 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptVC: High Quality Voice Conversion with Adaptive Learning
Jan 07, 2025



The goal of voice conversion is to transform the speech of a source speaker to sound like that of a reference speaker while preserving the original content. A key challenge is to extract disentangled linguistic content from the source and voice style from the reference. While existing approaches leverage various methods to isolate the two, a generalization still requires further attention, especially for robustness in zero-shot scenarios. In this paper, we achieve successful disentanglement of content and speaker features by tuning self-supervised speech features with adapters. The adapters are trained to dynamically encode nuanced features from rich self-supervised features, and the decoder fuses them to produce speech that accurately resembles the reference with minimal loss of content. Moreover, we leverage a conditional flow matching decoder with cross-attention speaker conditioning to further boost the synthesis quality and efficiency. Subjective and objective evaluations in a zero-shot scenario demonstrate that the proposed method outperforms existing models in speech quality and similarity to the reference speech.
When Vision Models Meet Parameter Efficient Look-Aside Adapters Without Large-Scale Audio Pretraining
Dec 08, 2024



Recent studies show that pretrained vision models can boost performance in audio downstream tasks. To enhance the performance further, an additional pretraining stage with large scale audio data is typically required to infuse audio specific knowledge into the vision model. However, such approaches require extensive audio data and a carefully designed objective function. In this work, we propose bypassing the pretraining stage by directly fine-tuning the vision model with our Look Aside Adapter (LoAA) designed for efficient audio understanding. Audio spectrum data is represented across two heterogeneous dimensions time and frequency and we refine adapters to facilitate interactions between tokens across these dimensions. Our experiments demonstrate that our adapters allow vision models to reach or surpass the performance of pretrained audio models in various audio and speech tasks, offering a resource efficient and effective solution for leveraging vision models in audio applications.
VoxSim: A perceptual voice similarity dataset
Jul 26, 2024



This paper introduces VoxSim, a dataset of perceptual voice similarity ratings. Recent efforts to automate the assessment of speech synthesis technologies have primarily focused on predicting mean opinion score of naturalness, leaving speaker voice similarity relatively unexplored due to a lack of extensive training data. To address this, we generate about 41k utterance pairs from the VoxCeleb dataset, a widely utilised speech dataset for speaker recognition, and collect nearly 70k speaker similarity scores through a listening test. VoxSim offers a valuable resource for the development and benchmarking of speaker similarity prediction models. We provide baseline results of speaker similarity prediction models on the VoxSim test set and further demonstrate that the model trained on our dataset generalises to the out-of-domain VCC2018 dataset.
Latent Filling: Latent Space Data Augmentation for Zero-shot Speech Synthesis
Oct 05, 2023Previous works in zero-shot text-to-speech (ZS-TTS) have attempted to enhance its systems by enlarging the training data through crowd-sourcing or augmenting existing speech data. However, the use of low-quality data has led to a decline in the overall system performance. To avoid such degradation, instead of directly augmenting the input data, we propose a latent filling (LF) method that adopts simple but effective latent space data augmentation in the speaker embedding space of the ZS-TTS system. By incorporating a consistency loss, LF can be seamlessly integrated into existing ZS-TTS systems without the need for additional training stages. Experimental results show that LF significantly improves speaker similarity while preserving speech quality.
An Empirical Study on L2 Accents of Cross-lingual Text-to-Speech Systems via Vowel Space
Nov 06, 2022With the recent developments in cross-lingual Text-to-Speech (TTS) systems, L2 (second-language, or foreign) accent problems arise. Moreover, running a subjective evaluation for such cross-lingual TTS systems is troublesome. The vowel space analysis, which is often utilized to explore various aspects of language including L2 accents, is a great alternative analysis tool. In this study, we apply the vowel space analysis method to explore L2 accents of cross-lingual TTS systems. Through the vowel space analysis, we observe the three followings: a) a parallel architecture (Glow-TTS) is less L2-accented than an auto-regressive one (Tacotron); b) L2 accents are more dominant in non-shared vowels in a language pair; and c) L2 accents of cross-lingual TTS systems share some phenomena with those of human L2 learners. Our findings imply that it is necessary for TTS systems to handle each language pair differently, depending on their linguistic characteristics such as non-shared vowels. They also hint that we can further incorporate linguistics knowledge in developing cross-lingual TTS systems.
