 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Long-Form Spoken Language Translation with Large Language Models
Dec 19, 2022



A challenge in spoken language translation is that plenty of spoken content is long-form, but short units are necessary for obtaining high-quality translations. To address this mismatch, we fine-tune a general-purpose, large language model to split long ASR transcripts into segments that can be independently translated so as to maximize the overall translation quality. We compare to several segmentation strategies and find that our approach improves BLEU score on three languages by an average of 2.7 BLEU overall compared to an automatic punctuation baseline. Further, we demonstrate the effectiveness of two constrained decoding strategies to improve well-formedness of the model output from above 99% to 100%.
Conciseness: An Overlooked Language Task
Nov 08, 2022



We report on novel investigations into training models that make sentences concise. We define the task and show that it is different from related tasks such as summarization and simplification. For evaluation, we release two test sets, consisting of 2000 sentences each, that were annotated by two and five human annotators, respectively. We demonstrate that conciseness is a difficult task for which zero-shot setups with large neural language models often do not perform well. Given the limitations of these approaches, we propose a synthetic data generation method based on round-trip translations. Using this data to either train Transformers from scratch or fine-tune T5 models yields our strongest baselines that can be further improved by fine-tuning on an artificial conciseness dataset that we derived from multi-annotator machine translation test sets.
Simple and Effective Gradient-Based Tuning of Sequence-to-Sequence Models
Sep 10, 2022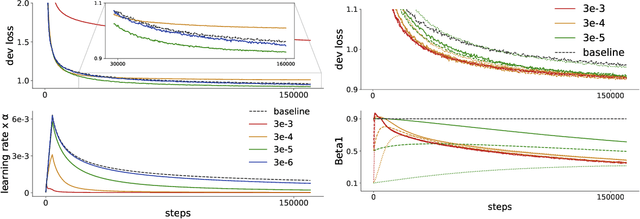
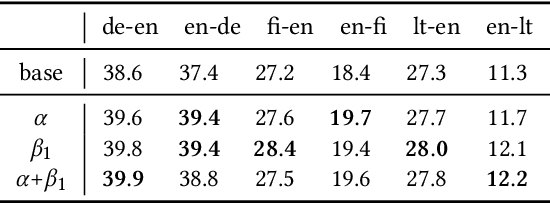
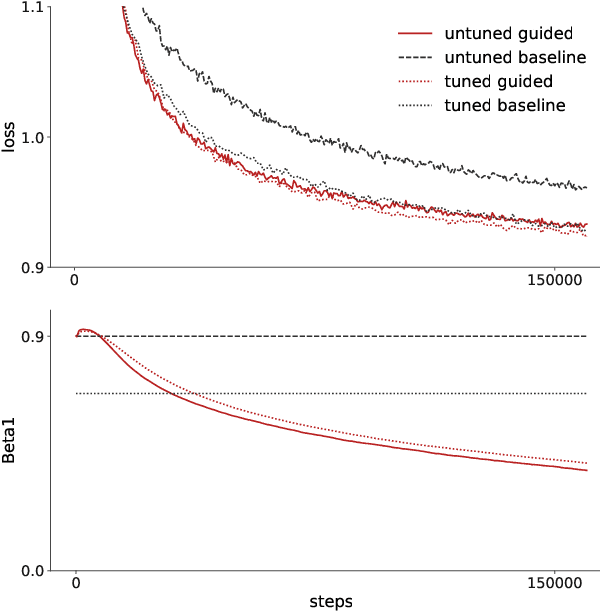
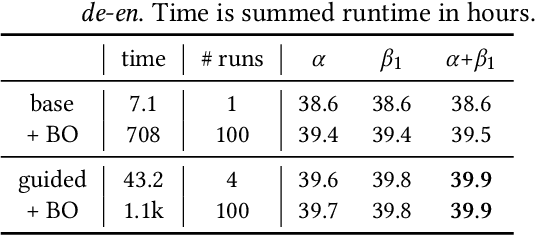
Recent trends towards training ever-larger language models have substantially improved machine learning performance across linguistic tasks. However, the huge cost of training larger models can make tuning them prohibitively expensive, motivating the study of more efficient methods. Gradient-based hyper-parameter optimization offers the capacity to tune hyper-parameters during training, yet has not previously been studied in a sequence-to-sequence setting. We apply a simple and general gradient-based hyperparameter optimization method to sequence-to-sequence tasks for the first time, demonstrating both efficiency and performance gains over strong baselines for both Neural Machine Translation and Natural Language Understanding (NLU) tasks (via T5 pretraining). For translation, we show the method generalizes across language pairs, is more efficient than Bayesian hyper-parameter optimization, and that learned schedules for some hyper-parameters can out-perform even optimal constant-valued tuning. For T5, we show that learning hyper-parameters during pretraining can improve performance across downstream NLU tasks. When learning multiple hyper-parameters concurrently, we show that the global learning rate can follow a schedule over training that improves performance and is not explainable by the `short-horizon bias' of greedy methods \citep{wu2018}. We release the code used to facilitate further research.
