 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Audio-Visual Features for Multimodal Deepfake Detection
Oct 05, 2023



Deepfakes are AI-generated media in which an image or video has been digitally modified. The advancements made in deepfake technology have led to privacy and security issues. Most deepfake detection techniques rely on the detection of a single modality. Existing methods for audio-visual detection do not always surpass that of the analysis based on single modalities. Therefore, this paper proposes an audio-visual-based method for deepfake detection, which integrates fine-grained deepfake identification with binary classification. We categorize the samples into four types by combining labels specific to each single modality. This method enhances the detection under intra-domain and cross-domain testing.
Improving Fairness in Deepfake Detection
Jun 29, 2023



Despite the development of effective deepfake detection models in recent years, several recent studies have demonstrated that biases in the training data utilized to develop deepfake detection models can lead to unfair performance for demographic groups of different races and/or genders. Such can result in these groups being unfairly targeted or excluded from detection, allowing misclassified deepfakes to manipulate public opinion and erode trust in the model. While these studies have focused on identifying and evaluating the unfairness in deepfake detection, no methods have been developed to address the fairness issue of deepfake detection at the algorithm level. In this work, we make the first attempt to improve deepfake detection fairness by proposing novel loss functions to train fair deepfake detection models in ways that are agnostic or aware of demographic factors. Extensive experiments on four deepfake datasets and five deepfake detectors demonstrate the effectiveness and flexibility of our approach in improving the deepfake detection fairness.
UPDExplainer: an Interpretable Transformer-based Framework for Urban Physical Disorder Detection Using Street View Imagery
May 04, 2023Urban Physical Disorder (UPD), such as old or abandoned buildings, broken sidewalks, litter, and graffiti, has a negative impact on residents' quality of life. They can also increase crime rates, cause social disorder, and pose a public health risk. Currently, there is a lack of efficient and reliable methods for detecting and understanding UPD. To bridge this gap, we propose UPDExplainer, an interpretable transformer-based framework for UPD detection. We first develop a UPD detection model based on the Swin Transformer architecture, which leverages readily accessible street view images to learn discriminative representations. In order to provide clear and comprehensible evidence and analysis, we subsequently introduce a UPD factor identification and ranking module that combines visual explanation maps with semantic segmentation maps. This novel integrated approach enables us to identify the exact objects within street view images that are responsible for physical disorders and gain insights into the underlying causes. Experimental results on the re-annotated Place Pulse 2.0 dataset demonstrate promising detection performance of the proposed method, with an accuracy of 79.9%. For a comprehensive evaluation of the method's ranking performance, we report the mean Average Precision (mAP), R-Precision (RPrec), and Normalized Discounted Cumulative Gain (NDCG), with success rates of 75.51%, 80.61%, and 82.58%, respectively. We also present a case study of detecting and ranking physical disorders in the southern region of downtown Los Angeles, California, to demonstrate the practicality and effectiveness of our framework.
AI-Synthesized Voice Detection Using Neural Vocoder Artifacts
Apr 27, 2023



Advancements in AI-synthesized human voices have created a growing threat of impersonation and disinformation, making it crucial to develop methods to detect synthetic human voices. This study proposes a new approach to identifying synthetic human voices by detecting artifacts of vocoders in audio signals. Most DeepFake audio synthesis models use a neural vocoder, a neural network that generates waveforms from temporal-frequency representations like mel-spectrograms. By identifying neural vocoder processing in audio, we can determine if a sample is synthesized. To detect synthetic human voices, we introduce a multi-task learning framework for a binary-class RawNet2 model that shares the feature extractor with a vocoder identification module. By treating vocoder identification as a pretext task, we constrain the feature extractor to focus on vocoder artifacts and provide discriminative features for the final binary classifier. Our experiments show that the improved RawNet2 model based on vocoder identification achieves high classification performance on the binary task overall.
AutoSplice: A Text-prompt Manipulated Image Dataset for Media Forensics
Apr 14, 2023