Into-TTS : Intonation Template based Prosody Control System
Apr 04, 2022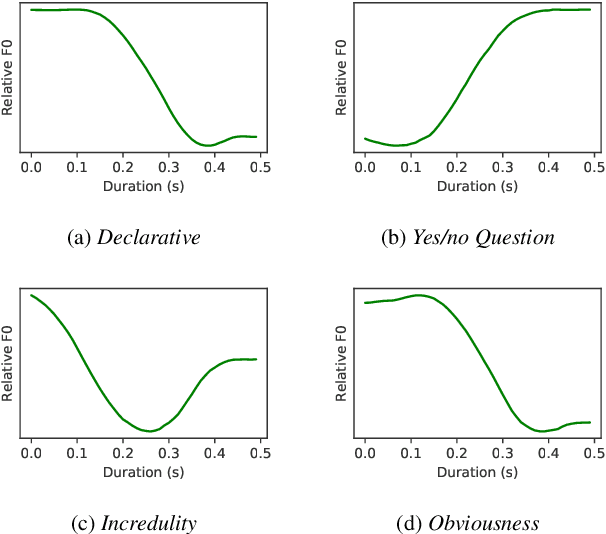

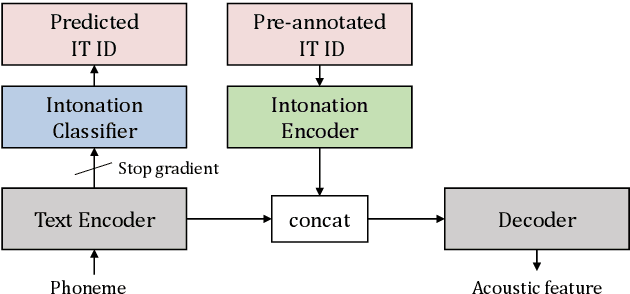
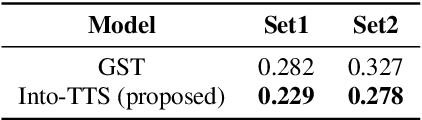
Intonations take an important role in delivering the intention of the speaker. However, current end-to-end TTS systems often fail to model proper intonations. To alleviate this problem, we propose a novel, intuitive method to synthesize speech in different intonations using predefined intonation templates. Prior to the acoustic model training, speech data are automatically grouped into intonation templates by k-means clustering, according to their sentence-final F0 contour. Two proposed modules are added to the end-to-end TTS framework: intonation classifier and intonation encoder. The intonation classifier recommends a suitable intonation template to the given text. The intonation encoder, attached to the text encoder output, synthesizes speech abiding the requested intonation template. Main contributions of our paper are: (a) an easy-to-use intonation control system covering a wide range of users; (b) better performance in wrapping speech in a requested intonation with improved pitch distance and MOS; and (c) feasibility to future integration between TTS and NLP, TTS being able to utilize contextual information. Audio samples are available at https://srtts.github.io/IntoTTS.
