 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning low-dimensional dynamics from whole-brain data improves task capture
May 18, 2023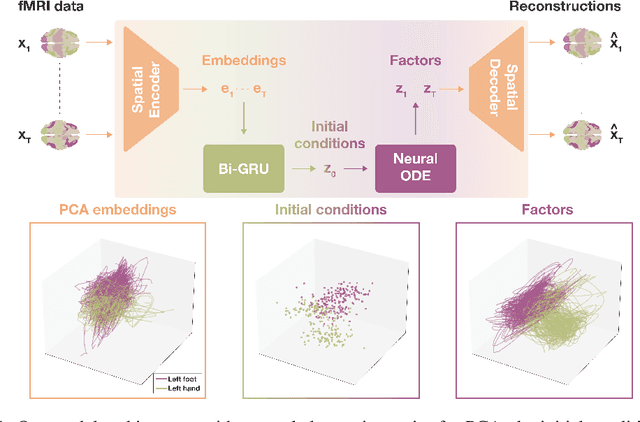
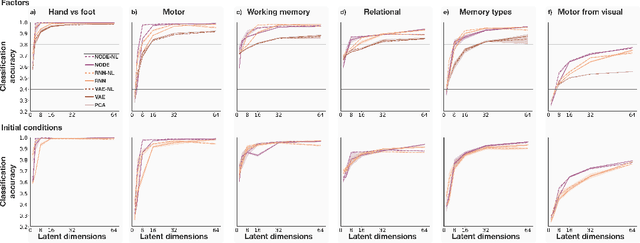
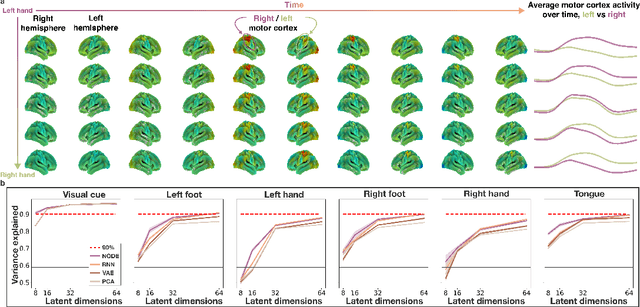
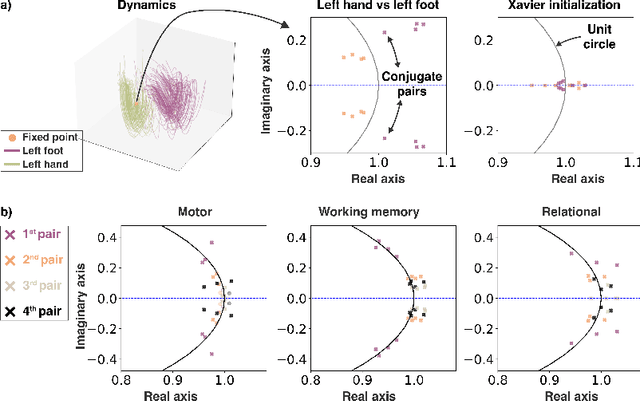
The neural dynamics underlying brain activity are critical to understanding cognitive processes and mental disorders. However, current voxel-based whole-brain dimensionality reduction techniques fall short of capturing these dynamics, producing latent timeseries that inadequately relate to behavioral tasks. To address this issue, we introduce a novel approach to learning low-dimensional approximations of neural dynamics by using a sequential variational autoencoder (SVAE) that represents the latent dynamical system via a neural ordinary differential equation (NODE). Importantly, our method finds smooth dynamics that can predict cognitive processes with accuracy higher than classical methods. Our method also shows improved spatial localization to task-relevant brain regions and identifies well-known structures such as the motor homunculus from fMRI motor task recordings. We also find that non-linear projections to the latent space enhance performance for specific tasks, offering a promising direction for future research. We evaluate our approach on various task-fMRI datasets, including motor, working memory, and relational processing tasks, and demonstrate that it outperforms widely used dimensionality reduction techniques in how well the latent timeseries relates to behavioral sub-tasks, such as left-hand or right-hand tapping. Additionally, we replace the NODE with a recurrent neural network (RNN) and compare the two approaches to understand the importance of explicitly learning a dynamical system. Lastly, we analyze the robustness of the learned dynamical systems themselves and find that their fixed points are robust across seeds, highlighting our method's potential for the analysis of cognitive processes as dynamical systems.
