 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICPR 2026 Competition on Low-Resolution License Plate Recognition
Apr 24, 2026Low-Resolution License Plate Recognition (LRLPR) remains a challenging problem in real-world surveillance scenarios, where long capture distances, compression artifacts, and adverse imaging conditions can severely degrade license plate legibility. To promote progress in this area, we organized the ICPR 2026 Competition on Low-Resolution License Plate Recognition, the first competition specifically dedicated to LRLPR using real low-quality data collected under operationally relevant conditions. The competition was based on the LRLPR-26 dataset, which comprises 20,000 training tracks and 3,000 test tracks; each training track contains five low-resolution and five high-resolution images of the same license plate. Notably, a total of 269 teams from 41 countries registered for the competition, and 99 teams submitted valid entries in the Blind Test Phase. The winning team achieved a Recognition Rate of 82.13%, and four teams surpassed the 80% mark, highlighting both the high level of competition at the top of the leaderboard and the continued difficulty of the task. In addition to presenting the competition design, evaluation protocol, and main results, this paper summarizes the methods adopted by the top-5 teams and discusses current trends and promising directions for future research on LRLPR. The competition webpage is available at https://icpr26lrlpr.github.io/
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
Mapper-GIN: Lightweight Structural Graph Abstraction for Corrupted 3D Point Cloud Classification
Feb 05, 2026Robust 3D point cloud classification is often pursued by scaling up backbones or relying on specialized data augmentation. We instead ask whether structural abstraction alone can improve robustness, and study a simple topology-inspired decomposition based on the Mapper algorithm. We propose Mapper-GIN, a lightweight pipeline that partitions a point cloud into overlapping regions using Mapper (PCA lens, cubical cover, and followed by density-based clustering), constructs a region graph from their overlaps, and performs graph classification with a Graph Isomorphism Network. On the corruption benchmark ModelNet40-C, Mapper-GIN achieves competitive and stable accuracy under Noise and Transformation corruptions with only 0.5M parameters. In contrast to prior approaches that require heavier architectures or additional mechanisms to gain robustness, Mapper-GIN attains strong corruption robustness through simple region-level graph abstraction and GIN message passing. Overall, our results suggest that region-graph structure offers an efficient and interpretable source of robustness for 3D visual recognition.
BEAT2AASIST model with layer fusion for ESDD 2026 Challenge
Dec 17, 2025Recent advances in audio generation have increased the risk of realistic environmental sound manipulation, motivating the ESDD 2026 Challenge as the first large-scale benchmark for Environmental Sound Deepfake Detection (ESDD). We propose BEAT2AASIST which extends BEATs-AASIST by splitting BEATs-derived representations along frequency or channel dimension and processing them with dual AASIST branches. To enrich feature representations, we incorporate top-k transformer layer fusion using concatenation, CNN-gated, and SE-gated strategies. In addition, vocoder-based data augmentation is applied to improve robustness against unseen spoofing methods. Experimental results on the official test sets demonstrate that the proposed approach achieves competitive performance across the challenge tracks.
Table2Image: Interpretable Tabular data Classification with Realistic Image Transformations
Dec 09, 2024



Recent advancements in deep learning for tabular data have demonstrated promising performance, yet interpretable models remain limited, with many relying on complex and large-scale architectures. This paper introduces Table2Image, an interpretable framework that transforms tabular data into realistic image representations for classification, achieving competitive performance with relatively lightweight models. Additionally, we propose variance inflation factor (VIF) initialization, which reflects the statistical properties of the data, and a novel interpretability framework that integrates insights from both the original tabular data and its image transformations. By leveraging Shapley additive explanations (SHAP) with methods to minimize distributional discrepancies, our approach combines tabular and image-based representations. Experiments on benchmark datasets showcase competitive classification accuracy, area under the curve (AUC), and improved interpretability, offering a scalable and reliable solution. Our code is available at https://github.com/duneag2/table2image.
Experimental Study: Enhancing Voice Spoofing Detection Models with wav2vec 2.0
Feb 27, 2024



Conventional spoofing detection systems have heavily relied on the use of handcrafted features derived from speech data. However, a notable shift has recently emerged towards the direct utilization of raw speech waveforms, as demonstrated by methods like SincNet filters. This shift underscores the demand for more sophisticated audio sample features. Moreover, the success of deep learning models, particularly those utilizing large pretrained wav2vec 2.0 as a featurization front-end, highlights the importance of refined feature encoders. In response, this research assessed the representational capability of wav2vec 2.0 as an audio feature extractor, modifying the size of its pretrained Transformer layers through two key adjustments: (1) selecting a subset of layers starting from the leftmost one and (2) fine-tuning a portion of the selected layers from the rightmost one. We complemented this analysis with five spoofing detection back-end models, with a primary focus on AASIST, enabling us to pinpoint the optimal configuration for the selection and fine-tuning process. In contrast to conventional handcrafted features, our investigation identified several spoofing detection systems that achieve state-of-the-art performance in the ASVspoof 2019 LA dataset. This comprehensive exploration offers valuable insights into feature selection strategies, advancing the field of spoofing detection.