Text Generation with Text-Editing Models
Jun 14, 2022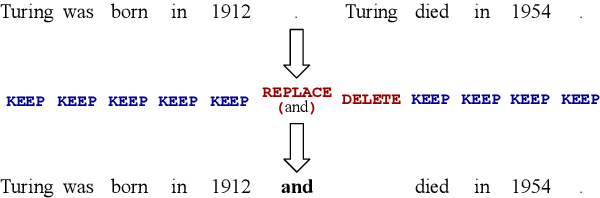

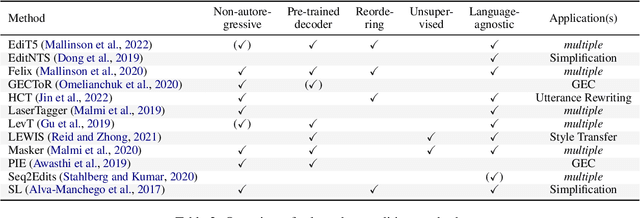
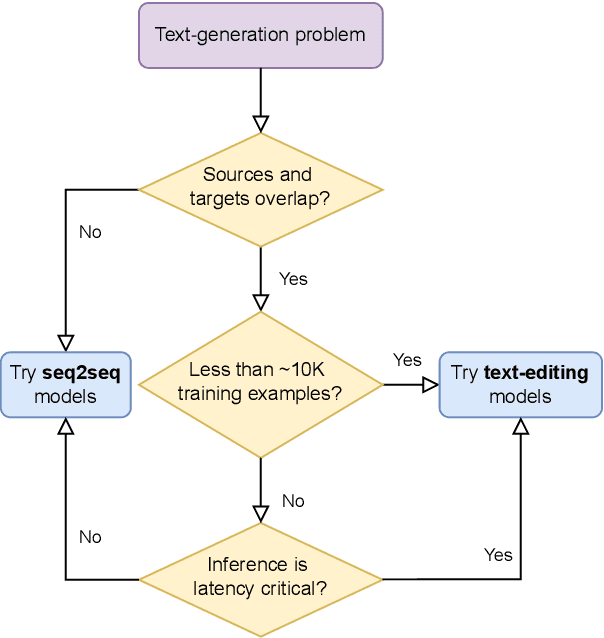
Text-editing models have recently become a prominent alternative to seq2seq models for monolingual text-generation tasks such as grammatical error correction, simplification, and style transfer. These tasks share a common trait - they exhibit a large amount of textual overlap between the source and target texts. Text-editing models take advantage of this observation and learn to generate the output by predicting edit operations applied to the source sequence. In contrast, seq2seq models generate outputs word-by-word from scratch thus making them slow at inference time. Text-editing models provide several benefits over seq2seq models including faster inference speed, higher sample efficiency, and better control and interpretability of the outputs. This tutorial provides a comprehensive overview of text-editing models and current state-of-the-art approaches, and analyzes their pros and cons. We discuss challenges related to productionization and how these models can be used to mitigate hallucination and bias, both pressing challenges in the field of text generation.
