 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Prior Knowledge Graphs for Detection and Instance Segmentation
Oct 11, 2023



Humans have a remarkable ability to perceive and reason about the world around them by understanding the relationships between objects. In this paper, we investigate the effectiveness of using such relationships for object detection and instance segmentation. To this end, we propose a Relational Prior-based Feature Enhancement Model (RP-FEM), a graph transformer that enhances object proposal features using relational priors. The proposed architecture operates on top of scene graphs obtained from initial proposals and aims to concurrently learn relational context modeling for object detection and instance segmentation. Experimental evaluations on COCO show that the utilization of scene graphs, augmented with relational priors, offer benefits for object detection and instance segmentation. RP-FEM demonstrates its capacity to suppress improbable class predictions within the image while also preventing the model from generating duplicate predictions, leading to improvements over the baseline model on which it is built.
Intrinsic Appearance Decomposition Using Point Cloud Representation
Jul 20, 2023



Intrinsic decomposition is to infer the albedo and shading from the image. Since it is a heavily ill-posed problem, previous methods rely on prior assumptions from 2D images, however, the exploration of the data representation itself is limited. The point cloud is known as a rich format of scene representation, which naturally aligns the geometric information and the color information of an image. Our proposed method, Point Intrinsic Net, in short, PoInt-Net, jointly predicts the albedo, light source direction, and shading, using point cloud representation. Experiments reveal the benefits of PoInt-Net, in terms of accuracy, it outperforms 2D representation approaches on multiple metrics across datasets; in terms of efficiency, it trains on small-scale point clouds and performs stably on any-scale point clouds; in terms of robustness, it only trains on single object level dataset, and demonstrates reasonable generalization ability for unseen objects and scenes.
SIGNet: Intrinsic Image Decomposition by a Semantic and Invariant Gradient Driven Network for Indoor Scenes
Aug 30, 2022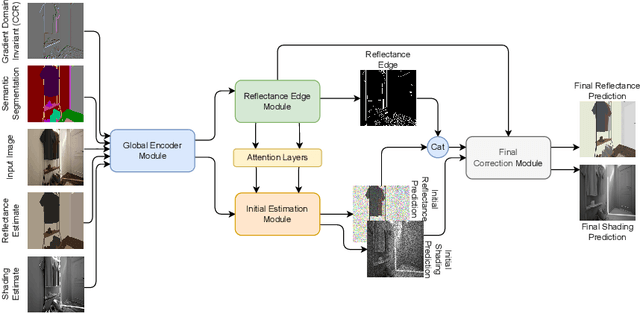
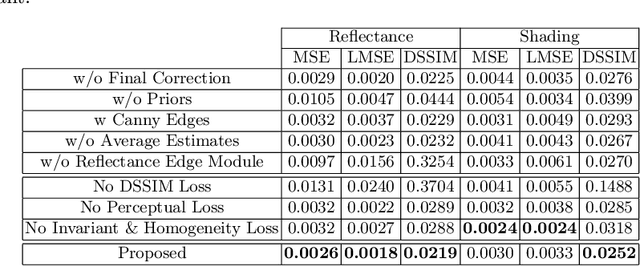
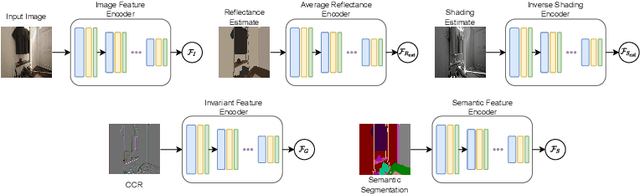
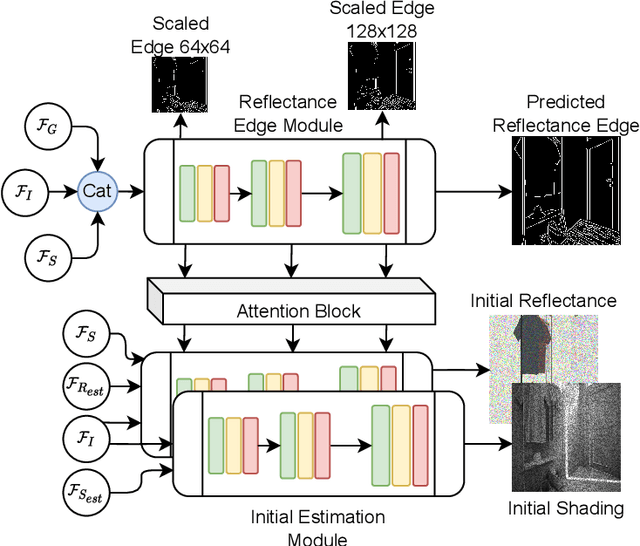
