 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Live Experiments in Recommender Systems: User Simulation to Evaluate Preference Elicitation Policies
Sep 26, 2024



Evaluation of policies in recommender systems typically involves A/B testing using live experiments on real users to assess a new policy's impact on relevant metrics. This ``gold standard'' comes at a high cost, however, in terms of cycle time, user cost, and potential user retention. In developing policies for ``onboarding'' new users, these costs can be especially problematic, since on-boarding occurs only once. In this work, we describe a simulation methodology used to augment (and reduce) the use of live experiments. We illustrate its deployment for the evaluation of ``preference elicitation'' algorithms used to onboard new users of the YouTube Music platform. By developing counterfactually robust user behavior models, and a simulation service that couples such models with production infrastructure, we are able to test new algorithms in a way that reliably predicts their performance on key metrics when deployed live. We describe our domain, our simulation models and platform, results of experiments and deployment, and suggest future steps needed to further realistic simulation as a powerful complement to live experiments.
Learning from Negative User Feedback and Measuring Responsiveness for Sequential Recommenders
Aug 23, 2023


Sequential recommenders have been widely used in industry due to their strength in modeling user preferences. While these models excel at learning a user's positive interests, less attention has been paid to learning from negative user feedback. Negative user feedback is an important lever of user control, and comes with an expectation that recommenders should respond quickly and reduce similar recommendations to the user. However, negative feedback signals are often ignored in the training objective of sequential retrieval models, which primarily aim at predicting positive user interactions. In this work, we incorporate explicit and implicit negative user feedback into the training objective of sequential recommenders in the retrieval stage using a "not-to-recommend" loss function that optimizes for the log-likelihood of not recommending items with negative feedback. We demonstrate the effectiveness of this approach using live experiments on a large-scale industrial recommender system. Furthermore, we address a challenge in measuring recommender responsiveness to negative feedback by developing a counterfactual simulation framework to compare recommender responses between different user actions, showing improved responsiveness from the modeling change.
Highly Efficient 8-bit Low Precision Inference of Convolutional Neural Networks with IntelCaffe
May 04, 2018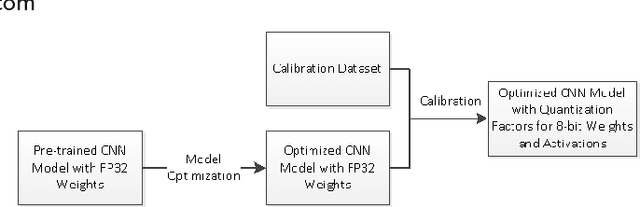
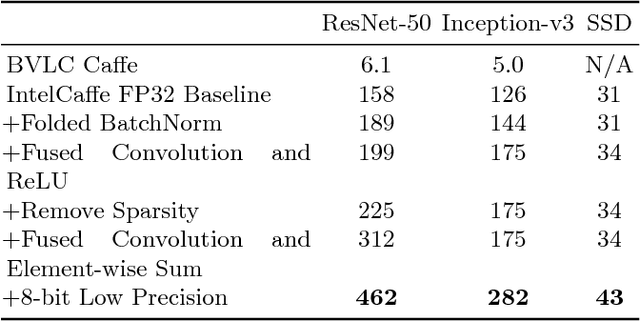

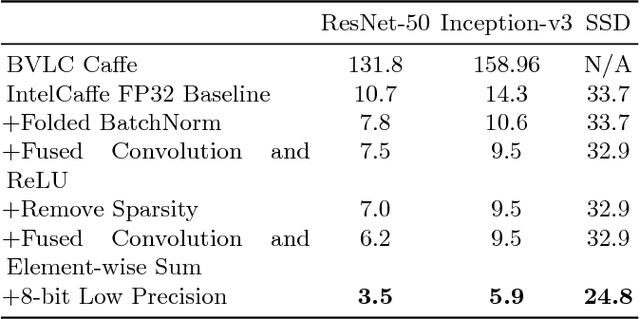
High throughput and low latency inference of deep neural networks are critical for the deployment of deep learning applications. This paper presents the efficient inference techniques of IntelCaffe, the first Intel optimized deep learning framework that supports efficient 8-bit low precision inference and model optimization techniques of convolutional neural networks on Intel Xeon Scalable Processors. The 8-bit optimized model is automatically generated with a calibration process from FP32 model without the need of fine-tuning or retraining. We show that the inference throughput and latency with ResNet-50, Inception-v3 and SSD are improved by 1.38X-2.9X and 1.35X-3X respectively with neglectable accuracy loss from IntelCaffe FP32 baseline and by 56X-75X and 26X-37X from BVLC Caffe. All these techniques have been open-sourced on IntelCaffe GitHub1, and the artifact is provided to reproduce the result on Amazon AWS Cloud.