 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Convex Stochastic Composite Optimization with Polyak Momentum
Mar 05, 2024The stochastic proximal gradient method is a powerful generalization of the widely used stochastic gradient descent (SGD) method and has found numerous applications in Machine Learning. However, it is notoriously known that this method fails to converge in non-convex settings where the stochastic noise is significant (i.e. when only small or bounded batch sizes are used). In this paper, we focus on the stochastic proximal gradient method with Polyak momentum. We prove this method attains an optimal convergence rate for non-convex composite optimization problems, regardless of batch size. Additionally, we rigorously analyze the variance reduction effect of the Polyak momentum in the composite optimization setting and we show the method also converges when the proximal step can only be solved inexactly. Finally, we provide numerical experiments to validate our theoretical results.
Adaptive SGD with Polyak stepsize and Line-search: Robust Convergence and Variance Reduction
Aug 21, 2023The recently proposed stochastic Polyak stepsize (SPS) and stochastic line-search (SLS) for SGD have shown remarkable effectiveness when training over-parameterized models. However, in non-interpolation settings, both algorithms only guarantee convergence to a neighborhood of a solution which may result in a worse output than the initial guess. While artificially decreasing the adaptive stepsize has been proposed to address this issue (Orvieto et al. [2022]), this approach results in slower convergence rates for convex and over-parameterized models. In this work, we make two contributions: Firstly, we propose two new variants of SPS and SLS, called AdaSPS and AdaSLS, which guarantee convergence in non-interpolation settings and maintain sub-linear and linear convergence rates for convex and strongly convex functions when training over-parameterized models. AdaSLS requires no knowledge of problem-dependent parameters, and AdaSPS requires only a lower bound of the optimal function value as input. Secondly, we equip AdaSPS and AdaSLS with a novel variance reduction technique and obtain algorithms that require $\smash{\widetilde{\mathcal{O}}}(n+1/\epsilon)$ gradient evaluations to achieve an $\mathcal{O}(\epsilon)$-suboptimality for convex functions, which improves upon the slower $\mathcal{O}(1/\epsilon^2)$ rates of AdaSPS and AdaSLS without variance reduction in the non-interpolation regimes. Moreover, our result matches the fast rates of AdaSVRG but removes the inner-outer-loop structure, which is easier to implement and analyze. Finally, numerical experiments on synthetic and real datasets validate our theory and demonstrate the effectiveness and robustness of our algorithms.
Locally Adaptive Federated Learning via Stochastic Polyak Stepsizes
Jul 12, 2023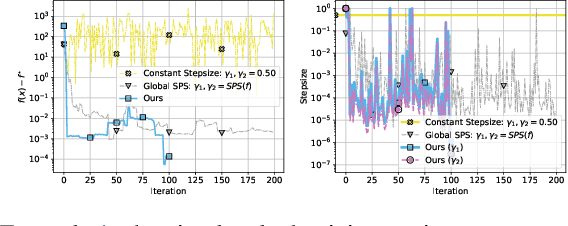

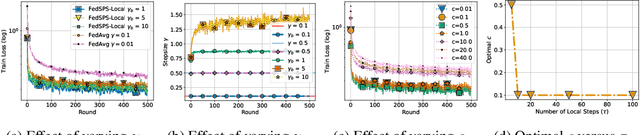
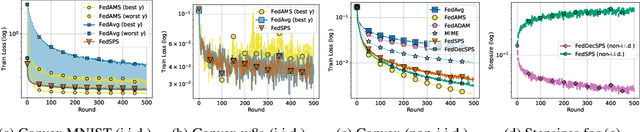
State-of-the-art federated learning algorithms such as FedAvg require carefully tuned stepsizes to achieve their best performance. The improvements proposed by existing adaptive federated methods involve tuning of additional hyperparameters such as momentum parameters, and consider adaptivity only in the server aggregation round, but not locally. These methods can be inefficient in many practical scenarios because they require excessive tuning of hyperparameters and do not capture local geometric information. In this work, we extend the recently proposed stochastic Polyak stepsize (SPS) to the federated learning setting, and propose new locally adaptive and nearly parameter-free distributed SPS variants (FedSPS and FedDecSPS). We prove that FedSPS converges linearly in strongly convex and sublinearly in convex settings when the interpolation condition (overparametrization) is satisfied, and converges to a neighborhood of the solution in the general case. We extend our proposed method to a decreasing stepsize version FedDecSPS, that converges also when the interpolation condition does not hold. We validate our theoretical claims by performing illustrative convex experiments. Our proposed algorithms match the optimization performance of FedAvg with the best tuned hyperparameters in the i.i.d. case, and outperform FedAvg in the non-i.i.d. case.
