 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Training Methods for GANs do actually Converge?
Jul 31, 2018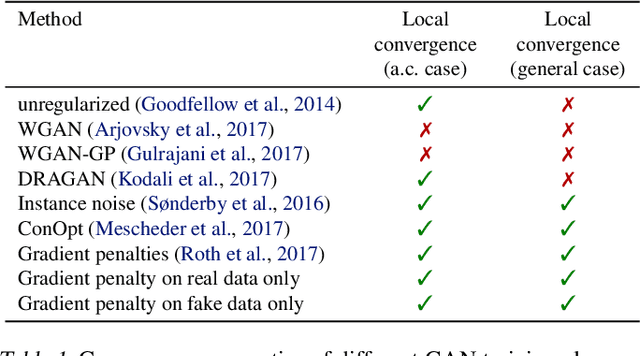
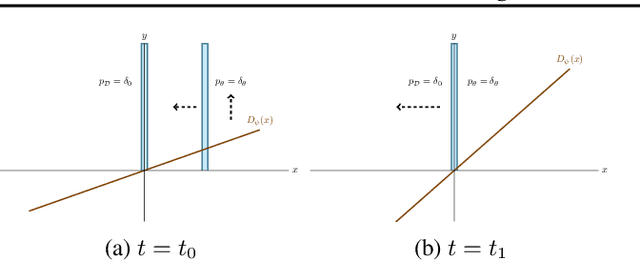
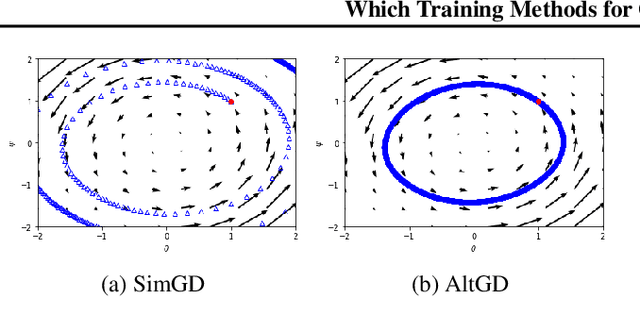
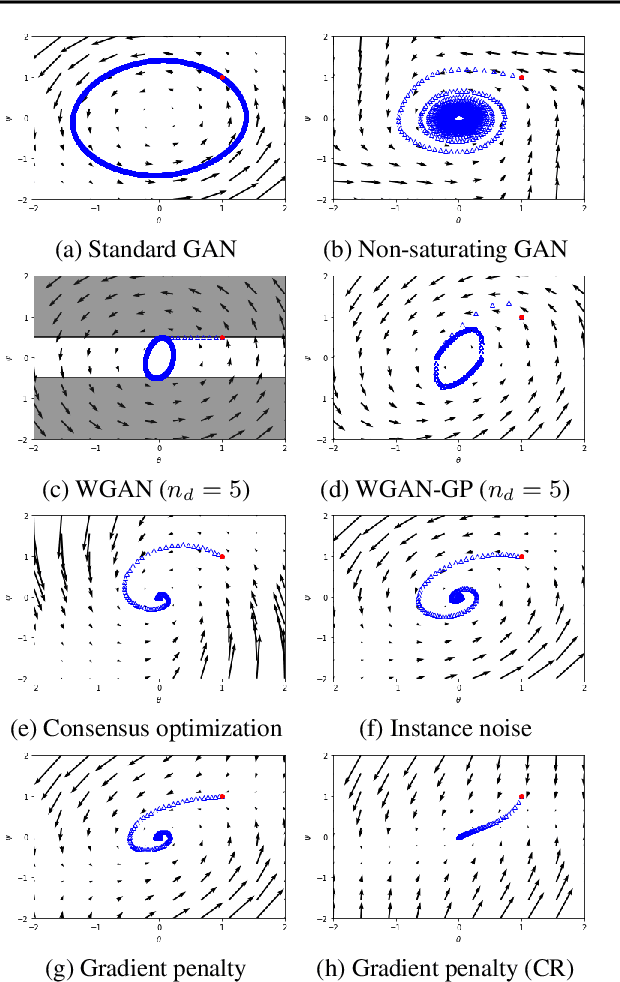
Recent work has shown local convergence of GAN training for absolutely continuous data and generator distributions. In this paper, we show that the requirement of absolute continuity is necessary: we describe a simple yet prototypical counterexample showing that in the more realistic case of distributions that are not absolutely continuous, unregularized GAN training is not always convergent. Furthermore, we discuss regularization strategies that were recently proposed to stabilize GAN training. Our analysis shows that GAN training with instance noise or zero-centered gradient penalties converges. On the other hand, we show that Wasserstein-GANs and WGAN-GP with a finite number of discriminator updates per generator update do not always converge to the equilibrium point. We discuss these results, leading us to a new explanation for the stability problems of GAN training. Based on our analysis, we extend our convergence results to more general GANs and prove local convergence for simplified gradient penalties even if the generator and data distribution lie on lower dimensional manifolds. We find these penalties to work well in practice and use them to learn high-resolution generative image models for a variety of datasets with little hyperparameter tuning.
* conference
From Face Recognition to Models of Identity: A Bayesian Approach to Learning about Unknown Identities from Unsupervised Data