SalientGrads: Sparse Models for Communication Efficient and Data Aware Distributed Federated Training
Apr 15, 2023Federated learning (FL) enables the training of a model leveraging decentralized data in client sites while preserving privacy by not collecting data. However, one of the significant challenges of FL is limited computation and low communication bandwidth in resource limited edge client nodes. To address this, several solutions have been proposed in recent times including transmitting sparse models and learning dynamic masks iteratively, among others. However, many of these methods rely on transmitting the model weights throughout the entire training process as they are based on ad-hoc or random pruning criteria. In this work, we propose Salient Grads, which simplifies the process of sparse training by choosing a data aware subnetwork before training, based on the model-parameter's saliency scores, which is calculated from the local client data. Moreover only highly sparse gradients are transmitted between the server and client models during the training process unlike most methods that rely on sharing the entire dense model in each round. We also demonstrate the efficacy of our method in a real world federated learning application and report improvement in wall-clock communication time.
Self-Supervised Mental Disorder Classifiers via Time Reversal
Nov 30, 2022Data scarcity is a notable problem, especially in the medical domain, due to patient data laws. Therefore, efficient Pre-Training techniques could help in combating this problem. In this paper, we demonstrate that a model trained on the time direction of functional neuro-imaging data could help in any downstream task, for example, classifying diseases from healthy controls in fMRI data. We train a Deep Neural Network on Independent components derived from fMRI data using the Independent component analysis (ICA) technique. It learns time direction in the ICA-based data. This pre-trained model is further trained to classify brain disorders in different datasets. Through various experiments, we have shown that learning time direction helps a model learn some causal relation in fMRI data that helps in faster convergence, and consequently, the model generalizes well in downstream classification tasks even with fewer data records.
Pipeline-Invariant Representation Learning for Neuroimaging
Aug 27, 2022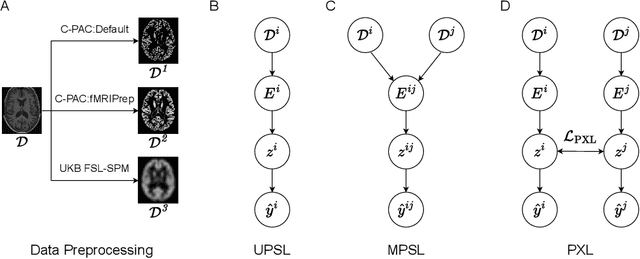

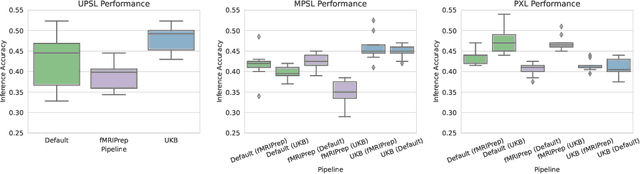
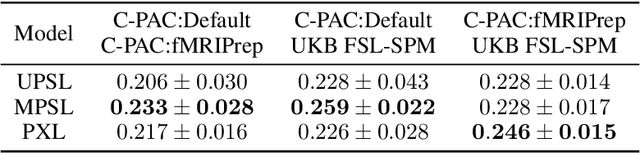
Deep learning has been widely applied in neuroimaging, including to predicting brain-phenotype relationships from magnetic resonance imaging (MRI) volumes. MRI data usually requires extensive preprocessing before it is ready for modeling, even via deep learning, in part due to its high dimensionality and heterogeneity. A growing array of MRI preprocessing pipelines have been developed each with its own strengths and limitations. Recent studies have shown that pipeline-related variation may lead to different scientific findings, even when using the identical data. Meanwhile, the machine learning community has emphasized the importance of shifting from model-centric to data-centric approaches given that data quality plays an essential role in deep learning applications. Motivated by this idea, we first evaluate how preprocessing pipeline selection can impact the downstream performance of a supervised learning model. We next propose two pipeline-invariant representation learning methodologies, MPSL and PXL, to improve consistency in classification performance and to capture similar neural network representations between pipeline pairs. Using 2000 human subjects from the UK Biobank dataset, we demonstrate that both models present unique advantages, in particular that MPSL can be used to improve out-of-sample generalization to new pipelines, while PXL can be used to improve predictive performance consistency and representational similarity within a closed pipeline set. These results suggest that our proposed models can be applied to overcome pipeline-related biases and to improve reproducibility in neuroimaging prediction tasks.
