 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaking the foundations: delusions in sequence models for interaction and control
Oct 20, 2021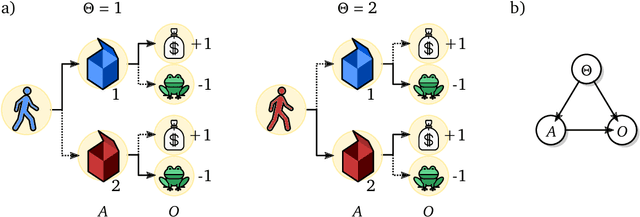
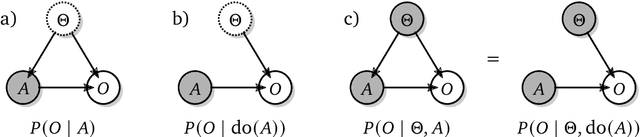
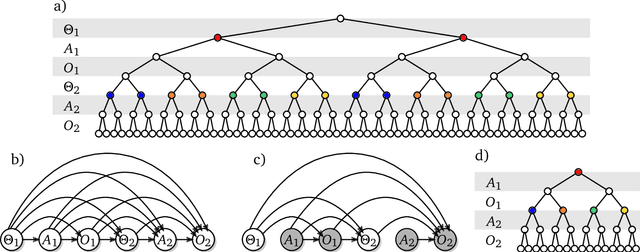
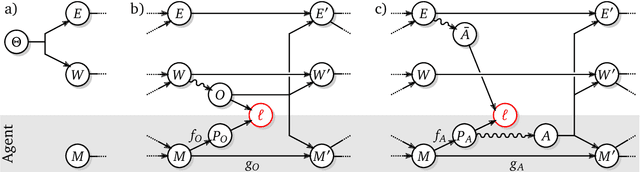
The recent phenomenal success of language models has reinvigorated machine learning research, and large sequence models such as transformers are being applied to a variety of domains. One important problem class that has remained relatively elusive however is purposeful adaptive behavior. Currently there is a common perception that sequence models "lack the understanding of the cause and effect of their actions" leading them to draw incorrect inferences due to auto-suggestive delusions. In this report we explain where this mismatch originates, and show that it can be resolved by treating actions as causal interventions. Finally, we show that in supervised learning, one can teach a system to condition or intervene on data by training with factual and counterfactual error signals respectively.
Causal Analysis of Agent Behavior for AI Safety
Mar 05, 2021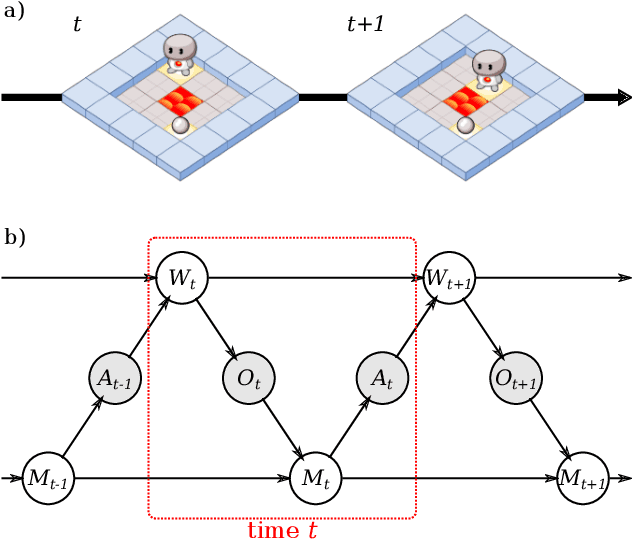
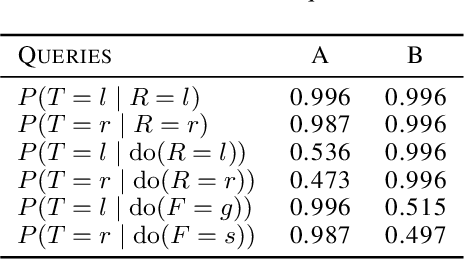
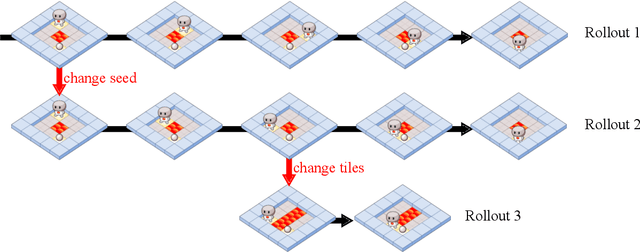
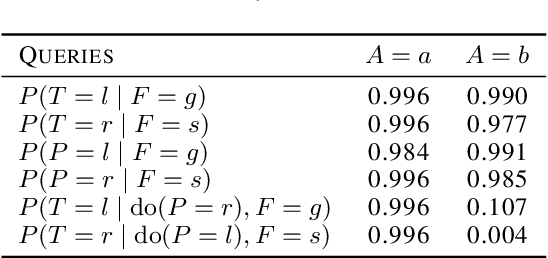