Recent advancements in language-image models have led to the development of highly realistic images that can be generated from textual descriptions. However, the increased visual quality of these generated images poses a potential threat to the field of media forensics. This paper aims to investigate the level of challenge that language-image generation models pose to media forensics. To achieve this, we propose a new approach that leverages the DALL-E2 language-image model to automatically generate and splice masked regions guided by a text prompt. To ensure the creation of realistic manipulations, we have designed an annotation platform with human checking to verify reasonable text prompts. This approach has resulted in the creation of a new image dataset called AutoSplice, containing 5,894 manipulated and authentic images. Specifically, we have generated a total of 3,621 images by locally or globally manipulating real-world image-caption pairs, which we believe will provide a valuable resource for developing generalized detection methods in this area. The dataset is evaluated under two media forensic tasks: forgery detection and localization. Our extensive experiments show that most media forensic models struggle to detect the AutoSplice dataset as an unseen manipulation. However, when fine-tuned models are used, they exhibit improved performance in both tasks.
Exposing AI-Synthesized Human Voices Using Neural Vocoder Artifacts
Feb 18, 2023The advancements of AI-synthesized human voices have introduced a growing threat of impersonation and disinformation. It is therefore of practical importance to developdetection methods for synthetic human voices. This work proposes a new approach to detect synthetic human voices based on identifying artifacts of neural vocoders in audio signals. A neural vocoder is a specially designed neural network that synthesizes waveforms from temporal-frequency representations, e.g., mel-spectrograms. The neural vocoder is a core component in most DeepFake audio synthesis models. Hence the identification of neural vocoder processing implies that an audio sample may have been synthesized. To take advantage of the vocoder artifacts for synthetic human voice detection, we introduce a multi-task learning framework for a binary-class RawNet2 model that shares the front-end feature extractor with a vocoder identification module. We treat the vocoder identification as a pretext task to constrain the front-end feature extractor to focus on vocoder artifacts and provide discriminative features for the final binary classifier. Our experiments show that the improved RawNet2 model based on vocoder identification achieves an overall high classification performance on the binary task.
GLFF: Global and Local Feature Fusion for Face Forgery Detection
Nov 26, 2022



With the rapid development of deep generative models (such as Generative Adversarial Networks and Auto-encoders), AI-synthesized images of the human face are now of such high quality that humans can hardly distinguish them from pristine ones. Although existing detection methods have shown high performance in specific evaluation settings, e.g., on images from seen models or on images without real-world post-processings, they tend to suffer serious performance degradation in real-world scenarios where testing images can be generated by more powerful generation models or combined with various post-processing operations. To address this issue, we propose a Global and Local Feature Fusion (GLFF) to learn rich and discriminative representations by combining multi-scale global features from the whole image with refined local features from informative patches for face forgery detection. GLFF fuses information from two branches: the global branch to extract multi-scale semantic features and the local branch to select informative patches for detailed local artifacts extraction. Due to the lack of a face forgery dataset simulating real-world applications for evaluation, we further create a challenging face forgery dataset, named DeepFakeFaceForensics (DF^3), which contains 6 state-of-the-art generation models and a variety of post-processing techniques to approach the real-world scenarios. Experimental results demonstrate the superiority of our method to the state-of-the-art methods on the proposed DF^3 dataset and three other open-source datasets.
Fusion-based Few-Shot Morphing Attack Detection and Fingerprinting
Oct 27, 2022The vulnerability of face recognition systems to morphing attacks has posed a serious security threat due to the wide adoption of face biometrics in the real world. Most existing morphing attack detection (MAD) methods require a large amount of training data and have only been tested on a few predefined attack models. The lack of good generalization properties, especially in view of the growing interest in developing novel morphing attacks, is a critical limitation with existing MAD research. To address this issue, we propose to extend MAD from supervised learning to few-shot learning and from binary detection to multiclass fingerprinting in this paper. Our technical contributions include: 1) We propose a fusion-based few-shot learning (FSL) method to learn discriminative features that can generalize to unseen morphing attack types from predefined presentation attacks; 2) The proposed FSL based on the fusion of the PRNU model and Noiseprint network is extended from binary MAD to multiclass morphing attack fingerprinting (MAF). 3) We have collected a large-scale database, which contains five face datasets and eight different morphing algorithms, to benchmark the proposed few-shot MAF (FS-MAF) method. Extensive experimental results show the outstanding performance of our fusion-based FS-MAF. The code and data will be publicly available at https://github.com/nz0001na/mad maf.
Joint Learning of Deep Texture and High-Frequency Features for Computer-Generated Image Detection
Sep 07, 2022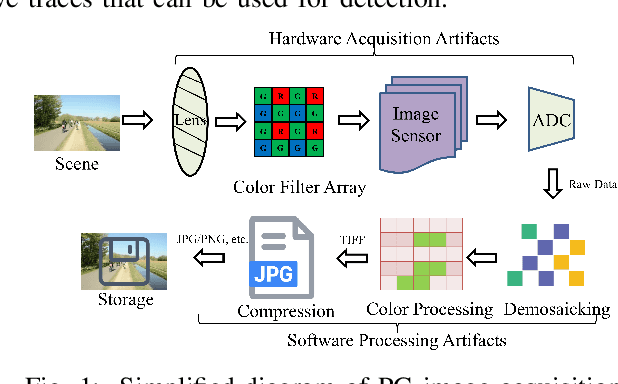