Geometrically Guided Integrated Gradients
Jun 16, 2022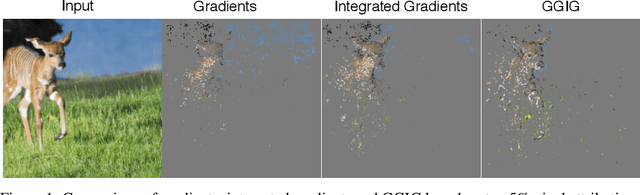
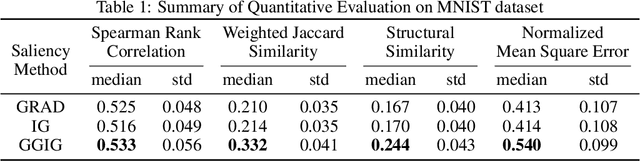
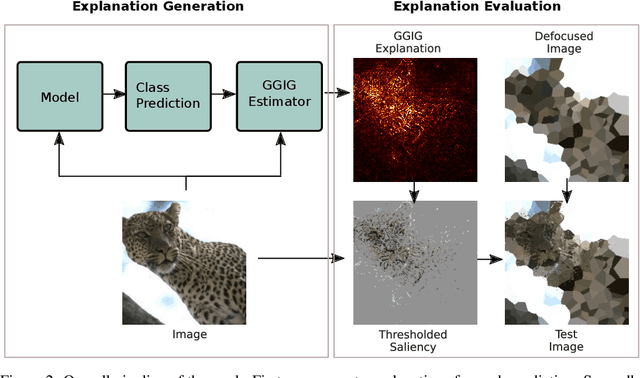
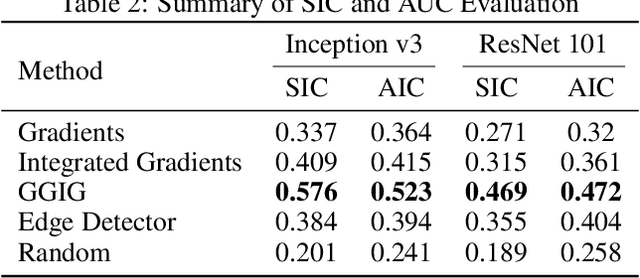
Interpretability methods for deep neural networks mainly focus on the sensitivity of the class score with respect to the original or perturbed input, usually measured using actual or modified gradients. Some methods also use a model-agnostic approach to understanding the rationale behind every prediction. In this paper, we argue and demonstrate that local geometry of the model parameter space relative to the input can also be beneficial for improved post-hoc explanations. To achieve this goal, we introduce an interpretability method called "geometrically-guided integrated gradients" that builds on top of the gradient calculation along a linear path as traditionally used in integrated gradient methods. However, instead of integrating gradient information, our method explores the model's dynamic behavior from multiple scaled versions of the input and captures the best possible attribution for each input. We demonstrate through extensive experiments that the proposed approach outperforms vanilla and integrated gradients in subjective and quantitative assessment. We also propose a "model perturbation" sanity check to complement the traditionally used "model randomization" test.