CAU_KU team's submission to ADD 2022 Challenge task 1: Low-quality fake audio detection through frequency feature masking
Feb 09, 2022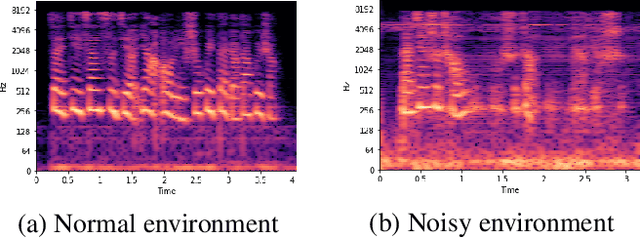
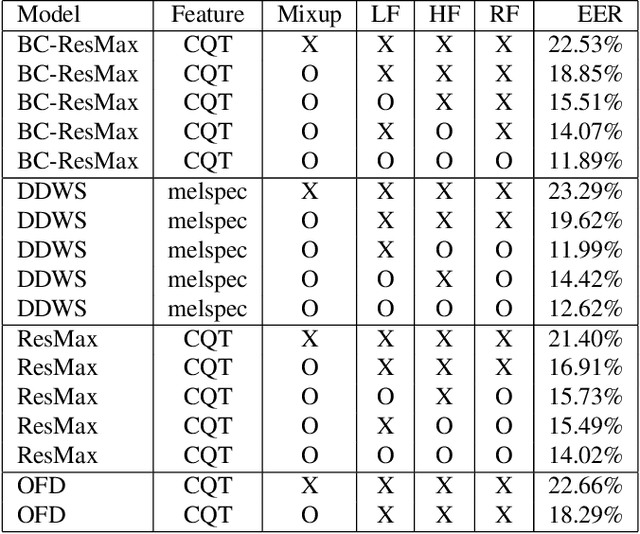
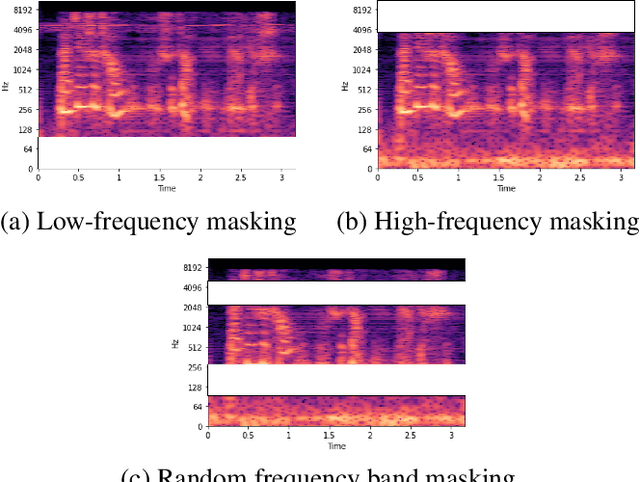
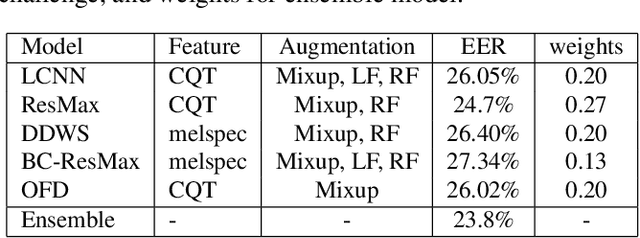
This technical report describes Chung-Ang University and Korea University (CAU_KU) team's model participating in the Audio Deep Synthesis Detection (ADD) 2022 Challenge, track 1: Low-quality fake audio detection. For track 1, we propose a frequency feature masking (FFM) augmentation technique to deal with a low-quality audio environment. %detection that spectrogram-based models can be applied. We applied FFM and mixup augmentation on five spectrogram-based deep neural network architectures that performed well for spoofing detection using mel-spectrogram and constant Q transform (CQT) features. Our best submission achieved 23.8% of EER ranked 3rd on track 1.