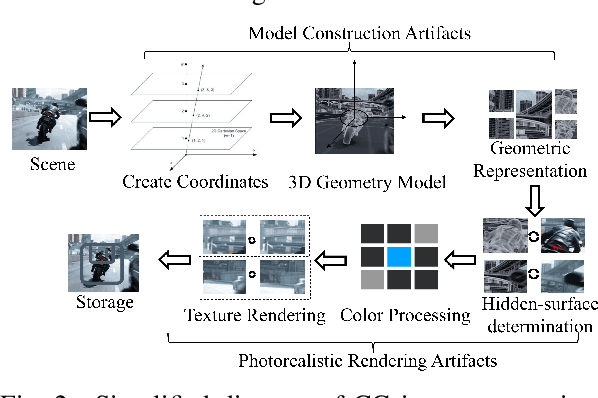
Distinguishing between computer-generated (CG) and natural photographic (PG) images is of great importance to verify the authenticity and originality of digital images. However, the recent cutting-edge generation methods enable high qualities of synthesis in CG images, which makes this challenging task even trickier. To address this issue, a joint learning strategy with deep texture and high-frequency features for CG image detection is proposed. We first formulate and deeply analyze the different acquisition processes of CG and PG images. Based on the finding that multiple different modules in image acquisition will lead to different sensitivity inconsistencies to the convolutional neural network (CNN)-based rendering in images, we propose a deep texture rendering module for texture difference enhancement and discriminative texture representation. Specifically, the semantic segmentation map is generated to guide the affine transformation operation, which is used to recover the texture in different regions of the input image. Then, the combination of the original image and the high-frequency components of the original and rendered images are fed into a multi-branch neural network equipped with attention mechanisms, which refines intermediate features and facilitates trace exploration in spatial and channel dimensions respectively. Extensive experiments on two public datasets and a newly constructed dataset with more realistic and diverse images show that the proposed approach outperforms existing methods in the field by a clear margin. Besides, results also demonstrate the detection robustness and generalization ability of the proposed approach to postprocessing operations and generative adversarial network (GAN) generated images.
A Saliency-Guided Street View Image Inpainting Framework for Efficient Last-Meters Wayfinding
May 14, 2022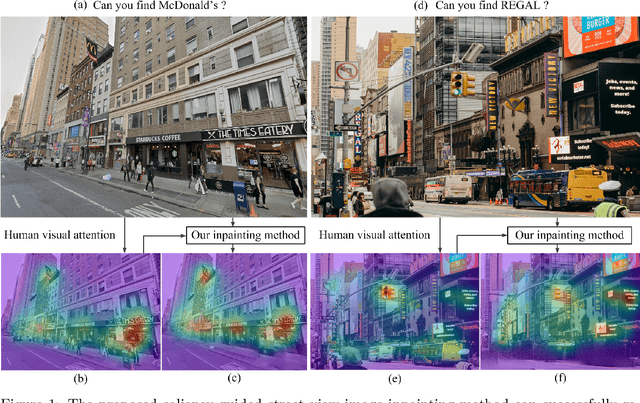
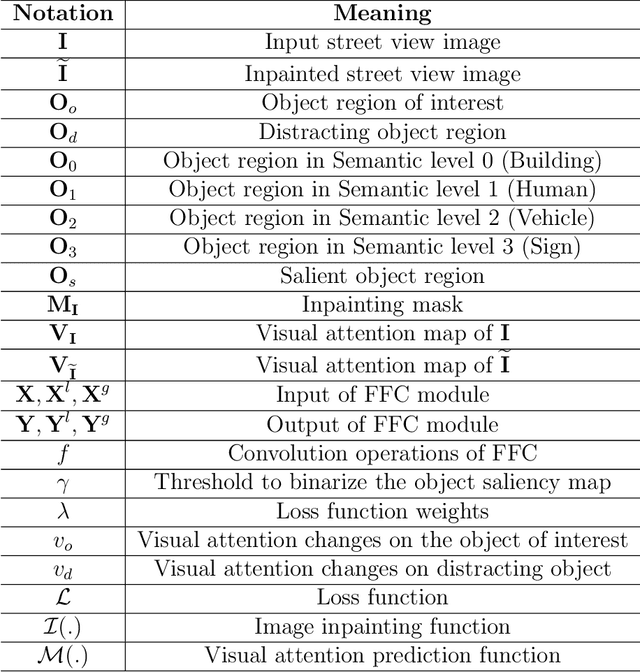
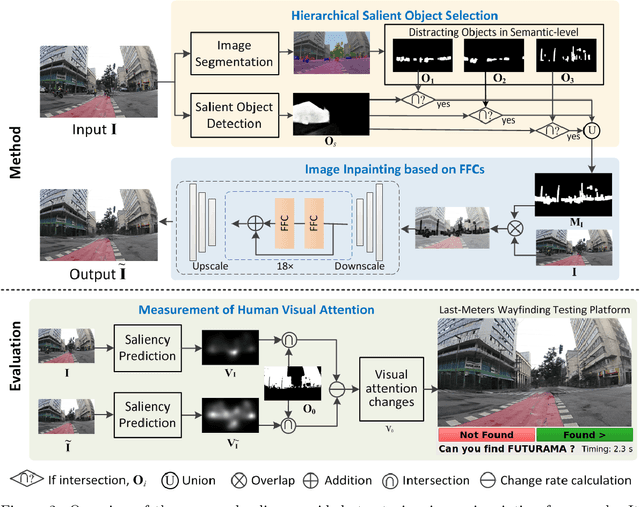