As machine learning systems become more powerful they also become increasingly unpredictable and opaque. Yet, finding human-understandable explanations of how they work is essential for their safe deployment. This technical report illustrates a methodology for investigating the causal mechanisms that drive the behaviour of artificial agents. Six use cases are covered, each addressing a typical question an analyst might ask about an agent. In particular, we show that each question cannot be addressed by pure observation alone, but instead requires conducting experiments with systematically chosen manipulations so as to generate the correct causal evidence.
Agent Incentives: A Causal Perspective
Feb 02, 2021

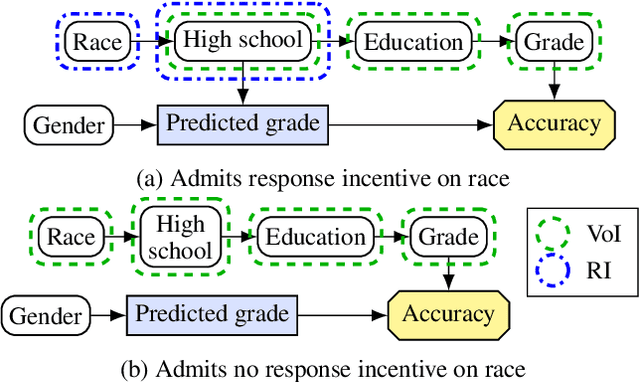
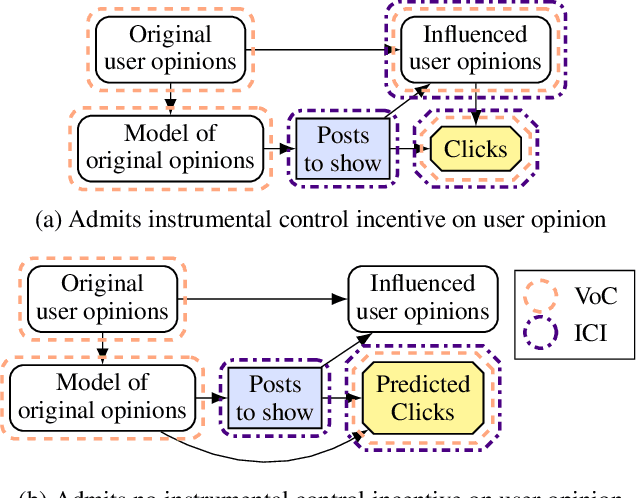
We present a framework for analysing agent incentives using causal influence diagrams. We establish that a well-known criterion for value of information is complete. We propose a new graphical criterion for value of control, establishing its soundness and completeness. We also introduce two new concepts for incentive analysis: response incentives indicate which changes in the environment affect an optimal decision, while instrumental control incentives establish whether an agent can influence its utility via a variable X. For both new concepts, we provide sound and complete graphical criteria. We show by example how these results can help with evaluating the safety and fairness of an AI system.
