 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-temporal Features for Generalized Detection of Deepfake Videos
Oct 22, 2020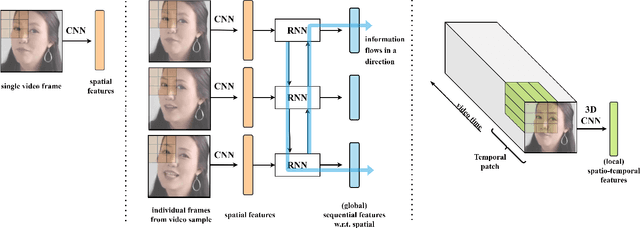

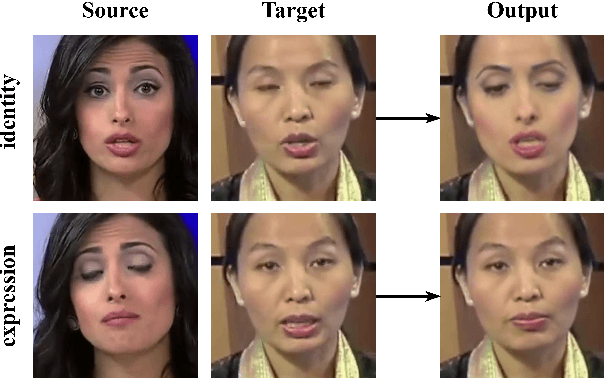
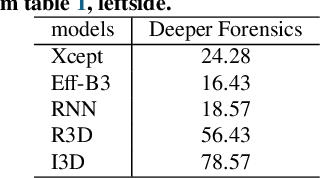
For deepfake detection, video-level detectors have not been explored as extensively as image-level detectors, which do not exploit temporal data. In this paper, we empirically show that existing approaches on image and sequence classifiers generalize poorly to new manipulation techniques. To this end, we propose spatio-temporal features, modeled by 3D CNNs, to extend the generalization capabilities to detect new sorts of deepfake videos. We show that spatial features learn distinct deepfake-method-specific attributes, while spatio-temporal features capture shared attributes between deepfake methods. We provide an in-depth analysis of how the sequential and spatio-temporal video encoders are utilizing temporal information using DFDC dataset arXiv:2006.07397. Thus, we unravel that our approach captures local spatio-temporal relations and inconsistencies in the deepfake videos while existing sequence encoders are indifferent to it. Through large scale experiments conducted on the FaceForensics++ arXiv:1901.08971 and Deeper Forensics arXiv:2001.03024 datasets, we show that our approach outperforms existing methods in terms of generalization capabilities.
Sparse-then-Dense Alignment based 3D Map Reconstruction Method for Endoscopic Capsule Robots
Aug 29, 2017

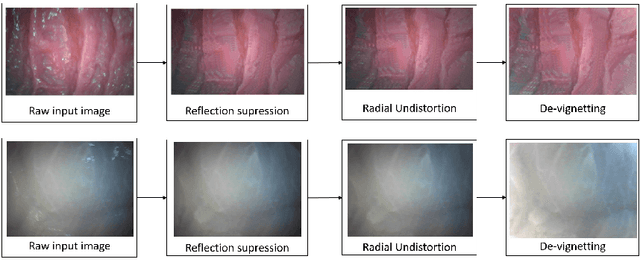

Since the development of capsule endoscopcy technology, substantial progress were made in converting passive capsule endoscopes to robotic active capsule endoscopes which can be controlled by the doctor. However, robotic capsule endoscopy still has some challenges. In particular, the use of such devices to generate a precise and globally consistent three-dimensional (3D) map of the entire inner organ remains an unsolved problem. Such global 3D maps of inner organs would help doctors to detect the location and size of diseased areas more accurately, precisely, and intuitively, thus permitting more accurate and intuitive diagnoses. The proposed 3D reconstruction system is built in a modular fashion including preprocessing, frame stitching, and shading-based 3D reconstruction modules. We propose an efficient scheme to automatically select the key frames out of the huge quantity of raw endoscopic images. Together with a bundle fusion approach that aligns all the selected key frames jointly in a globally consistent way, a significant improvement of the mosaic and 3D map accuracy was reached. To the best of our knowledge, this framework is the first complete pipeline for an endoscopic capsule robot based 3D map reconstruction containing all of the necessary steps for a reliable and accurate endoscopic 3D map. For the qualitative evaluations, a real pig stomach is employed. Moreover, for the first time in literature, a detailed and comprehensive quantitative analysis of each proposed pipeline modules is performed using a non-rigid esophagus gastro duodenoscopy simulator, four different endoscopic cameras, a magnetically activated soft capsule robot (MASCE), a sub-millimeter precise optical motion tracker and a fine-scale 3D optical scanner.