Intrinsic image decomposition (IID) is an under-constrained problem. Therefore, traditional approaches use hand crafted priors to constrain the problem. However, these constraints are limited when coping with complex scenes. Deep learning-based approaches learn these constraints implicitly through the data, but they often suffer from dataset biases (due to not being able to include all possible imaging conditions). In this paper, a combination of the two is proposed. Component specific priors like semantics and invariant features are exploited to obtain semantically and physically plausible reflectance transitions. These transitions are used to steer a progressive CNN with implicit homogeneity constraints to decompose reflectance and shading maps. An ablation study is conducted showing that the use of the proposed priors and progressive CNN increase the IID performance. State of the art performance on both our proposed dataset and the standard real-world IIW dataset shows the effectiveness of the proposed method. Code is made available at https://github.com/Morpheus3000/SIGNet
PIE-Net: Photometric Invariant Edge Guided Network for Intrinsic Image Decomposition
Mar 30, 2022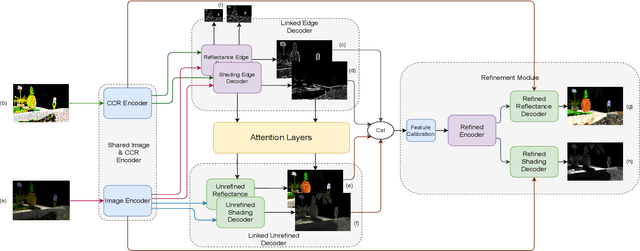
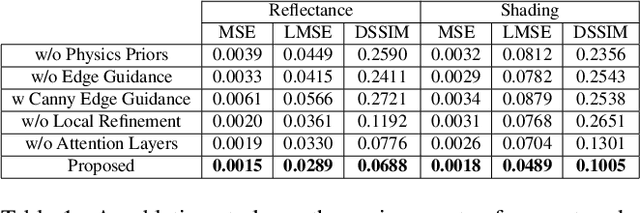

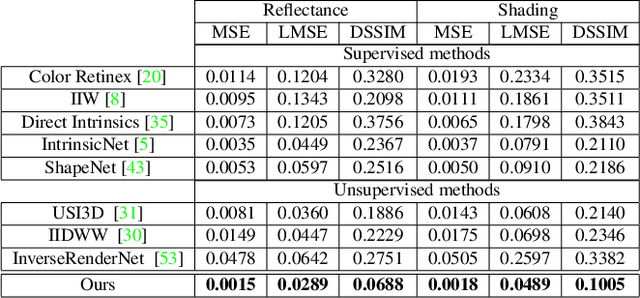
Intrinsic image decomposition is the process of recovering the image formation components (reflectance and shading) from an image. Previous methods employ either explicit priors to constrain the problem or implicit constraints as formulated by their losses (deep learning). These methods can be negatively influenced by strong illumination conditions causing shading-reflectance leakages. Therefore, in this paper, an end-to-end edge-driven hybrid CNN approach is proposed for intrinsic image decomposition. Edges correspond to illumination invariant gradients. To handle hard negative illumination transitions, a hierarchical approach is taken including global and local refinement layers. We make use of attention layers to further strengthen the learning process. An extensive ablation study and large scale experiments are conducted showing that it is beneficial for edge-driven hybrid IID networks to make use of illumination invariant descriptors and that separating global and local cues helps in improving the performance of the network. Finally, it is shown that the proposed method obtains state of the art performance and is able to generalise well to real world images. The project page with pretrained models, finetuned models and network code can be found at https://ivi.fnwi.uva.nl/cv/pienet/.