Avoiding Tampering Incentives in Deep RL via Decoupled Approval
Nov 17, 2020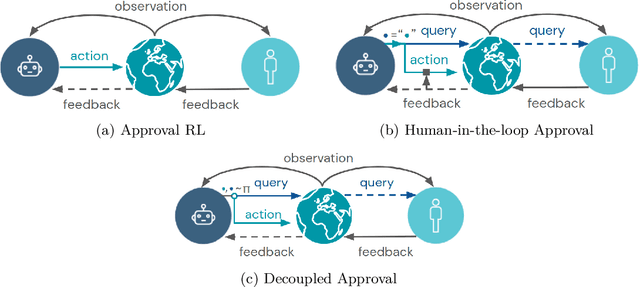
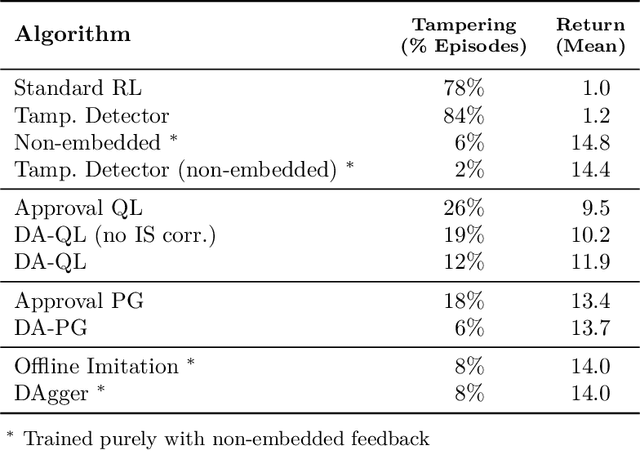

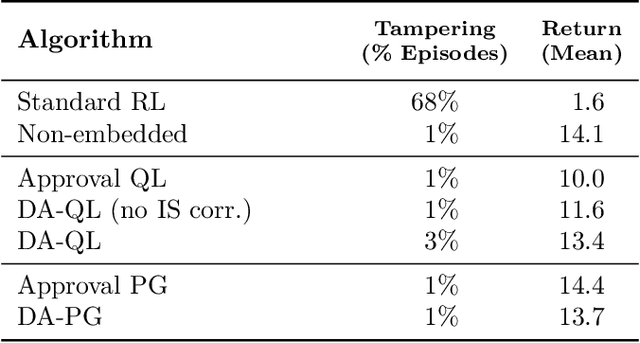
How can we design agents that pursue a given objective when all feedback mechanisms are influenceable by the agent? Standard RL algorithms assume a secure reward function, and can thus perform poorly in settings where agents can tamper with the reward-generating mechanism. We present a principled solution to the problem of learning from influenceable feedback, which combines approval with a decoupled feedback collection procedure. For a natural class of corruption functions, decoupled approval algorithms have aligned incentives both at convergence and for their local updates. Empirically, they also scale to complex 3D environments where tampering is possible.
REALab: An Embedded Perspective on Tampering
Nov 17, 2020

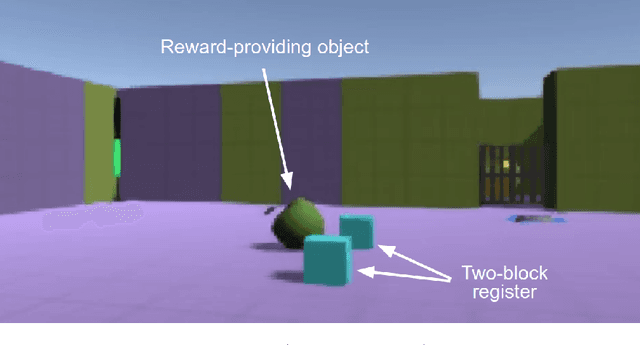

This paper describes REALab, a platform for embedded agency research in reinforcement learning (RL). REALab is designed to model the structure of tampering problems that may arise in real-world deployments of RL. Standard Markov Decision Process (MDP) formulations of RL and simulated environments mirroring the MDP structure assume secure access to feedback (e.g., rewards). This may be unrealistic in settings where agents are embedded and can corrupt the processes producing feedback (e.g., human supervisors, or an implemented reward function). We describe an alternative Corrupt Feedback MDP formulation and the REALab environment platform, which both avoid the secure feedback assumption. We hope the design of REALab provides a useful perspective on tampering problems, and that the platform may serve as a unit test for the presence of tampering incentives in RL agent designs.
