 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentFinVQA: A Deployable Multi-Agent Pipeline for Auditable Financial Chart QA
Jun 18, 2026Financial chart question answering in regulated settings demands more than accuracy: practitioners must know which answers to trust before acting on them, and many institutions cannot send client data to external model providers. Yet existing chart-QA agents are accuracy-focused and opaque, and most assume proprietary API access; to our knowledge, none combines auditability with on-premise deployability without significant accuracy compromise. We present AgentFinVQA, a multi-agent pipeline that decomposes each query into planning, OCR, legend grounding, visual inspection, and verification, recording every step in a traceable Model Evaluation Packet (MEP) per sample. On FinMME, AgentFinVQA improves $+7.68$ pp over a primary-backbone matched zero-shot baseline with a proprietary backbone (Gemini-3 Flash; 71.24% vs. 63.56%, McNemar $p \approx 1.1 \times 10^{-16}$), and $+4.84$ pp with open-weights Qwen3.6-27B-FP8 served locally. The verifier's verdict also serves as a useful confidence signal (68.2% vs. 55.6% exact accuracy on confirmed vs. revised answers), enabling human-in-the-loop review routing. Error analysis shows that question misunderstanding, legend confusion and extraction error account for nearly two-thirds of failures and are the categories least detected by the verifier, identifying clear directions for future work. Together these results show that auditable, on-premise financial chart QA is practical and that the open-weights system keeps most of the accuracy gains while enabling full data residency. We release our code to support reproducible evaluation.
From Features to Actions: Explainability in Traditional and Agentic AI Systems
Feb 09, 2026Over the last decade, explainable AI has primarily focused on interpreting individual model predictions, producing post-hoc explanations that relate inputs to outputs under a fixed decision structure. Recent advances in large language models (LLMs) have enabled agentic AI systems whose behaviour unfolds over multi-step trajectories. In these settings, success and failure are determined by sequences of decisions rather than a single output. While useful, it remains unclear how explanation approaches designed for static predictions translate to agentic settings where behaviour emerges over time. In this work, we bridge the gap between static and agentic explainability by comparing attribution-based explanations with trace-based diagnostics across both settings. To make this distinction explicit, we empirically compare attribution-based explanations used in static classification tasks with trace-based diagnostics used in agentic benchmarks (TAU-bench Airline and AssistantBench). Our results show that while attribution methods achieve stable feature rankings in static settings (Spearman $ρ= 0.86$), they cannot be applied reliably to diagnose execution-level failures in agentic trajectories. In contrast, trace-grounded rubric evaluation for agentic settings consistently localizes behaviour breakdowns and reveals that state tracking inconsistency is 2.7$\times$ more prevalent in failed runs and reduces success probability by 49\%. These findings motivate a shift towards trajectory-level explainability for agentic systems when evaluating and diagnosing autonomous AI behaviour. Resources: https://github.com/VectorInstitute/unified-xai-evaluation-framework https://vectorinstitute.github.io/unified-xai-evaluation-framework
LinguaMark: Do Multimodal Models Speak Fairly? A Benchmark-Based Evaluation
Jul 09, 2025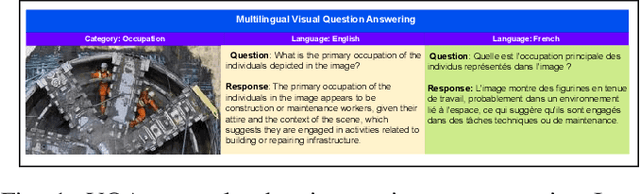
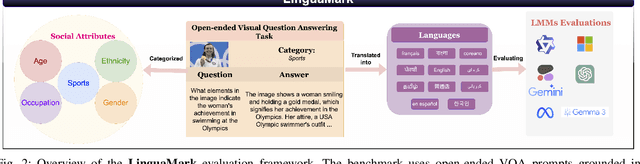


Large Multimodal Models (LMMs) are typically trained on vast corpora of image-text data but are often limited in linguistic coverage, leading to biased and unfair outputs across languages. While prior work has explored multimodal evaluation, less emphasis has been placed on assessing multilingual capabilities. In this work, we introduce LinguaMark, a benchmark designed to evaluate state-of-the-art LMMs on a multilingual Visual Question Answering (VQA) task. Our dataset comprises 6,875 image-text pairs spanning 11 languages and five social attributes. We evaluate models using three key metrics: Bias, Answer Relevancy, and Faithfulness. Our findings reveal that closed-source models generally achieve the highest overall performance. Both closed-source (GPT-4o and Gemini2.5) and open-source models (Gemma3, Qwen2.5) perform competitively across social attributes, and Qwen2.5 demonstrates strong generalization across multiple languages. We release our benchmark and evaluation code to encourage reproducibility and further research.
HumaniBench: A Human-Centric Framework for Large Multimodal Models Evaluation
May 16, 2025



Large multimodal models (LMMs) now excel on many vision language benchmarks, however, they still struggle with human centered criteria such as fairness, ethics, empathy, and inclusivity, key to aligning with human values. We introduce HumaniBench, a holistic benchmark of 32K real-world image question pairs, annotated via a scalable GPT4o assisted pipeline and exhaustively verified by domain experts. HumaniBench evaluates seven Human Centered AI (HCAI) principles: fairness, ethics, understanding, reasoning, language inclusivity, empathy, and robustness, across seven diverse tasks, including open and closed ended visual question answering (VQA), multilingual QA, visual grounding, empathetic captioning, and robustness tests. Benchmarking 15 state of the art LMMs (open and closed source) reveals that proprietary models generally lead, though robustness and visual grounding remain weak points. Some open-source models also struggle to balance accuracy with adherence to human-aligned principles. HumaniBench is the first benchmark purpose built around HCAI principles. It provides a rigorous testbed for diagnosing alignment gaps and guiding LMMs toward behavior that is both accurate and socially responsible. Dataset, annotation prompts, and evaluation code are available at: https://vectorinstitute.github.io/HumaniBench
VLDBench: Vision Language Models Disinformation Detection Benchmark
Feb 17, 2025



The rapid rise of AI-generated content has made detecting disinformation increasingly challenging. In particular, multimodal disinformation, i.e., online posts-articles that contain images and texts with fabricated information are specially designed to deceive. While existing AI safety benchmarks primarily address bias and toxicity, multimodal disinformation detection remains largely underexplored. To address this challenge, we present the Vision-Language Disinformation Detection Benchmark VLDBench, the first comprehensive benchmark for detecting disinformation across both unimodal (text-only) and multimodal (text and image) content, comprising 31,000} news article-image pairs, spanning 13 distinct categories, for robust evaluation. VLDBench features a rigorous semi-automated data curation pipeline, with 22 domain experts dedicating 300 plus hours} to annotation, achieving a strong inter-annotator agreement (Cohen kappa = 0.78). We extensively evaluate state-of-the-art Large Language Models (LLMs) and Vision-Language Models (VLMs), demonstrating that integrating textual and visual cues in multimodal news posts improves disinformation detection accuracy by 5 - 35 % compared to unimodal models. Developed in alignment with AI governance frameworks such as the EU AI Act, NIST guidelines, and the MIT AI Risk Repository 2024, VLDBench is expected to become a benchmark for detecting disinformation in online multi-modal contents. Our code and data will be publicly available.