 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiTab: A Comprehensive Benchmark Suite for Multi-Dimensional Evaluation in Tabular Domains
May 20, 2025Despite the widespread use of tabular data in real-world applications, most benchmarks rely on average-case metrics, which fail to reveal how model behavior varies across diverse data regimes. To address this, we propose MultiTab, a benchmark suite and evaluation framework for multi-dimensional, data-aware analysis of tabular learning algorithms. Rather than comparing models only in aggregate, MultiTab categorizes 196 publicly available datasets along key data characteristics, including sample size, label imbalance, and feature interaction, and evaluates 13 representative models spanning a range of inductive biases. Our analysis shows that model performance is highly sensitive to such regimes: for example, models using sample-level similarity excel on datasets with large sample sizes or high inter-feature correlation, while models encoding inter-feature dependencies perform best with weakly correlated features. These findings reveal that inductive biases do not always behave as intended, and that regime-aware evaluation is essential for understanding and improving model behavior. MultiTab enables more principled model design and offers practical guidance for selecting models tailored to specific data characteristics. All datasets, code, and optimization logs are publicly available at https://huggingface.co/datasets/LGAI-DILab/Multitab.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Gradient Surgery for One-shot Unlearning on Generative Model
Jul 18, 2023

Recent regulation on right-to-be-forgotten emerges tons of interest in unlearning pre-trained machine learning models. While approximating a straightforward yet expensive approach of retrain-from-scratch, recent machine unlearning methods unlearn a sample by updating weights to remove its influence on the weight parameters. In this paper, we introduce a simple yet effective approach to remove a data influence on the deep generative model. Inspired by works in multi-task learning, we propose to manipulate gradients to regularize the interplay of influence among samples by projecting gradients onto the normal plane of the gradients to be retained. Our work is agnostic to statistics of the removal samples, outperforming existing baselines while providing theoretical analysis for the first time in unlearning a generative model.
Neo-GNNs: Neighborhood Overlap-aware Graph Neural Networks for Link Prediction
Jun 09, 2022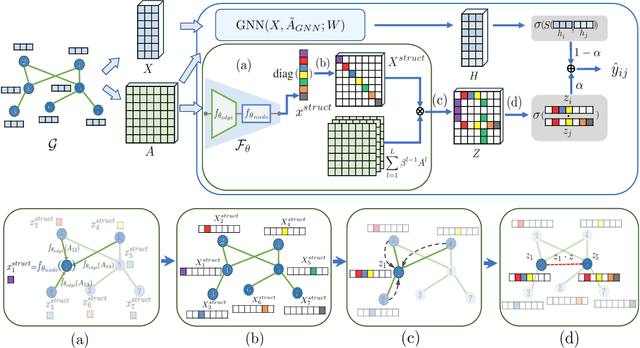
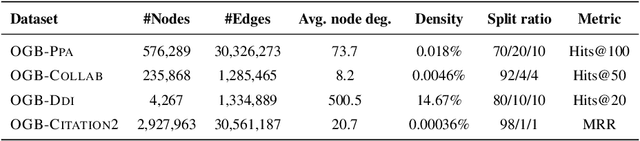
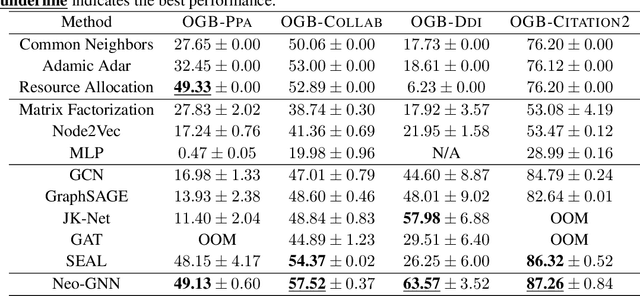
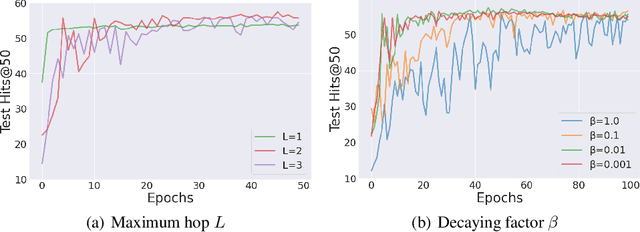
Graph Neural Networks (GNNs) have been widely applied to various fields for learning over graph-structured data. They have shown significant improvements over traditional heuristic methods in various tasks such as node classification and graph classification. However, since GNNs heavily rely on smoothed node features rather than graph structure, they often show poor performance than simple heuristic methods in link prediction where the structural information, e.g., overlapped neighborhoods, degrees, and shortest paths, is crucial. To address this limitation, we propose Neighborhood Overlap-aware Graph Neural Networks (Neo-GNNs) that learn useful structural features from an adjacency matrix and estimate overlapped neighborhoods for link prediction. Our Neo-GNNs generalize neighborhood overlap-based heuristic methods and handle overlapped multi-hop neighborhoods. Our extensive experiments on Open Graph Benchmark datasets (OGB) demonstrate that Neo-GNNs consistently achieve state-of-the-art performance in link prediction. Our code is publicly available at https://github.com/seongjunyun/Neo_GNNs.