Algorithms for Causal Reasoning in Probability Trees
Nov 12, 2020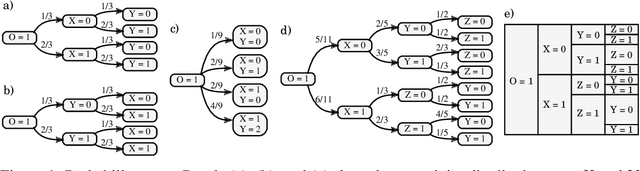
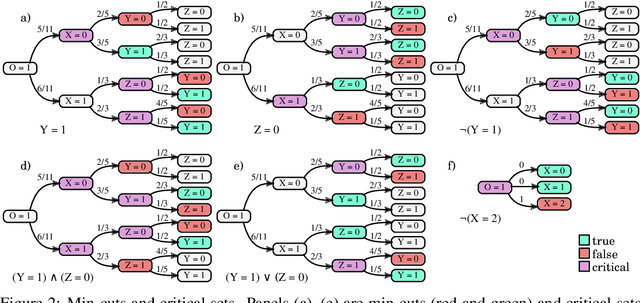


Probability trees are one of the simplest models of causal generative processes. They possess clean semantics and -- unlike causal Bayesian networks -- they can represent context-specific causal dependencies, which are necessary for e.g. causal induction. Yet, they have received little attention from the AI and ML community. Here we present concrete algorithms for causal reasoning in discrete probability trees that cover the entire causal hierarchy (association, intervention, and counterfactuals), and operate on arbitrary propositional and causal events. Our work expands the domain of causal reasoning to a very general class of discrete stochastic processes.
Meta-trained agents implement Bayes-optimal agents
Oct 21, 2020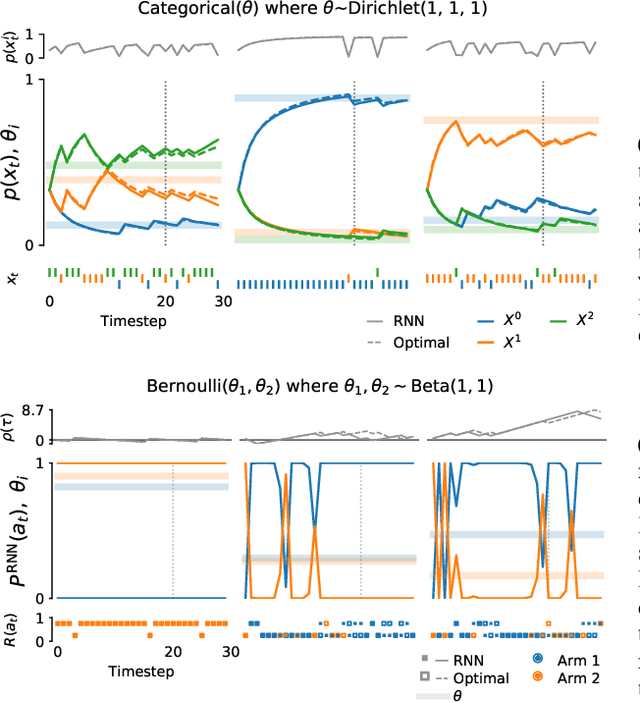

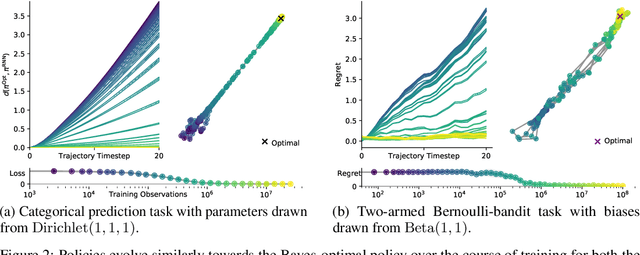
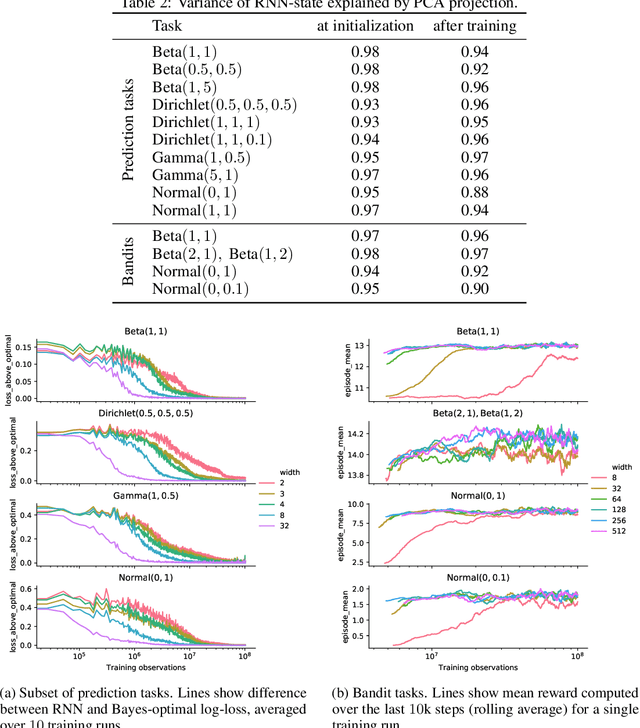
Memory-based meta-learning is a powerful technique to build agents that adapt fast to any task within a target distribution. A previous theoretical study has argued that this remarkable performance is because the meta-training protocol incentivises agents to behave Bayes-optimally. We empirically investigate this claim on a number of prediction and bandit tasks. Inspired by ideas from theoretical computer science, we show that meta-learned and Bayes-optimal agents not only behave alike, but they even share a similar computational structure, in the sense that one agent system can approximately simulate the other. Furthermore, we show that Bayes-optimal agents are fixed points of the meta-learning dynamics. Our results suggest that memory-based meta-learning might serve as a general technique for numerically approximating Bayes-optimal agents - that is, even for task distributions for which we currently don't possess tractable models.
