 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaarNet: Large-scale Linear-Morphological Hybrid Network for RGB-D Semantic Segmentation
Oct 11, 2023Signals from different modalities each have their own combination algebra which affects their sampling processing. RGB is mostly linear; depth is a geometric signal following the operations of mathematical morphology. If a network obtaining RGB-D input has both kinds of operators available in its layers, it should be able to give effective output with fewer parameters. In this paper, morphological elements in conjunction with more familiar linear modules are used to construct a mixed linear-morphological network called HaarNet. This is the first large-scale linear-morphological hybrid, evaluated on a set of sizeable real-world datasets. In the network, morphological Haar sampling is applied to both feature channels in several layers, which splits extreme values and high-frequency information such that both can be processed to improve both modalities. Moreover, morphologically parameterised ReLU is used, and morphologically-sound up-sampling is applied to obtain a full-resolution output. Experiments show that HaarNet is competitive with a state-of-the-art CNN, implying that morphological networks are a promising research direction for geometry-based learning tasks.
MorphPool: Efficient Non-linear Pooling & Unpooling in CNNs
Nov 25, 2022Pooling is essentially an operation from the field of Mathematical Morphology, with max pooling as a limited special case. The more general setting of MorphPooling greatly extends the tool set for building neural networks. In addition to pooling operations, encoder-decoder networks used for pixel-level predictions also require unpooling. It is common to combine unpooling with convolution or deconvolution for up-sampling. However, using its morphological properties, unpooling can be generalised and improved. Extensive experimentation on two tasks and three large-scale datasets shows that morphological pooling and unpooling lead to improved predictive performance at much reduced parameter counts.
Multi-Loss Weighting with Coefficient of Variations
Sep 03, 2020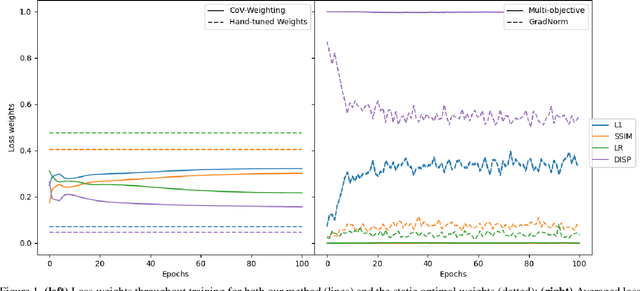

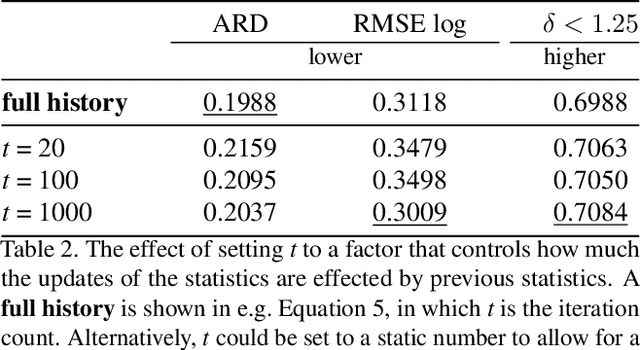
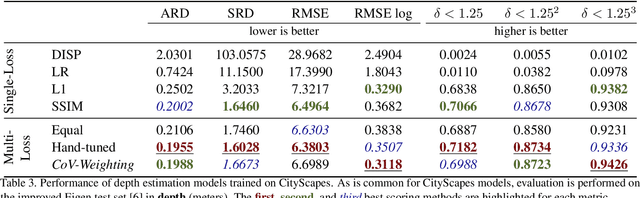
Many interesting tasks in machine learning and computer vision are learned by optimising an objective function defined as a weighted linear combination of multiple losses. The final performance is sensitive to choosing the correct (relative) weights for these losses. Finding a good set of weights is often done by adopting them into the set of hyper-parameters, which are set using an extensive grid search. This is computationally expensive. In this paper, the weights are defined based on properties observed while training the model, including the specific batch loss, the average loss, and the variance for each of the losses. An additional advantage is that the defined weights evolve during training, instead of using static loss weights. In literature, loss weighting is mostly used in a multi-task learning setting, where the different tasks obtain different weights. However, there is a plethora of single-task multi-loss problems that can benefit from automatic loss weighting. In this paper, it is shown that these multi-task approaches do not work on single tasks. Instead, a method is proposed that automatically and dynamically tunes loss weights throughout training specifically for single-task multi-loss problems. The method incorporates a measure of uncertainty to balance the losses. The validity of the approach is shown empirically for different tasks on multiple datasets.