Streaming end-to-end speech recognition with jointly trained neural feature enhancement
May 04, 2021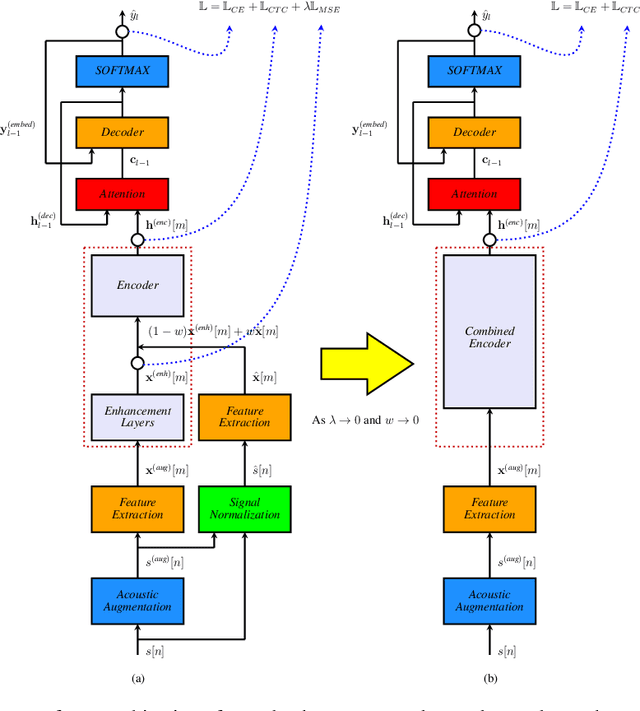
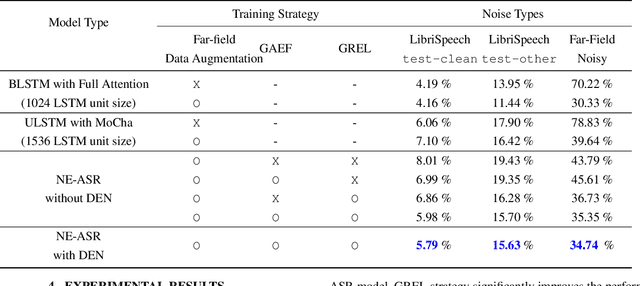
In this paper, we present a streaming end-to-end speech recognition model based on Monotonic Chunkwise Attention (MoCha) jointly trained with enhancement layers. Even though the MoCha attention enables streaming speech recognition with recognition accuracy comparable to a full attention-based approach, training this model is sensitive to various factors such as the difficulty of training examples, hyper-parameters, and so on. Because of these issues, speech recognition accuracy of a MoCha-based model for clean speech drops significantly when a multi-style training approach is applied. Inspired by Curriculum Learning [1], we introduce two training strategies: Gradual Application of Enhanced Features (GAEF) and Gradual Reduction of Enhanced Loss (GREL). With GAEF, the model is initially trained using clean features. Subsequently, the portion of outputs from the enhancement layers gradually increases. With GREL, the portion of the Mean Squared Error (MSE) loss for the enhanced output gradually reduces as training proceeds. In experimental results on the LibriSpeech corpus and noisy far-field test sets, the proposed model with GAEF-GREL training strategies shows significantly better results than the conventional multi-style training approach.
Delving into VoxCeleb: environment invariant speaker recognition
Oct 24, 2019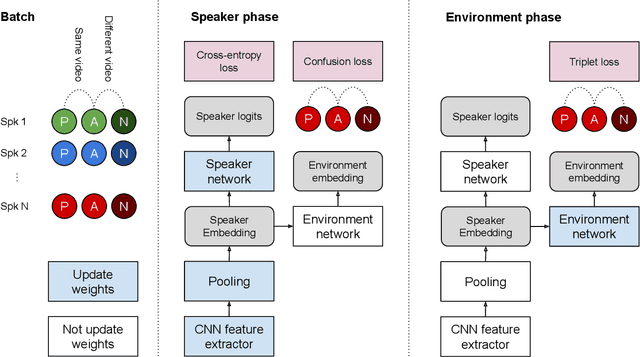
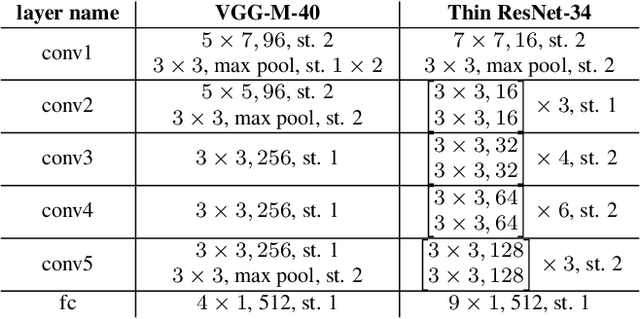
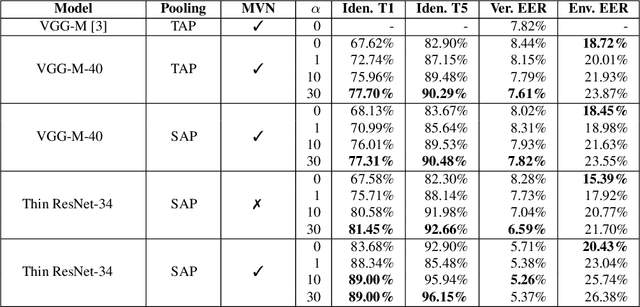