Constraint-Based Causal Structure Learning from Undersampled Graphs
May 18, 2022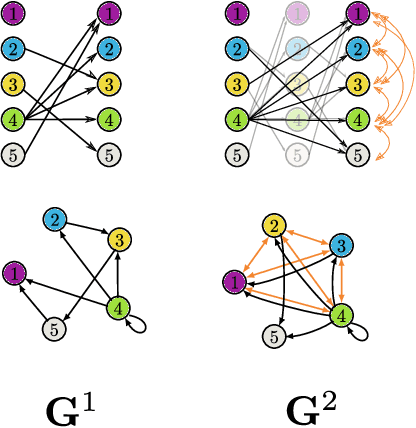
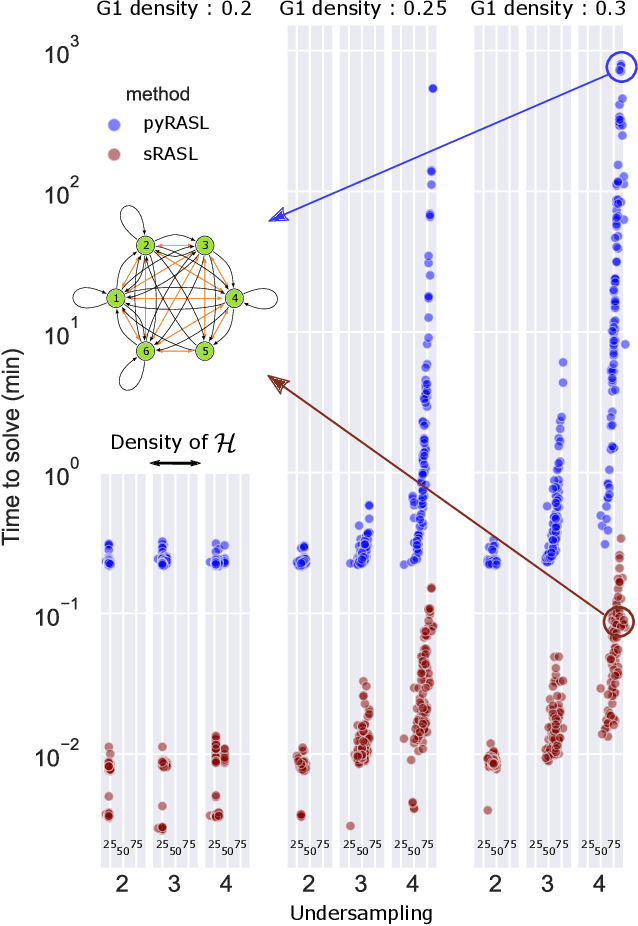
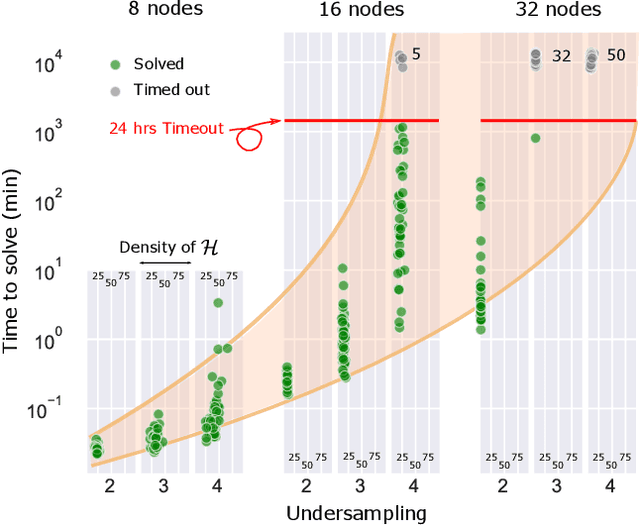
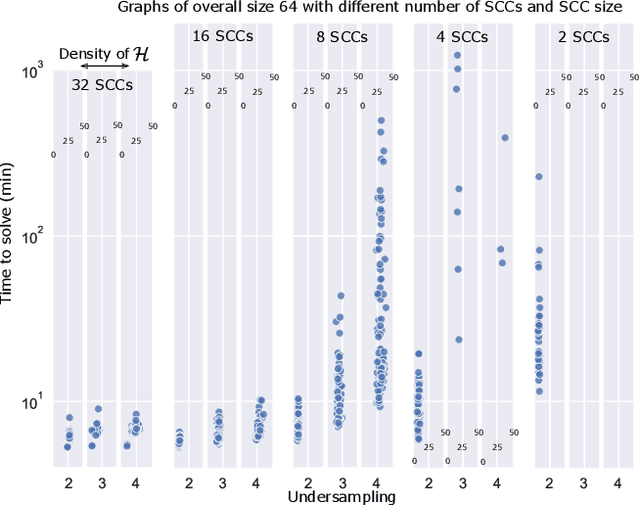
Graphical structures estimated by causal learning algorithms from time series data can provide highly misleading causal information if the causal timescale of the generating process fails to match the measurement timescale of the data. Although this problem has been recently recognized, practitioners have limited resources to respond to it, and so must continue using models that they know are likely misleading. Existing methods either (a) require that the difference between causal and measurement timescales is known; or (b) can handle only very small number of random variables when the timescale difference is unknown; or (c) apply to only pairs of variables, though with fewer assumptions about prior knowledge; or (d) return impractically too many solutions. This paper addresses all four challenges. We combine constraint programming with both theoretical insights into the problem structure and prior information about admissible causal interactions. The resulting system provides a practical approach that scales to significantly larger sets (>100) of random variables, does not require precise knowledge of the timescale difference, supports edge misidentification and parametric connection strengths, and can provide the optimum choice among many possible solutions. The cumulative impact of these improvements is gain of multiple orders of magnitude in speed and informativeness.
