 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Aware, Physics-Informed, Geometry-Grounded Weather Video Synthesis
Jun 27, 2026Weather synthesis aims to add weather effects to input videos while preserving scene identity, structure, and motion. The key limitation of existing methods is the lack of diversity in weather appearance and effective control over weather dynamics (e.g., temporal evolution and particle motion). Most approaches rely on text prompts, which are inherently underspecified and often fail to produce detailed weather characteristics. Additionally, general-purpose video editors optimized for clean and aesthetic outputs tend to suppress heavy weather phenomena, making dense particle effects difficult to generate. To address these, we propose a Semantic-Aware, Physics-Informed, and Geometry-Grounded framework that steers an off-the-shelf video editor to synthesize diverse global appearances and detailed particle dynamics. We factorize the synthesis into three conditional signals, so that each provides a distinct and stable source of guidance: semantics specifies what the weather should look like, dynamics governs how it evolves over time, and geometry determines where it should appear in the scene. Specifically, we introduce (1) semantic-aware appearance anchoring to establish the target appearance from scene semantics and user input; (2) physics-informed dynamic simulation to generate particle effects by simulating a Gaussian-represented particle field under gravity, wind, and turbulence; and (3) geometry-grounded video synthesis to align the simulated particles with target scene geometry and synthesize the final video. Experiments demonstrate that our method produces diverse, physically and visually realistic weather effects. Furthermore, we show that our synthesized data significantly improves the robustness of autonomous driving semantic segmentation under adverse weather conditions. Project page: https://jumponthemoon.github.io/w-crafter/.
From Synchrony to Sequence: Exo-to-Ego Generation via Interpolation
Apr 15, 2026Exo-to-Ego video generation aims to synthesize a first-person video from a synchronized third-person view and corresponding camera poses. While paired supervision is available, synchronized exo-ego data inherently introduces substantial spatio-temporal and geometric discontinuities, violating the smooth-motion assumptions of standard video generation benchmarks. We identify this synchronization-induced jump as the central challenge and propose Syn2Seq-Forcing, a sequential formulation that interpolates between the source and target videos to form a single continuous signal. By reframing Exo2Ego as sequential signal modeling rather than a conventional condition-output task, our approach enables diffusion-based sequence models, e.g. Diffusion Forcing Transformers (DFoT), to capture coherent transitions across frames more effectively. Empirically, we show that interpolating only the videos, without performing pose interpolation already produces significant improvements, emphasizing that the dominant difficulty arises from spatio-temporal discontinuities. Beyond immediate performance gains, this formulation establishes a general and flexible framework capable of unifying both Exo2Ego and Ego2Exo generation within a single continuous sequence model, providing a principled foundation for future research in cross-view video synthesis.
StateSpaceDiffuser: Bringing Long Context to Diffusion World Models
May 28, 2025World models have recently become promising tools for predicting realistic visuals based on actions in complex environments. However, their reliance on a short sequence of observations causes them to quickly lose track of context. As a result, visual consistency breaks down after just a few steps, and generated scenes no longer reflect information seen earlier. This limitation of the state-of-the-art diffusion-based world models comes from their lack of a lasting environment state. To address this problem, we introduce StateSpaceDiffuser, where a diffusion model is enabled to perform on long-context tasks by integrating a sequence representation from a state-space model (Mamba), representing the entire interaction history. This design restores long-term memory without sacrificing the high-fidelity synthesis of diffusion models. To rigorously measure temporal consistency, we develop an evaluation protocol that probes a model's ability to reinstantiate seen content in extended rollouts. Comprehensive experiments show that StateSpaceDiffuser significantly outperforms a strong diffusion-only baseline, maintaining a coherent visual context for an order of magnitude more steps. It delivers consistent views in both a 2D maze navigation and a complex 3D environment. These results establish that bringing state-space representations into diffusion models is highly effective in demonstrating both visual details and long-term memory.
Exploration-Driven Generative Interactive Environments
Apr 03, 2025Modern world models require costly and time-consuming collection of large video datasets with action demonstrations by people or by environment-specific agents. To simplify training, we focus on using many virtual environments for inexpensive, automatically collected interaction data. Genie, a recent multi-environment world model, demonstrates simulation abilities of many environments with shared behavior. Unfortunately, training their model requires expensive demonstrations. Therefore, we propose a training framework merely using a random agent in virtual environments. While the model trained in this manner exhibits good controls, it is limited by the random exploration possibilities. To address this limitation, we propose AutoExplore Agent - an exploration agent that entirely relies on the uncertainty of the world model, delivering diverse data from which it can learn the best. Our agent is fully independent of environment-specific rewards and thus adapts easily to new environments. With this approach, the pretrained multi-environment model can quickly adapt to new environments achieving video fidelity and controllability improvement. In order to obtain automatically large-scale interaction datasets for pretraining, we group environments with similar behavior and controls. To this end, we annotate the behavior and controls of 974 virtual environments - a dataset that we name RetroAct. For building our model, we first create an open implementation of Genie - GenieRedux and apply enhancements and adaptations in our version GenieRedux-G. Our code and data are available at https://github.com/insait-institute/GenieRedux.