Jam or Cream First? Modeling Ambiguity in Neural Machine Translation with SCONES
May 02, 2022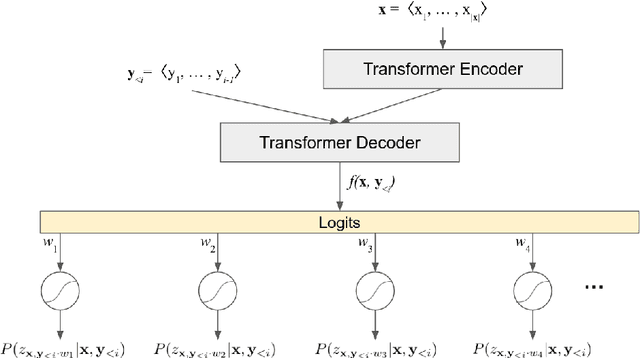

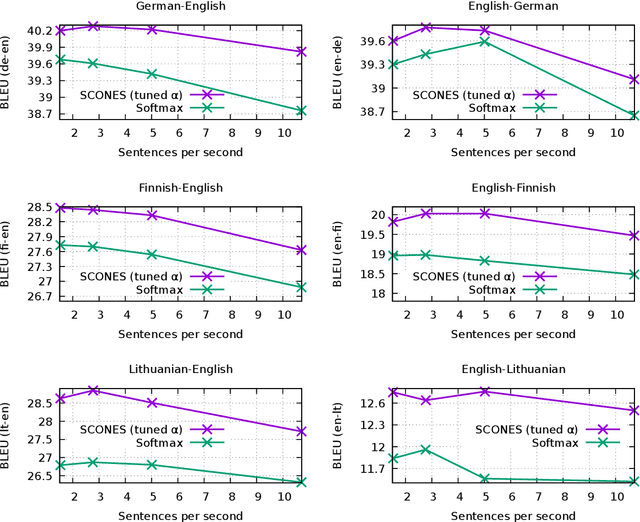
The softmax layer in neural machine translation is designed to model the distribution over mutually exclusive tokens. Machine translation, however, is intrinsically uncertain: the same source sentence can have multiple semantically equivalent translations. Therefore, we propose to replace the softmax activation with a multi-label classification layer that can model ambiguity more effectively. We call our loss function Single-label Contrastive Objective for Non-Exclusive Sequences (SCONES). We show that the multi-label output layer can still be trained on single reference training data using the SCONES loss function. SCONES yields consistent BLEU score gains across six translation directions, particularly for medium-resource language pairs and small beam sizes. By using smaller beam sizes we can speed up inference by a factor of 3.9x and still match or improve the BLEU score obtained using softmax. Furthermore, we demonstrate that SCONES can be used to train NMT models that assign the highest probability to adequate translations, thus mitigating the "beam search curse". Additional experiments on synthetic language pairs with varying levels of uncertainty suggest that the improvements from SCONES can be attributed to better handling of ambiguity.
Uncertainty Determines the Adequacy of the Mode and the Tractability of Decoding in Sequence-to-Sequence Models
Apr 01, 2022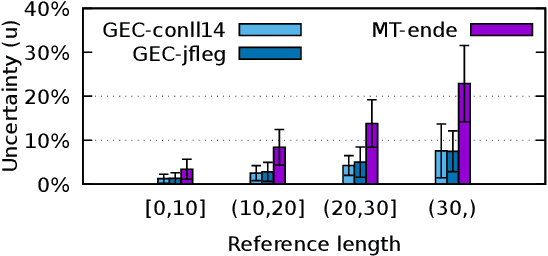

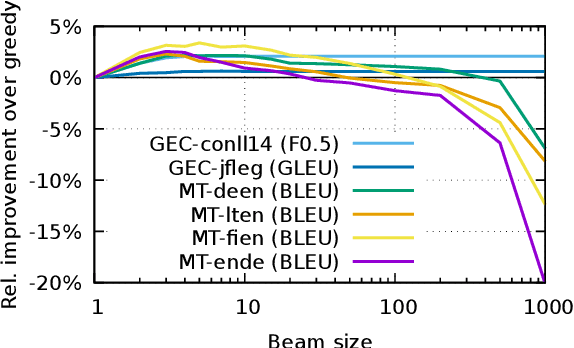
In many natural language processing (NLP) tasks the same input (e.g. source sentence) can have multiple possible outputs (e.g. translations). To analyze how this ambiguity (also known as intrinsic uncertainty) shapes the distribution learned by neural sequence models we measure sentence-level uncertainty by computing the degree of overlap between references in multi-reference test sets from two different NLP tasks: machine translation (MT) and grammatical error correction (GEC). At both the sentence- and the task-level, intrinsic uncertainty has major implications for various aspects of search such as the inductive biases in beam search and the complexity of exact search. In particular, we show that well-known pathologies such as a high number of beam search errors, the inadequacy of the mode, and the drop in system performance with large beam sizes apply to tasks with high level of ambiguity such as MT but not to less uncertain tasks such as GEC. Furthermore, we propose a novel exact $n$-best search algorithm for neural sequence models, and show that intrinsic uncertainty affects model uncertainty as the model tends to overly spread out the probability mass for uncertain tasks and sentences.