Jul 20, 2018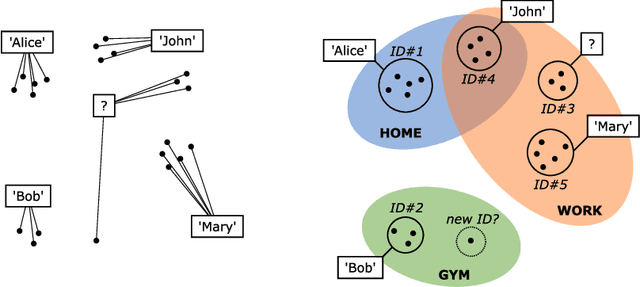
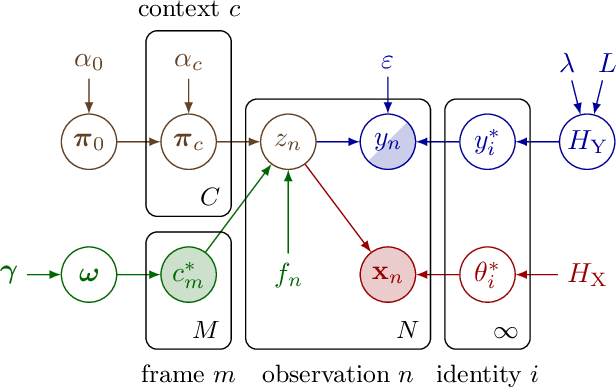
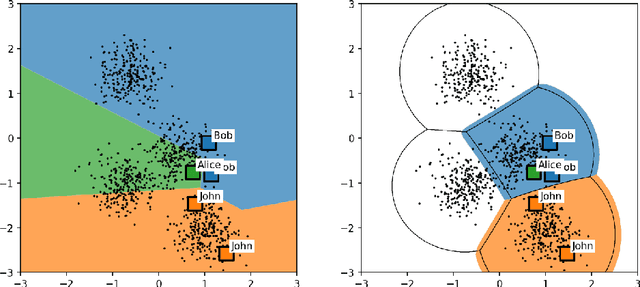
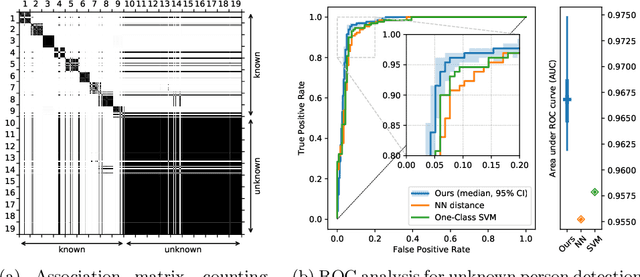
Current face recognition systems robustly recognize identities across a wide variety of imaging conditions. In these systems recognition is performed via classification into known identities obtained from supervised identity annotations. There are two problems with this current paradigm: (1) current systems are unable to benefit from unlabelled data which may be available in large quantities; and (2) current systems equate successful recognition with labelling a given input image. Humans, on the other hand, regularly perform identification of individuals completely unsupervised, recognising the identity of someone they have seen before even without being able to name that individual. How can we go beyond the current classification paradigm towards a more human understanding of identities? We propose an integrated Bayesian model that coherently reasons about the observed images, identities, partial knowledge about names, and the situational context of each observation. While our model achieves good recognition performance against known identities, it can also discover new identities from unsupervised data and learns to associate identities with different contexts depending on which identities tend to be observed together. In addition, the proposed semi-supervised component is able to handle not only acquaintances, whose names are known, but also unlabelled familiar faces and complete strangers in a unified framework.