On the Benefit of Adversarial Training for Monocular Depth Estimation
Oct 29, 2019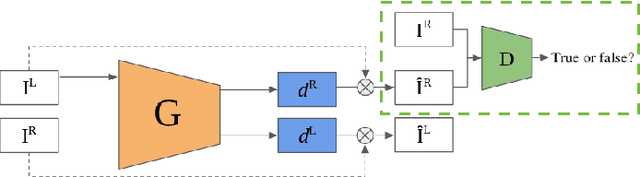
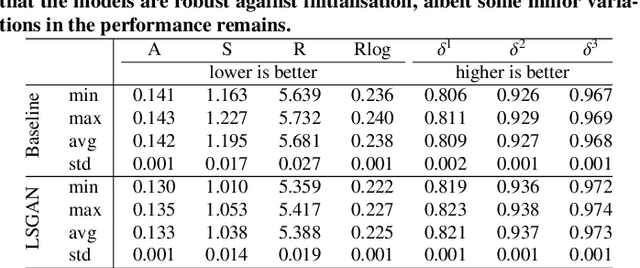
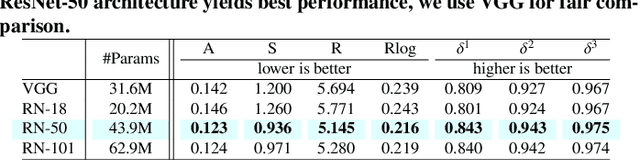
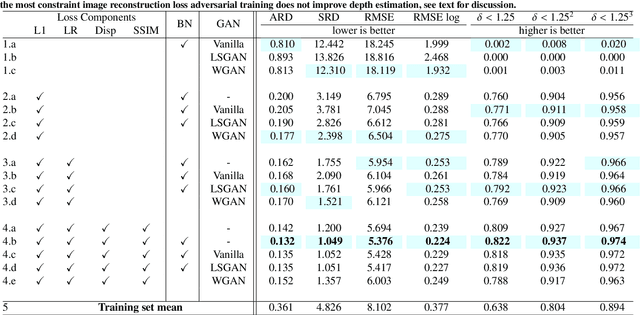
In this paper we address the benefit of adding adversarial training to the task of monocular depth estimation. A model can be trained in a self-supervised setting on stereo pairs of images, where depth (disparities) are an intermediate result in a right-to-left image reconstruction pipeline. For the quality of the image reconstruction and disparity prediction, a combination of different losses is used, including L1 image reconstruction losses and left-right disparity smoothness. These are local pixel-wise losses, while depth prediction requires global consistency. Therefore, we extend the self-supervised network to become a Generative Adversarial Network (GAN), by including a discriminator which should tell apart reconstructed (fake) images from real images. We evaluate Vanilla GANs, LSGANs and Wasserstein GANs in combination with different pixel-wise reconstruction losses. Based on extensive experimental evaluation, we conclude that adversarial training is beneficial if and only if the reconstruction loss is not too constrained. Even though adversarial training seems promising because it promotes global consistency, non-adversarial training outperforms (or is on par with) any method trained with a GAN when a constrained reconstruction loss is used in combination with batch normalisation. Based on the insights of our experimental evaluation we obtain state-of-the art monocular depth estimation results by using batch normalisation and different output scales.