Deep Dynamic Effective Connectivity Estimation from Multivariate Time Series
Feb 16, 2022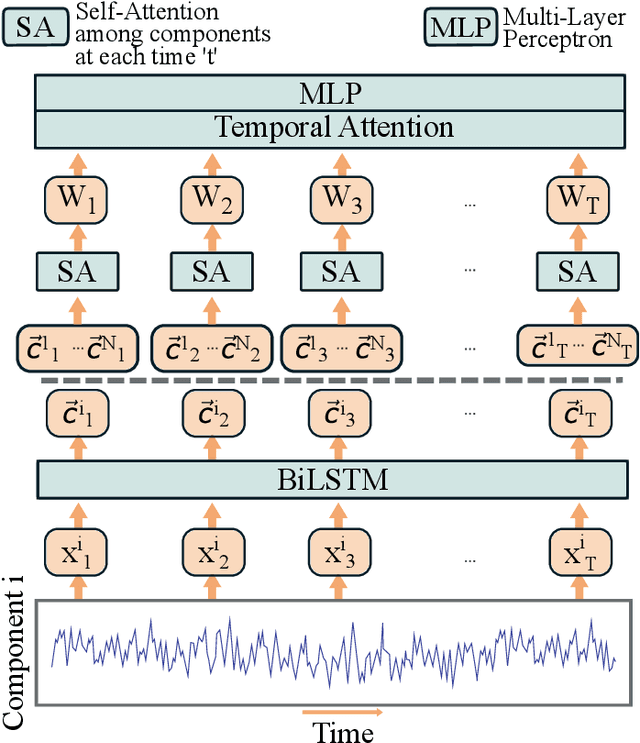
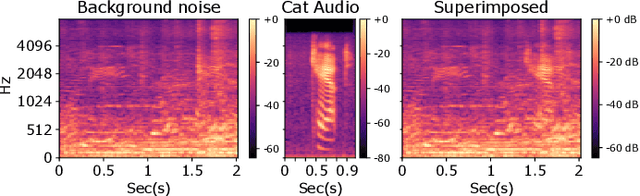
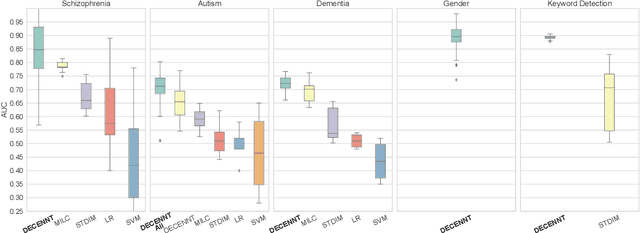
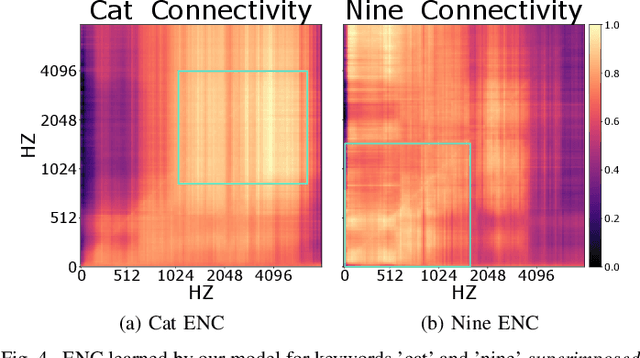
Recently, methods that represent data as a graph, such as graph neural networks (GNNs) have been successfully used to learn data representations and structures to solve classification and link prediction problems. The applications of such methods are vast and diverse, but most of the current work relies on the assumption of a static graph. This assumption does not hold for many highly dynamic systems, where the underlying connectivity structure is non-stationary and is mostly unobserved. Using a static model in these situations may result in sub-optimal performance. In contrast, modeling changes in graph structure with time can provide information about the system whose applications go beyond classification. Most work of this type does not learn effective connectivity and focuses on cross-correlation between nodes to generate undirected graphs. An undirected graph is unable to capture direction of an interaction which is vital in many fields, including neuroscience. To bridge this gap, we developed dynamic effective connectivity estimation via neural network training (DECENNT), a novel model to learn an interpretable directed and dynamic graph induced by the downstream classification/prediction task. DECENNT outperforms state-of-the-art (SOTA) methods on five different tasks and infers interpretable task-specific dynamic graphs. The dynamic graphs inferred from functional neuroimaging data align well with the existing literature and provide additional information. Additionally, the temporal attention module of DECENNT identifies time-intervals crucial for predictive downstream task from multivariate time series data.