Synthetic data shuffling accelerates the convergence of federated learning under data heterogeneity
Jun 23, 2023In federated learning, data heterogeneity is a critical challenge. A straightforward solution is to shuffle the clients' data to homogenize the distribution. However, this may violate data access rights, and how and when shuffling can accelerate the convergence of a federated optimization algorithm is not theoretically well understood. In this paper, we establish a precise and quantifiable correspondence between data heterogeneity and parameters in the convergence rate when a fraction of data is shuffled across clients. We prove that shuffling can quadratically reduce the gradient dissimilarity with respect to the shuffling percentage, accelerating convergence. Inspired by the theory, we propose a practical approach that addresses the data access rights issue by shuffling locally generated synthetic data. The experimental results show that shuffling synthetic data improves the performance of multiple existing federated learning algorithms by a large margin.
Shuffle SGD is Always Better than SGD: Improved Analysis of SGD with Arbitrary Data Orders
Jun 15, 2023



Stochastic Gradient Descent (SGD) algorithms are widely used in optimizing neural networks, with Random Reshuffling (RR) and Single Shuffle (SS) being popular choices for cycling through random or single permutations of the training data. However, the convergence properties of these algorithms in the non-convex case are not fully understood. Existing results suggest that, in realistic training scenarios where the number of epochs is smaller than the training set size, RR may perform worse than SGD. In this paper, we analyze a general SGD algorithm that allows for arbitrary data orderings and show improved convergence rates for non-convex functions. Specifically, our analysis reveals that SGD with random and single shuffling is always faster or at least as good as classical SGD with replacement, regardless of the number of iterations. Overall, our study highlights the benefits of using SGD with random/single shuffling and provides new insights into its convergence properties for non-convex optimization.
Revisiting Gradient Clipping: Stochastic bias and tight convergence guarantees
May 02, 2023Gradient clipping is a popular modification to standard (stochastic) gradient descent, at every iteration limiting the gradient norm to a certain value $c >0$. It is widely used for example for stabilizing the training of deep learning models (Goodfellow et al., 2016), or for enforcing differential privacy (Abadi et al., 2016). Despite popularity and simplicity of the clipping mechanism, its convergence guarantees often require specific values of $c$ and strong noise assumptions. In this paper, we give convergence guarantees that show precise dependence on arbitrary clipping thresholds $c$ and show that our guarantees are tight with both deterministic and stochastic gradients. In particular, we show that (i) for deterministic gradient descent, the clipping threshold only affects the higher-order terms of convergence, (ii) in the stochastic setting convergence to the true optimum cannot be guaranteed under the standard noise assumption, even under arbitrary small step-sizes. We give matching upper and lower bounds for convergence of the gradient norm when running clipped SGD, and illustrate these results with experiments.
Decentralized Gradient Tracking with Local Steps
Jan 03, 2023



Gradient tracking (GT) is an algorithm designed for solving decentralized optimization problems over a network (such as training a machine learning model). A key feature of GT is a tracking mechanism that allows to overcome data heterogeneity between nodes. We develop a novel decentralized tracking mechanism, $K$-GT, that enables communication-efficient local updates in GT while inheriting the data-independence property of GT. We prove a convergence rate for $K$-GT on smooth non-convex functions and prove that it reduces the communication overhead asymptotically by a linear factor $K$, where $K$ denotes the number of local steps. We illustrate the robustness and effectiveness of this heterogeneity correction on convex and non-convex benchmark problems and on a non-convex neural network training task with the MNIST dataset.
Partial Variance Reduction improves Non-Convex Federated learning on heterogeneous data
Dec 05, 2022Data heterogeneity across clients is a key challenge in federated learning. Prior works address this by either aligning client and server models or using control variates to correct client model drift. Although these methods achieve fast convergence in convex or simple non-convex problems, the performance in over-parameterized models such as deep neural networks is lacking. In this paper, we first revisit the widely used FedAvg algorithm in a deep neural network to understand how data heterogeneity influences the gradient updates across the neural network layers. We observe that while the feature extraction layers are learned efficiently by FedAvg, the substantial diversity of the final classification layers across clients impedes the performance. Motivated by this, we propose to correct model drift by variance reduction only on the final layers. We demonstrate that this significantly outperforms existing benchmarks at a similar or lower communication cost. We furthermore provide proof for the convergence rate of our algorithm.