Global Positioning Systems (GPS) have played a crucial role in various navigation applications. Nevertheless, localizing the perfect destination within the last few meters remains an important but unresolved problem. Limited by the GPS positioning accuracy, navigation systems always show users a vicinity of a destination, but not its exact location. Street view images (SVI) in maps as an immersive media technology have served as an aid to provide the physical environment for human last-meters wayfinding. However, due to the large diversity of geographic context and acquisition conditions, the captured SVI always contains various distracting objects (e.g., pedestrians and vehicles), which will distract human visual attention from efficiently finding the destination in the last few meters. To address this problem, we highlight the importance of reducing visual distraction in image-based wayfinding by proposing a saliency-guided image inpainting framework. It aims at redirecting human visual attention from distracting objects to destination-related objects for more efficient and accurate wayfinding in the last meters. Specifically, a context-aware distracting object detection method driven by deep salient object detection has been designed to extract distracting objects from three semantic levels in SVI. Then we employ a large-mask inpainting method with fast Fourier convolutions to remove the detected distracting objects. Experimental results with both qualitative and quantitative analysis show that our saliency-guided inpainting method can not only achieve great perceptual quality in street view images but also redirect the human's visual attention to focus more on static location-related objects than distracting ones. The human-based evaluation also justified the effectiveness of our method in improving the efficiency of locating the target destination.