Learning Generative Interactive Environments By Trained Agent Exploration
Sep 10, 2024



World models are increasingly pivotal in interpreting and simulating the rules and actions of complex environments. Genie, a recent model, excels at learning from visually diverse environments but relies on costly human-collected data. We observe that their alternative method of using random agents is too limited to explore the environment. We propose to improve the model by employing reinforcement learning based agents for data generation. This approach produces diverse datasets that enhance the model's ability to adapt and perform well across various scenarios and realistic actions within the environment. In this paper, we first release the model GenieRedux - an implementation based on Genie. Additionally, we introduce GenieRedux-G, a variant that uses the agent's readily available actions to factor out action prediction uncertainty during validation. Our evaluation, including a replication of the Coinrun case study, shows that GenieRedux-G achieves superior visual fidelity and controllability using the trained agent exploration. The proposed approach is reproducable, scalable and adaptable to new types of environments. Our codebase is available at https://github.com/insait-institute/GenieRedux .
G-MEMP: Gaze-Enhanced Multimodal Ego-Motion Prediction in Driving
Dec 13, 2023Understanding the decision-making process of drivers is one of the keys to ensuring road safety. While the driver intent and the resulting ego-motion trajectory are valuable in developing driver-assistance systems, existing methods mostly focus on the motions of other vehicles. In contrast, we focus on inferring the ego trajectory of a driver's vehicle using their gaze data. For this purpose, we first collect a new dataset, GEM, which contains high-fidelity ego-motion videos paired with drivers' eye-tracking data and GPS coordinates. Next, we develop G-MEMP, a novel multimodal ego-trajectory prediction network that combines GPS and video input with gaze data. We also propose a new metric called Path Complexity Index (PCI) to measure the trajectory complexity. We perform extensive evaluations of the proposed method on both GEM and DR(eye)VE, an existing benchmark dataset. The results show that G-MEMP significantly outperforms state-of-the-art methods in both benchmarks. Furthermore, ablation studies demonstrate over 20% improvement in average displacement using gaze data, particularly in challenging driving scenarios with a high PCI. The data, code, and models can be found at https://eth-ait.github.io/g-memp/.
Spatio-temporal Features for Generalized Detection of Deepfake Videos
Oct 22, 2020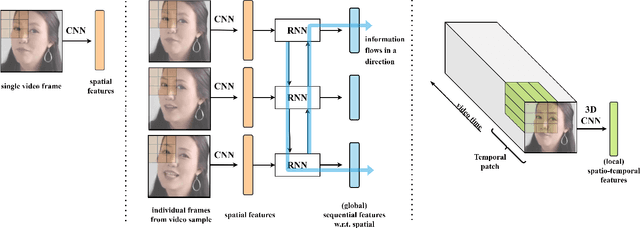

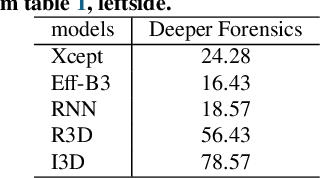
For deepfake detection, video-level detectors have not been explored as extensively as image-level detectors, which do not exploit temporal data. In this paper, we empirically show that existing approaches on image and sequence classifiers generalize poorly to new manipulation techniques. To this end, we propose spatio-temporal features, modeled by 3D CNNs, to extend the generalization capabilities to detect new sorts of deepfake videos. We show that spatial features learn distinct deepfake-method-specific attributes, while spatio-temporal features capture shared attributes between deepfake methods. We provide an in-depth analysis of how the sequential and spatio-temporal video encoders are utilizing temporal information using DFDC dataset arXiv:2006.07397. Thus, we unravel that our approach captures local spatio-temporal relations and inconsistencies in the deepfake videos while existing sequence encoders are indifferent to it. Through large scale experiments conducted on the FaceForensics++ arXiv:1901.08971 and Deeper Forensics arXiv:2001.03024 datasets, we show that our approach outperforms existing methods in terms of generalization capabilities.