The Numerics of GANs
Jun 11, 2018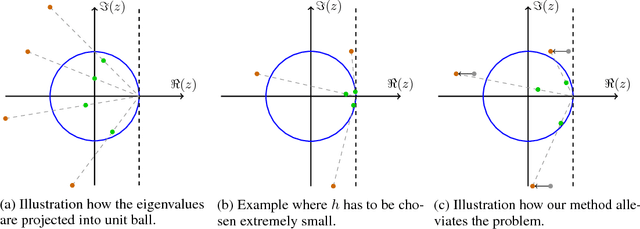

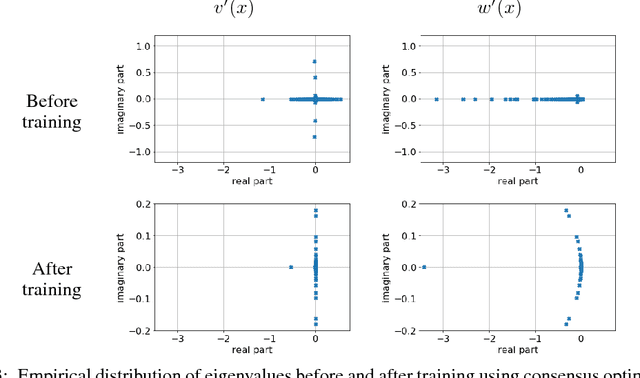

In this paper, we analyze the numerics of common algorithms for training Generative Adversarial Networks (GANs). Using the formalism of smooth two-player games we analyze the associated gradient vector field of GAN training objectives. Our findings suggest that the convergence of current algorithms suffers due to two factors: i) presence of eigenvalues of the Jacobian of the gradient vector field with zero real-part, and ii) eigenvalues with big imaginary part. Using these findings, we design a new algorithm that overcomes some of these limitations and has better convergence properties. Experimentally, we demonstrate its superiority on training common GAN architectures and show convergence on GAN architectures that are known to be notoriously hard to train.