Sentence-Select: Large-Scale Language Model Data Selection for Rare-Word Speech Recognition
Mar 09, 2022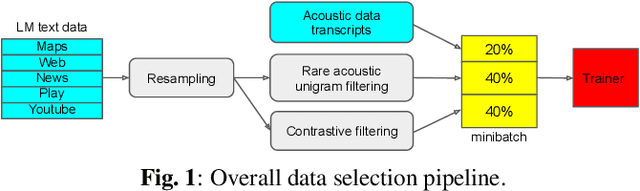
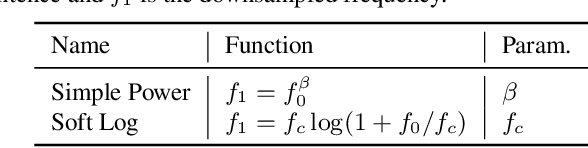
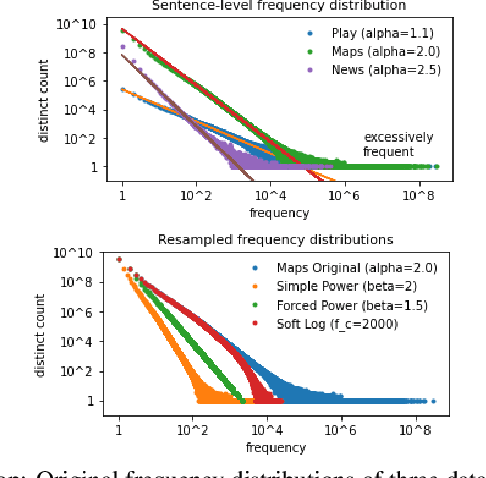
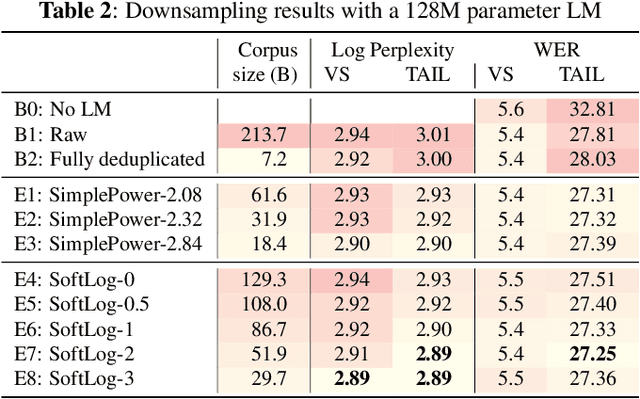
Language model fusion helps smart assistants recognize words which are rare in acoustic data but abundant in text-only corpora (typed search logs). However, such corpora have properties that hinder downstream performance, including being (1) too large, (2) beset with domain-mismatched content, and (3) heavy-headed rather than heavy-tailed (excessively many duplicate search queries such as "weather"). We show that three simple strategies for selecting language modeling data can dramatically improve rare-word recognition without harming overall performance. First, to address the heavy-headedness, we downsample the data according to a soft log function, which tunably reduces high frequency (head) sentences. Second, to encourage rare-word exposure, we explicitly filter for words rare in the acoustic data. Finally, we tackle domain-mismatch via perplexity-based contrastive selection, filtering for examples matched to the target domain. We down-select a large corpus of web search queries by a factor of 53x and achieve better LM perplexities than without down-selection. When shallow-fused with a state-of-the-art, production speech engine, our LM achieves WER reductions of up to 24% relative on rare-word sentences (without changing overall WER) compared to a baseline LM trained on the raw corpus. These gains are further validated through favorable side-by-side evaluations on live voice search traffic.