Research in speaker recognition has recently seen significant progress due to the application of neural network models and the availability of new large-scale datasets. There has been a plethora of work in search of more powerful architectures or loss functions suitable for the task, but they do not consider what information is learnt by the models aside from being able to predict the given labels. In this work, we introduce an environment adversarial training framework in which the network can effectively learn speaker-discriminative and environment-invariant embeddings without explicit domain shift during training. This allows the network to generalise better in unseen conditions. The method is evaluated on both speaker identification and verification tasks using the VoxCeleb dataset, on which we demonstrate significant performance improvements over baselines.
KU-ISPL Language Recognition System for NIST 2015 i-Vector Machine Learning Challenge
Sep 21, 2016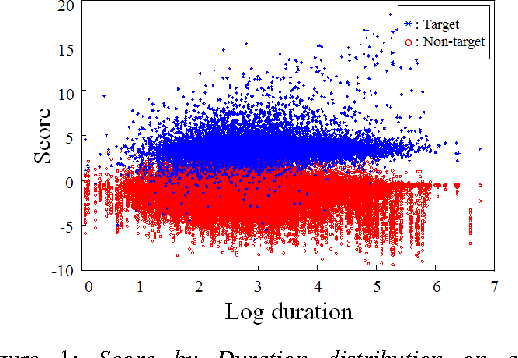

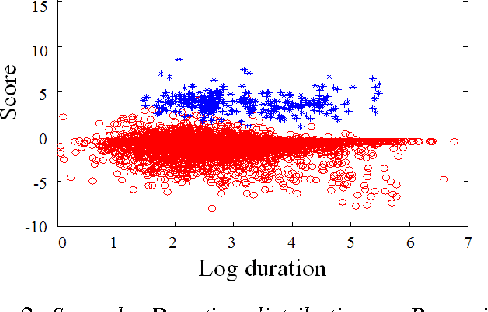
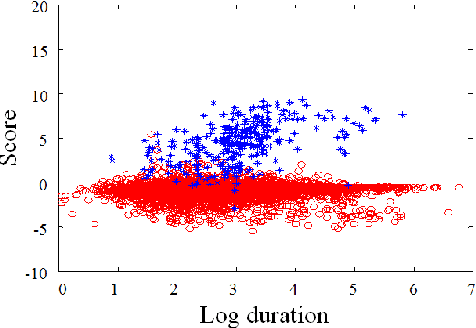
In language recognition, the task of rejecting/differentiating closely spaced versus acoustically far spaced languages remains a major challenge. For confusable closely spaced languages, the system needs longer input test duration material to obtain sufficient information to distinguish between languages. Alternatively, if languages are distinct and not acoustically/linguistically similar to others, duration is not a sufficient remedy. The solution proposed here is to explore duration distribution analysis for near/far languages based on the Language Recognition i-Vector Machine Learning Challenge 2015 (LRiMLC15) database. Using this knowledge, we propose a likelihood ratio based fusion approach that leveraged both score and duration information. The experimental results show that the use of duration and score fusion improves language recognition performance by 5% relative in LRiMLC15 cost.