Single-Shot Pruning for Offline Reinforcement Learning
Dec 31, 2021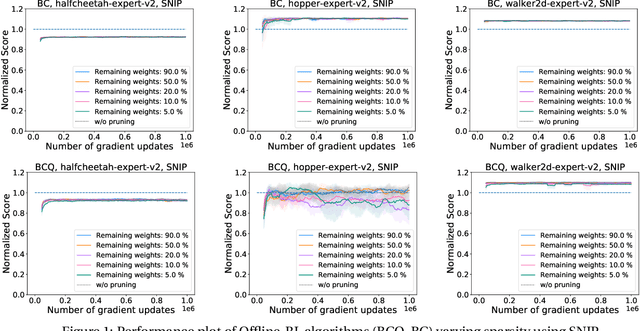
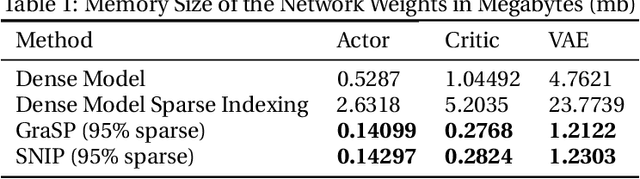
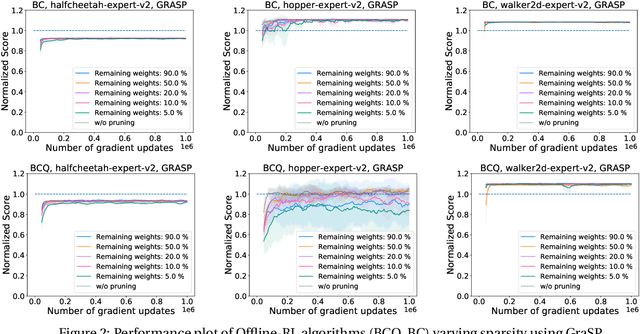
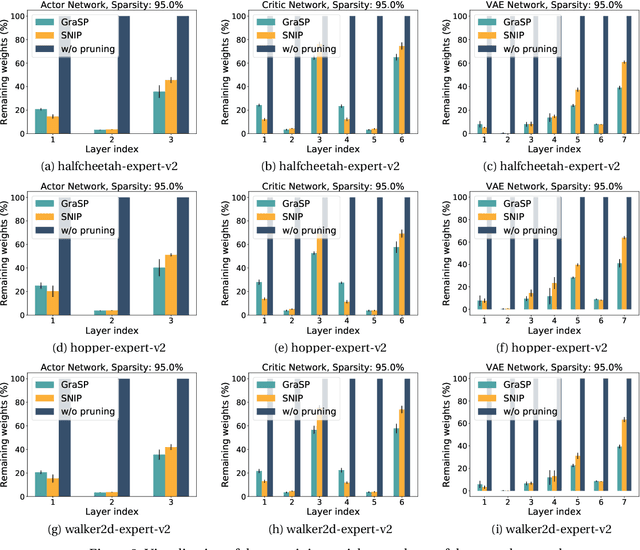
Deep Reinforcement Learning (RL) is a powerful framework for solving complex real-world problems. Large neural networks employed in the framework are traditionally associated with better generalization capabilities, but their increased size entails the drawbacks of extensive training duration, substantial hardware resources, and longer inference times. One way to tackle this problem is to prune neural networks leaving only the necessary parameters. State-of-the-art concurrent pruning techniques for imposing sparsity perform demonstrably well in applications where data distributions are fixed. However, they have not yet been substantially explored in the context of RL. We close the gap between RL and single-shot pruning techniques and present a general pruning approach to the Offline RL. We leverage a fixed dataset to prune neural networks before the start of RL training. We then run experiments varying the network sparsity level and evaluating the validity of pruning at initialization techniques in continuous control tasks. Our results show that with 95% of the network weights pruned, Offline-RL algorithms can still retain performance in the majority of our experiments. To the best of our knowledge, no prior work utilizing pruning in RL retained performance at such high levels of sparsity. Moreover, pruning at initialization techniques can be easily integrated into any existing Offline-RL algorithms without changing the learning objective.