Generative Models for Multi-Illumination Color Constancy
Sep 02, 2021
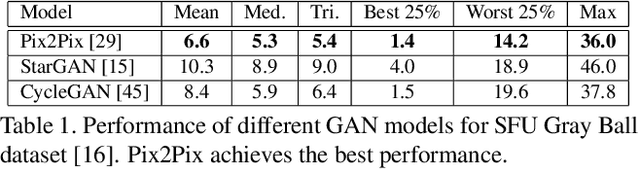
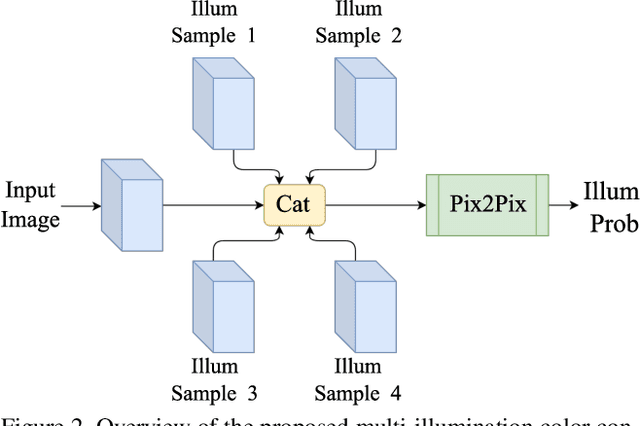
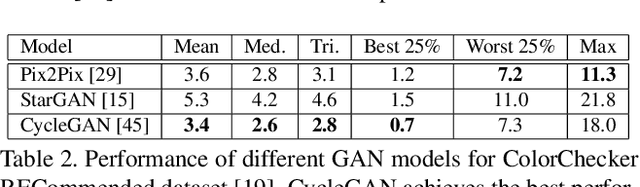
In this paper, the aim is multi-illumination color constancy. However, most of the existing color constancy methods are designed for single light sources. Furthermore, datasets for learning multiple illumination color constancy are largely missing. We propose a seed (physics driven) based multi-illumination color constancy method. GANs are exploited to model the illumination estimation problem as an image-to-image domain translation problem. Additionally, a novel multi-illumination data augmentation method is proposed. Experiments on single and multi-illumination datasets show that our methods outperform sota methods.
EDEN: Multimodal Synthetic Dataset of Enclosed GarDEN Scenes
Nov 10, 2020
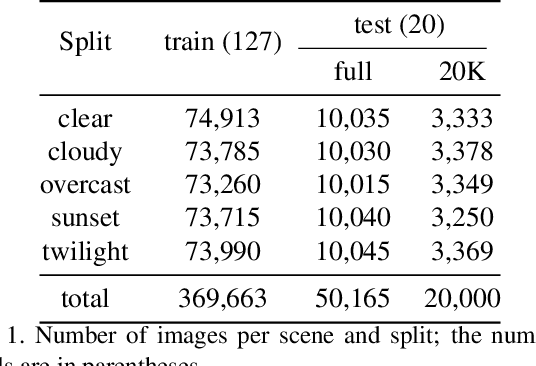

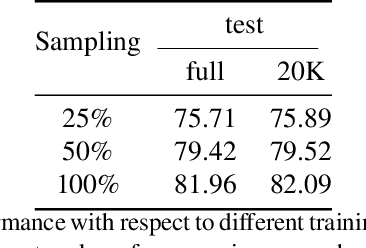
Multimodal large-scale datasets for outdoor scenes are mostly designed for urban driving problems. The scenes are highly structured and semantically different from scenarios seen in nature-centered scenes such as gardens or parks. To promote machine learning methods for nature-oriented applications, such as agriculture and gardening, we propose the multimodal synthetic dataset for Enclosed garDEN scenes (EDEN). The dataset features more than 300K images captured from more than 100 garden models. Each image is annotated with various low/high-level vision modalities, including semantic segmentation, depth, surface normals, intrinsic colors, and optical flow. Experimental results on the state-of-the-art methods for semantic segmentation and monocular depth prediction, two important tasks in computer vision, show positive impact of pre-training deep networks on our dataset for unstructured natural scenes. The dataset and related materials will be available at https://lhoangan.github.io/eden.