Sharper Convergence Guarantees for Asynchronous SGD for Distributed and Federated Learning
Jun 16, 2022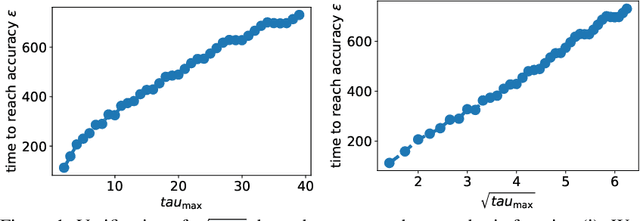
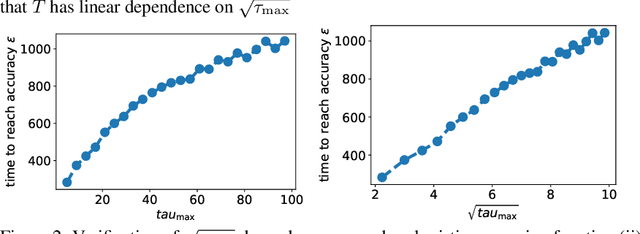
We study the asynchronous stochastic gradient descent algorithm for distributed training over $n$ workers which have varying computation and communication frequency over time. In this algorithm, workers compute stochastic gradients in parallel at their own pace and return those to the server without any synchronization. Existing convergence rates of this algorithm for non-convex smooth objectives depend on the maximum gradient delay $\tau_{\max}$ and show that an $\epsilon$-stationary point is reached after $\mathcal{O}\!\left(\sigma^2\epsilon^{-2}+ \tau_{\max}\epsilon^{-1}\right)$ iterations, where $\sigma$ denotes the variance of stochastic gradients. In this work (i) we obtain a tighter convergence rate of $\mathcal{O}\!\left(\sigma^2\epsilon^{-2}+ \sqrt{\tau_{\max}\tau_{avg}}\epsilon^{-1}\right)$ without any change in the algorithm where $\tau_{avg}$ is the average delay, which can be significantly smaller than $\tau_{\max}$. We also provide (ii) a simple delay-adaptive learning rate scheme, under which asynchronous SGD achieves a convergence rate of $\mathcal{O}\!\left(\sigma^2\epsilon^{-2}+ \tau_{avg}\epsilon^{-1}\right)$, and does not require any extra hyperparameter tuning nor extra communications. Our result allows to show for the first time that asynchronous SGD is always faster than mini-batch SGD. In addition, (iii) we consider the case of heterogeneous functions motivated by federated learning applications and improve the convergence rate by proving a weaker dependence on the maximum delay compared to prior works. In particular, we show that the heterogeneity term in convergence rate is only affected by the average delay within each worker.
Data-heterogeneity-aware Mixing for Decentralized Learning
Apr 13, 2022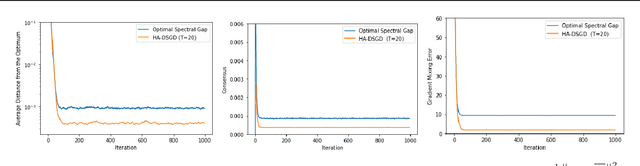
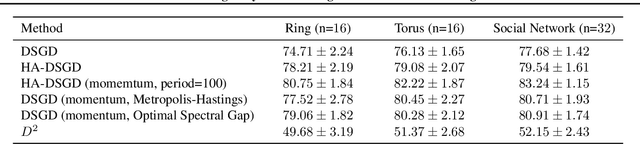
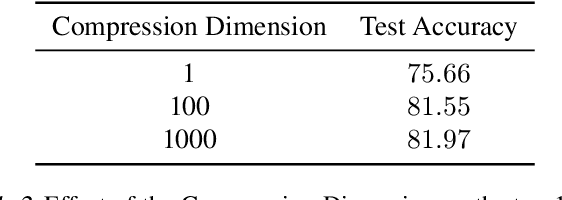
Decentralized learning provides an effective framework to train machine learning models with data distributed over arbitrary communication graphs. However, most existing approaches toward decentralized learning disregard the interaction between data heterogeneity and graph topology. In this paper, we characterize the dependence of convergence on the relationship between the mixing weights of the graph and the data heterogeneity across nodes. We propose a metric that quantifies the ability of a graph to mix the current gradients. We further prove that the metric controls the convergence rate, particularly in settings where the heterogeneity across nodes dominates the stochasticity between updates for a given node. Motivated by our analysis, we propose an approach that periodically and efficiently optimizes the metric using standard convex constrained optimization and sketching techniques. Through comprehensive experiments on standard computer vision and NLP benchmarks, we show that our approach leads to improvement in test performance for a wide range of tasks.