A deep learning model for data-driven discovery of functional connectivity
Dec 07, 2021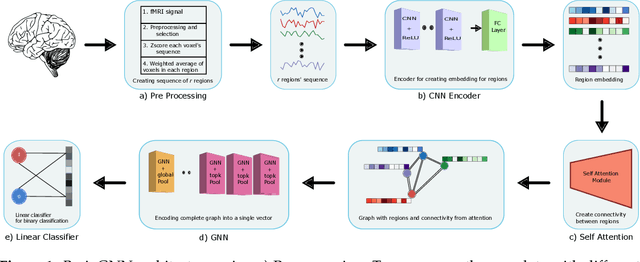
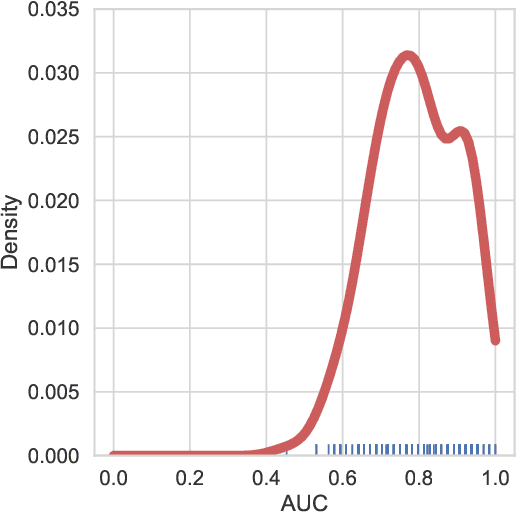
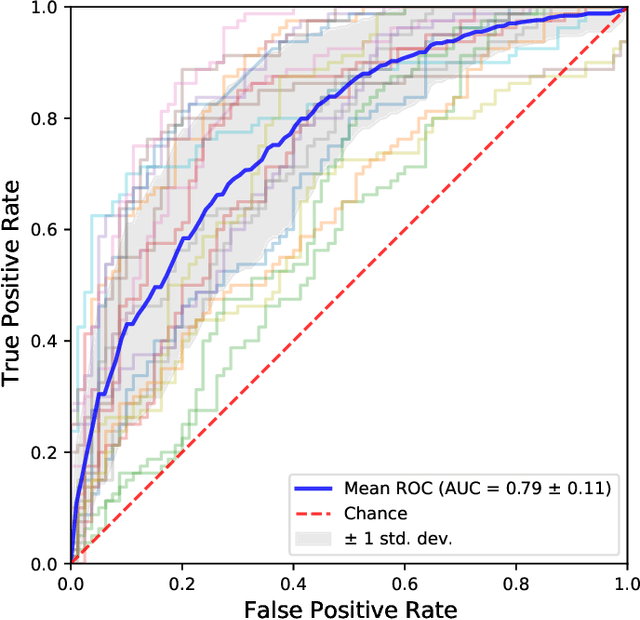
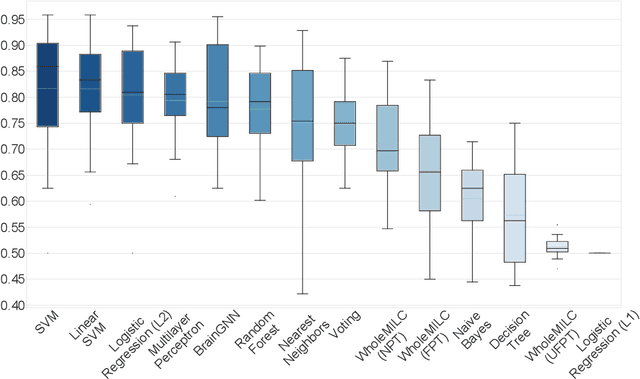
Functional connectivity (FC) studies have demonstrated the overarching value of studying the brain and its disorders through the undirected weighted graph of fMRI correlation matrix. Most of the work with the FC, however, depends on the way the connectivity is computed, and further depends on the manual post-hoc analysis of the FC matrices. In this work we propose a deep learning architecture BrainGNN that learns the connectivity structure as part of learning to classify subjects. It simultaneously applies a graphical neural network to this learned graph and learns to select a sparse subset of brain regions important to the prediction task. We demonstrate the model's state-of-the-art classification performance on a schizophrenia fMRI dataset and demonstrate how introspection leads to disorder relevant findings. The graphs learned by the model exhibit strong class discrimination and the sparse subset of relevant regions are consistent with the schizophrenia literature.