Avoiding Side Effects By Considering Future Tasks
Oct 15, 2020

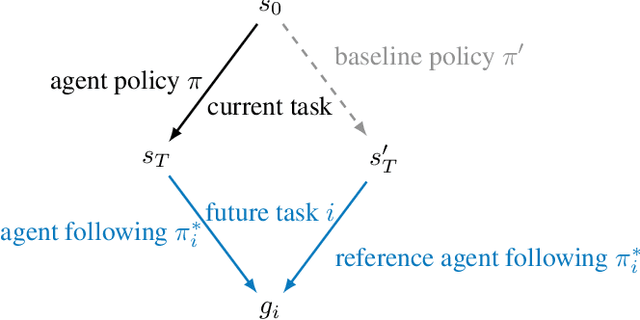
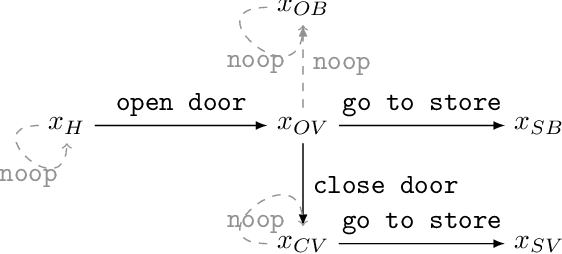
Designing reward functions is difficult: the designer has to specify what to do (what it means to complete the task) as well as what not to do (side effects that should be avoided while completing the task). To alleviate the burden on the reward designer, we propose an algorithm to automatically generate an auxiliary reward function that penalizes side effects. This auxiliary objective rewards the ability to complete possible future tasks, which decreases if the agent causes side effects during the current task. The future task reward can also give the agent an incentive to interfere with events in the environment that make future tasks less achievable, such as irreversible actions by other agents. To avoid this interference incentive, we introduce a baseline policy that represents a default course of action (such as doing nothing), and use it to filter out future tasks that are not achievable by default. We formally define interference incentives and show that the future task approach with a baseline policy avoids these incentives in the deterministic case. Using gridworld environments that test for side effects and interference, we show that our method avoids interference and is more effective for avoiding side effects than the common approach of penalizing irreversible actions.