Spatio-temporal Features for Generalized Detection of Deepfake Videos
Oct 22, 2020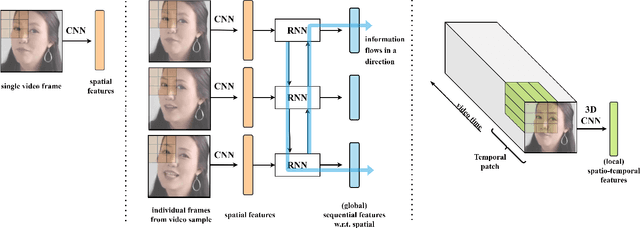

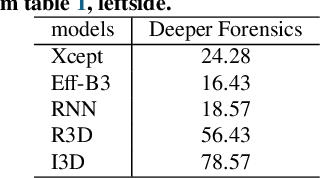
For deepfake detection, video-level detectors have not been explored as extensively as image-level detectors, which do not exploit temporal data. In this paper, we empirically show that existing approaches on image and sequence classifiers generalize poorly to new manipulation techniques. To this end, we propose spatio-temporal features, modeled by 3D CNNs, to extend the generalization capabilities to detect new sorts of deepfake videos. We show that spatial features learn distinct deepfake-method-specific attributes, while spatio-temporal features capture shared attributes between deepfake methods. We provide an in-depth analysis of how the sequential and spatio-temporal video encoders are utilizing temporal information using DFDC dataset arXiv:2006.07397. Thus, we unravel that our approach captures local spatio-temporal relations and inconsistencies in the deepfake videos while existing sequence encoders are indifferent to it. Through large scale experiments conducted on the FaceForensics++ arXiv:1901.08971 and Deeper Forensics arXiv:2001.03024 datasets, we show that our approach outperforms existing methods in terms of generalization capabilities.
Multi-Loss Weighting with Coefficient of Variations
Sep 03, 2020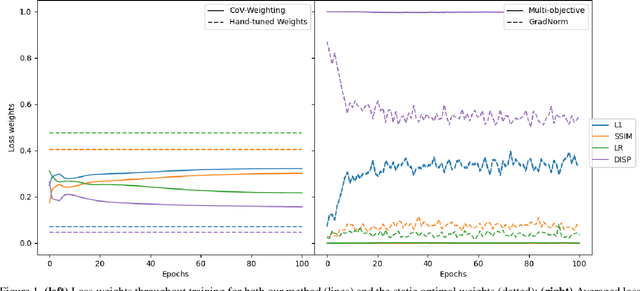

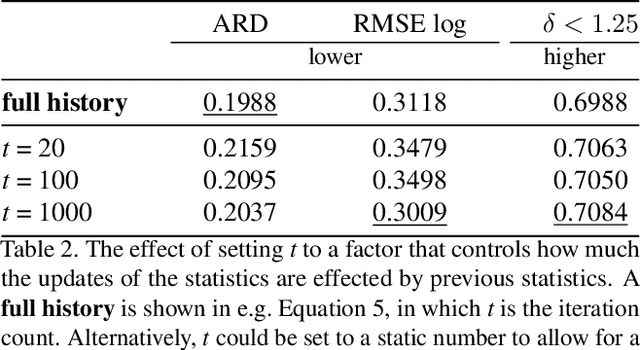
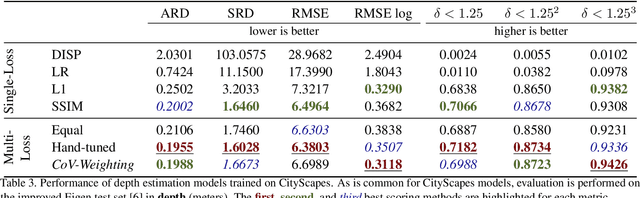
Many interesting tasks in machine learning and computer vision are learned by optimising an objective function defined as a weighted linear combination of multiple losses. The final performance is sensitive to choosing the correct (relative) weights for these losses. Finding a good set of weights is often done by adopting them into the set of hyper-parameters, which are set using an extensive grid search. This is computationally expensive. In this paper, the weights are defined based on properties observed while training the model, including the specific batch loss, the average loss, and the variance for each of the losses. An additional advantage is that the defined weights evolve during training, instead of using static loss weights. In literature, loss weighting is mostly used in a multi-task learning setting, where the different tasks obtain different weights. However, there is a plethora of single-task multi-loss problems that can benefit from automatic loss weighting. In this paper, it is shown that these multi-task approaches do not work on single tasks. Instead, a method is proposed that automatically and dynamically tunes loss weights throughout training specifically for single-task multi-loss problems. The method incorporates a measure of uncertainty to balance the losses. The validity of the approach is shown empirically for different tasks on multiple datasets.