Capitalization Normalization for Language Modeling with an Accurate and Efficient Hierarchical RNN Model
Feb 16, 2022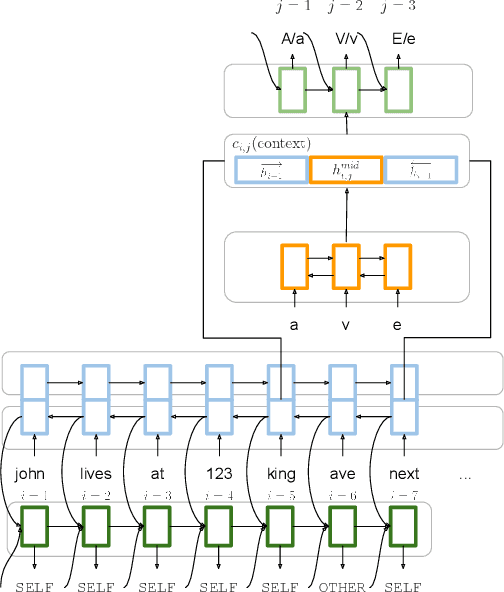
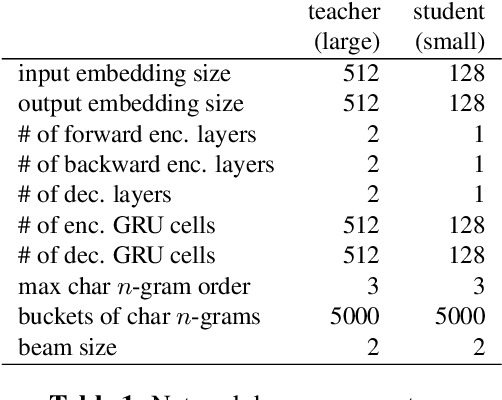
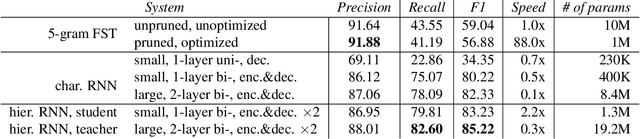

Capitalization normalization (truecasing) is the task of restoring the correct case (uppercase or lowercase) of noisy text. We propose a fast, accurate and compact two-level hierarchical word-and-character-based recurrent neural network model. We use the truecaser to normalize user-generated text in a Federated Learning framework for language modeling. A case-aware language model trained on this normalized text achieves the same perplexity as a model trained on text with gold capitalization. In a real user A/B experiment, we demonstrate that the improvement translates to reduced prediction error rates in a virtual keyboard application. Similarly, in an ASR language model fusion experiment, we show reduction in uppercase character error rate and word error rate.
Transformer-based Models of Text Normalization for Speech Applications
Feb 01, 2022



Text normalization, or the process of transforming text into a consistent, canonical form, is crucial for speech applications such as text-to-speech synthesis (TTS). In TTS, the system must decide whether to verbalize "1995" as "nineteen ninety five" in "born in 1995" or as "one thousand nine hundred ninety five" in "page 1995". We present an experimental comparison of various Transformer-based sequence-to-sequence (seq2seq) models of text normalization for speech and evaluate them on a variety of datasets of written text aligned to its normalized spoken form. These models include variants of the 2-stage RNN-based tagging/seq2seq architecture introduced by Zhang et al. (2019), where we replace the RNN with a Transformer in one or more stages, as well as vanilla Transformers that output string representations of edit sequences. Of our approaches, using Transformers for sentence context encoding within the 2-stage model proved most effective, with the fine-tuned BERT encoder yielding the best performance.
Position-Invariant Truecasing with a Word-and-Character Hierarchical Recurrent Neural Network
Sep 01, 2021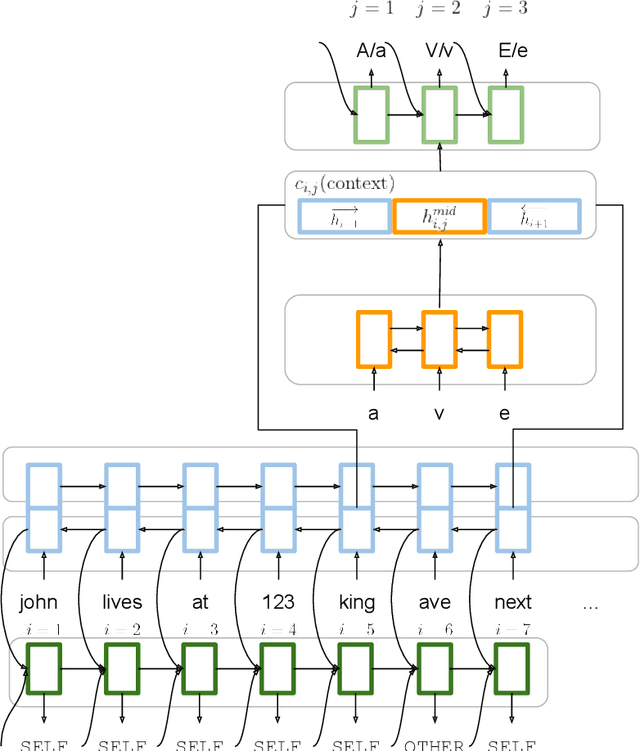

Truecasing is the task of restoring the correct case (uppercase or lowercase) of noisy text generated either by an automatic system for speech recognition or machine translation or by humans. It improves the performance of downstream NLP tasks such as named entity recognition and language modeling. We propose a fast, accurate and compact two-level hierarchical word-and-character-based recurrent neural network model, the first of its kind for this problem. Using sequence distillation, we also address the problem of truecasing while ignoring token positions in the sentence, i.e. in a position-invariant manner.