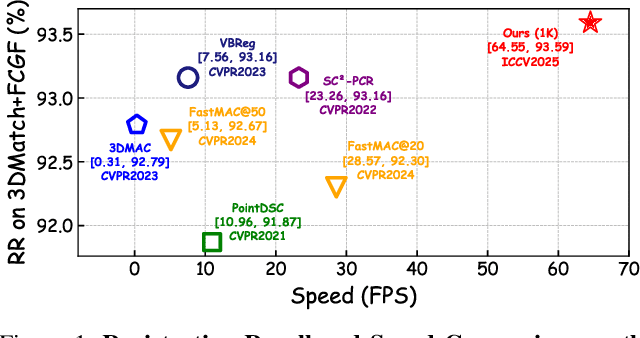



Robust estimation is essential in correspondence-based Point Cloud Registration (PCR). Existing methods using maximal clique search in compatibility graphs achieve high recall but suffer from exponential time complexity, limiting their use in time-sensitive applications. To address this challenge, we propose a fast and robust estimator, TurboReg, built upon a novel lightweight clique, TurboClique, and a highly parallelizable Pivot-Guided Search (PGS) algorithm. First, we define the TurboClique as a 3-clique within a highly-constrained compatibility graph. The lightweight nature of the 3-clique allows for efficient parallel searching, and the highly-constrained compatibility graph ensures robust spatial consistency for stable transformation estimation. Next, PGS selects matching pairs with high SC$^2$ scores as pivots, effectively guiding the search toward TurboCliques with higher inlier ratios. Moreover, the PGS algorithm has linear time complexity and is significantly more efficient than the maximal clique search with exponential time complexity. Extensive experiments show that TurboReg achieves state-of-the-art performance across multiple real-world datasets, with substantial speed improvements. For example, on the 3DMatch+FCGF dataset, TurboReg (1K) operates $208.22\times$ faster than 3DMAC while also achieving higher recall. Our code is accessible at \href{https://github.com/Laka-3DV/TurboReg}{\texttt{TurboReg}}.
RANSAC Back to SOTA: A Two-stage Consensus Filtering for Real-time 3D Registration
Oct 21, 2024



Correspondence-based point cloud registration (PCR) plays a key role in robotics and computer vision. However, challenges like sensor noises, object occlusions, and descriptor limitations inevitably result in numerous outliers. RANSAC family is the most popular outlier removal solution. However, the requisite iterations escalate exponentially with the outlier ratio, rendering it far inferior to existing methods (SC2PCR [1], MAC [2], etc.) in terms of accuracy or speed. Thus, we propose a two-stage consensus filtering (TCF) that elevates RANSAC to state-of-the-art (SOTA) speed and accuracy. Firstly, one-point RANSAC obtains a consensus set based on length consistency. Subsequently, two-point RANSAC refines the set via angle consistency. Then, three-point RANSAC computes a coarse pose and removes outliers based on transformed correspondence's distances. Drawing on optimizations from one-point and two-point RANSAC, three-point RANSAC requires only a few iterations. Eventually, an iterative reweighted least squares (IRLS) is applied to yield the optimal pose. Experiments on the large-scale KITTI and ETH datasets demonstrate our method achieves up to three-orders-of-magnitude speedup compared to MAC while maintaining registration accuracy and recall. Our code is available at https://github.com/ShiPC-AI/TCF.
ML-SemReg: Boosting Point Cloud Registration with Multi-level Semantic Consistency
Jul 13, 2024



Recent advances in point cloud registration mostly leverage geometric information. Although these methods have yielded promising results, they still struggle with problems of low overlap, thus limiting their practical usage. In this paper, we propose ML-SemReg, a plug-and-play point cloud registration framework that fully exploits semantic information. Our key insight is that mismatches can be categorized into two types, i.e., inter- and intra-class, after rendering semantic clues, and can be well addressed by utilizing multi-level semantic consistency. We first propose a Group Matching module to address inter-class mismatching, outputting multiple matching groups that inherently satisfy Local Semantic Consistency. For each group, a Mask Matching module based on Scene Semantic Consistency is then introduced to suppress intra-class mismatching. Benefit from those two modules, ML-SemReg generates correspondences with a high inlier ratio. Extensive experiments demonstrate excellent performance and robustness of ML-SemReg, e.g., in hard-cases of the KITTI dataset, the Registration Recall of MAC increases by almost 34 percentage points when our ML-SemReg is equipped. Code is available at \url{https://github.com/Laka-3DV/ML-SemReg}