Physics-based Shading Reconstruction for Intrinsic Image Decomposition
Sep 03, 2020



We investigate the use of photometric invariance and deep learning to compute intrinsic images (albedo and shading). We propose albedo and shading gradient descriptors which are derived from physics-based models. Using the descriptors, albedo transitions are masked out and an initial sparse shading map is calculated directly from the corresponding RGB image gradients in a learning-free unsupervised manner. Then, an optimization method is proposed to reconstruct the full dense shading map. Finally, we integrate the generated shading map into a novel deep learning framework to refine it and also to predict corresponding albedo image to achieve intrinsic image decomposition. By doing so, we are the first to directly address the texture and intensity ambiguity problems of the shading estimations. Large scale experiments show that our approach steered by physics-based invariant descriptors achieve superior results on MIT Intrinsics, NIR-RGB Intrinsics, Multi-Illuminant Intrinsic Images, Spectral Intrinsic Images, As Realistic As Possible, and competitive results on Intrinsic Images in the Wild datasets while achieving state-of-the-art shading estimations.
Kinship Identification through Joint Learning Using Kinship Verification Ensemble
Apr 20, 2020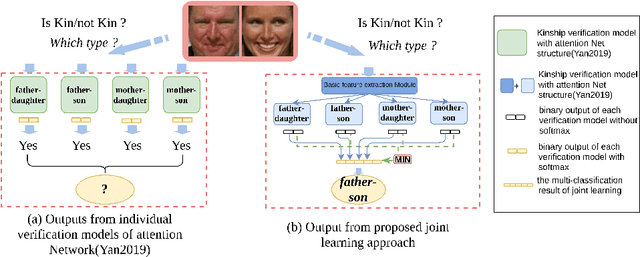
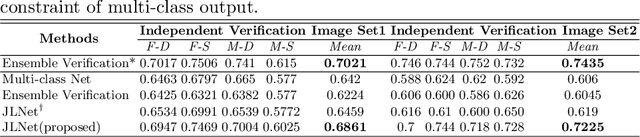
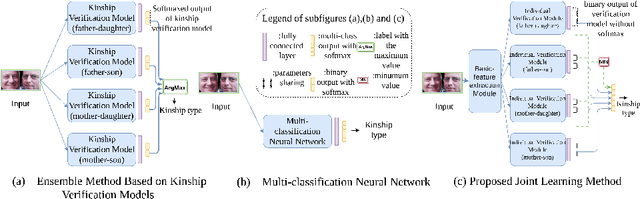
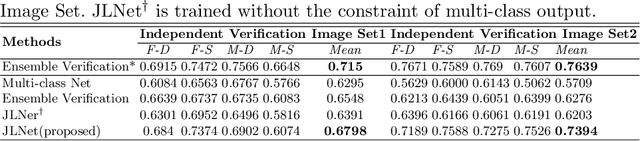
While kinship verification is a well-exploited task which only identifies whether or not two people are kins, kinship identification is the task to further identify the particular type of kinships and is not well exploited yet. We found that a naive extension of kinship verification cannot solve the identification properly. This is because the existing verification networks are individually trained on specific kinships and do not consider the context between different kinship types. Also, the existing kinship verification dataset has a biased positive-negative distribution, which is different from real-world distribution. To solve it, we propose a novel kinship identification approach through the joint training of kinship verification ensembles and a Joint Identification Module. We also propose to rebalance the training dataset to make it realistic. Rigorous experiments demonstrate an appealing performance on kinship identification task. It also demonstrates significant performance improvement of kinship verification when trained on the same unbiased data.