* Accepted at Algorithms 2021, 14(3), 75
Multi network InfoMax: A pre-training method involving graph convolutional networks
Nov 01, 2021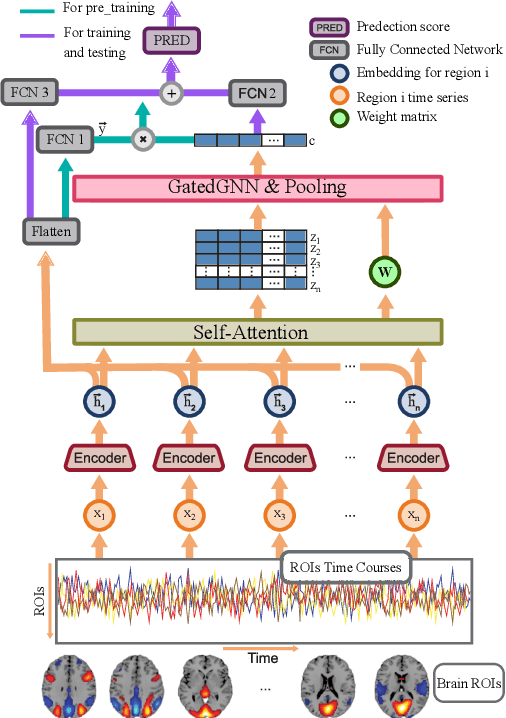
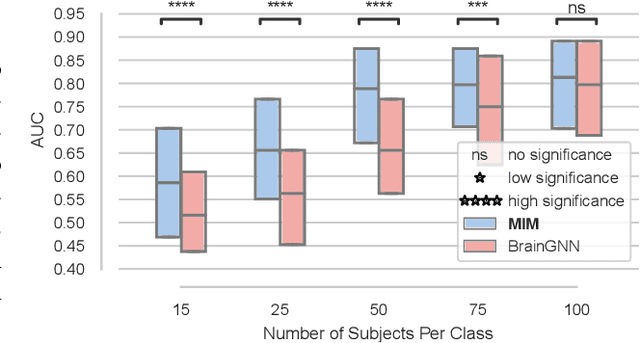
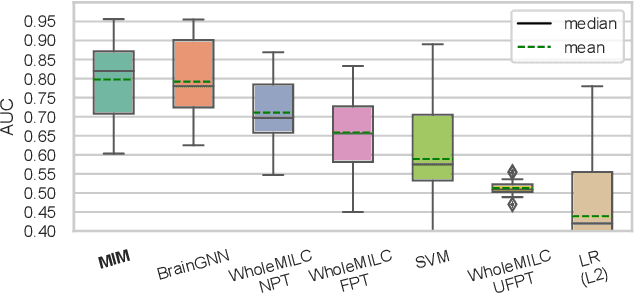
Discovering distinct features and their relations from data can help us uncover valuable knowledge crucial for various tasks, e.g., classification. In neuroimaging, these features could help to understand, classify, and possibly prevent brain disorders. Model introspection of highly performant overparameterized deep learning (DL) models could help find these features and relations. However, to achieve high-performance level DL models require numerous labeled training samples ($n$) rarely available in many fields. This paper presents a pre-training method involving graph convolutional/neural networks (GCNs/GNNs), based on maximizing mutual information between two high-level embeddings of an input sample. Many of the recently proposed pre-training methods pre-train one of many possible networks of an architecture. Since almost every DL model is an ensemble of multiple networks, we take our high-level embeddings from two different networks of a model --a convolutional and a graph network--. The learned high-level graph latent representations help increase performance for downstream graph classification tasks and bypass the need for a high number of labeled data samples. We apply our method to a neuroimaging dataset for classifying subjects into healthy control (HC) and schizophrenia (SZ) groups. Our experiments show that the pre-trained model significantly outperforms the non-pre-trained model and requires $50\%$ less data for similar performance.