Quantifying Differences in Reward Functions
Jun 24, 2020
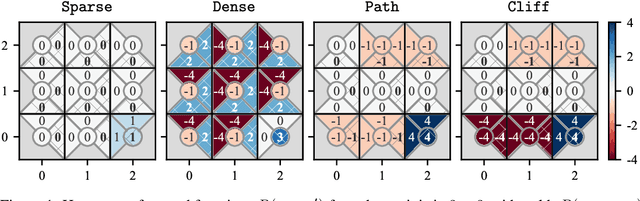

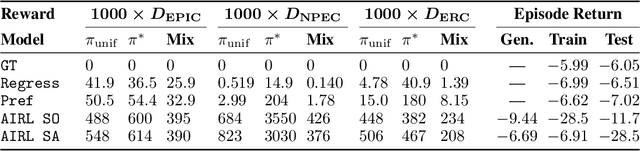
For many tasks, the reward function is too complex to be specified procedurally, and must instead be learned from user data. Prior work has evaluated learned reward functions by examining rollouts from a policy optimized for the learned reward. However, this method cannot distinguish between the learned reward function failing to reflect user preferences, and the reinforcement learning algorithm failing to optimize the learned reward. Moreover, the rollout method is highly sensitive to details of the environment the learned reward is evaluated in, which often differ in the deployment environment. To address these problems, we introduce the Equivalent-Policy Invariant Comparison (EPIC) distance to quantify the difference between two reward functions directly, without training a policy. We prove EPIC is invariant on an equivalence class of reward functions that always induce the same optimal policy. Furthermore, we find EPIC can be precisely approximated and is more robust than baselines to the choice of visitation distribution. Finally, we find that the EPIC distance of learned reward functions to the ground-truth reward is predictive of the success of training a policy, even in different transition dynamics.
Pitfalls of learning a reward function online
Apr 28, 2020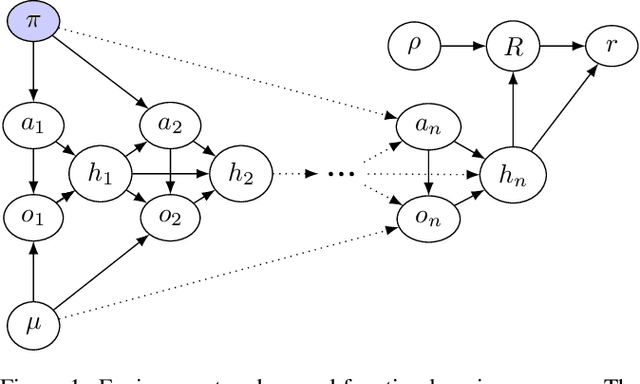
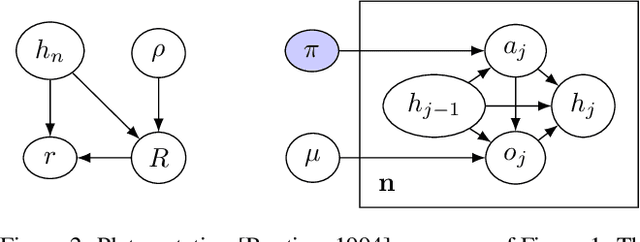
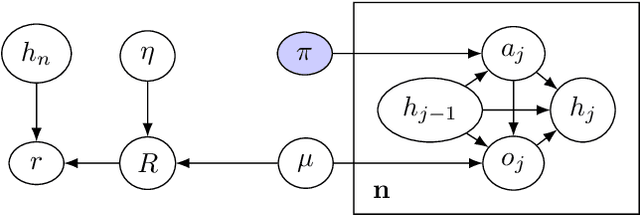

In some agent designs like inverse reinforcement learning an agent needs to learn its own reward function. Learning the reward function and optimising for it are typically two different processes, usually performed at different stages. We consider a continual (``one life'') learning approach where the agent both learns the reward function and optimises for it at the same time. We show that this comes with a number of pitfalls, such as deliberately manipulating the learning process in one direction, refusing to learn, ``learning'' facts already known to the agent, and making decisions that are strictly dominated (for all relevant reward functions). We formally introduce two desirable properties: the first is `unriggability', which prevents the agent from steering the learning process in the direction of a reward function that is easier to optimise. The second is `uninfluenceability', whereby the reward-function learning process operates by learning facts about the environment. We show that an uninfluenceable process is automatically unriggable, and if the set of possible environments is sufficiently rich, the converse is true too.