Adversarial Variational Bayes: Unifying Variational Autoencoders and Generative Adversarial Networks
Jun 11, 2018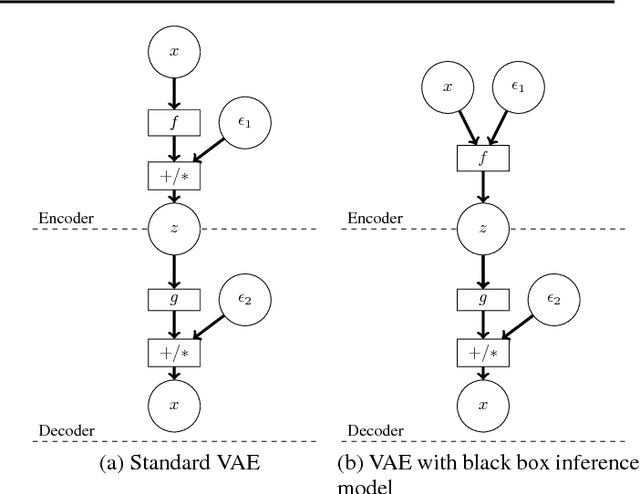

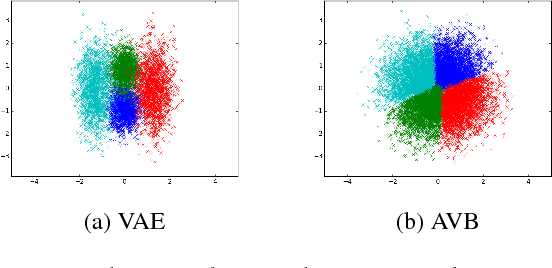

Variational Autoencoders (VAEs) are expressive latent variable models that can be used to learn complex probability distributions from training data. However, the quality of the resulting model crucially relies on the expressiveness of the inference model. We introduce Adversarial Variational Bayes (AVB), a technique for training Variational Autoencoders with arbitrarily expressive inference models. We achieve this by introducing an auxiliary discriminative network that allows to rephrase the maximum-likelihood-problem as a two-player game, hence establishing a principled connection between VAEs and Generative Adversarial Networks (GANs). We show that in the nonparametric limit our method yields an exact maximum-likelihood assignment for the parameters of the generative model, as well as the exact posterior distribution over the latent variables given an observation. Contrary to competing approaches which combine VAEs with GANs, our approach has a clear theoretical justification, retains most advantages of standard Variational Autoencoders and is easy to implement.
Decision-Theoretic Meta-Learning: Versatile and Efficient Amortization of Few-Shot Learning
May 31, 2018

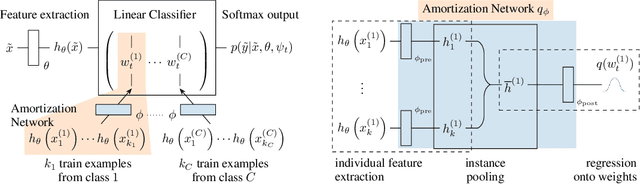
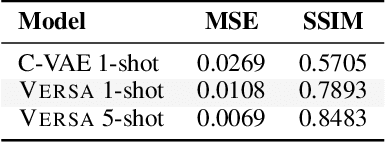
This paper develops a general framework for data efficient and versatile deep learning. The new framework comprises three elements: 1) Discriminative probabilistic models from multi-task learning that leverage shared statistical information across tasks. 2) A novel Bayesian decision theoretic approach to meta-learning probabilistic inference across many tasks. 3) A fast, flexible, and simple to train amortization network that can automatically generalize and extrapolate to a wide range of settings. The VERSA algorithm, a particular instance of the framework, is evaluated on a suite of supervised few-shot learning tasks. VERSA achieves state-of-the-art performance in one-shot learning on Omniglot and miniImagenet, and produces compelling results on a one-shot ShapeNet view reconstruction challenge.
Adversarially Robust Training through Structured Gradient Regularization
May 22, 2018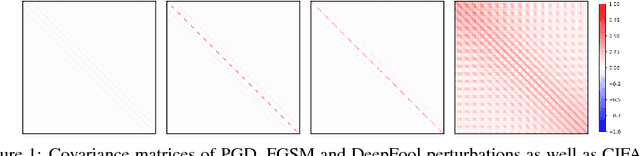



We propose a novel data-dependent structured gradient regularizer to increase the robustness of neural networks vis-a-vis adversarial perturbations. Our regularizer can be derived as a controlled approximation from first principles, leveraging the fundamental link between training with noise and regularization. It adds very little computational overhead during learning and is simple to implement generically in standard deep learning frameworks. Our experiments provide strong evidence that structured gradient regularization can act as an effective first line of defense against attacks based on low-level signal corruption.
PixelDefend: Leveraging Generative Models to Understand and Defend against Adversarial Examples
May 21, 2018
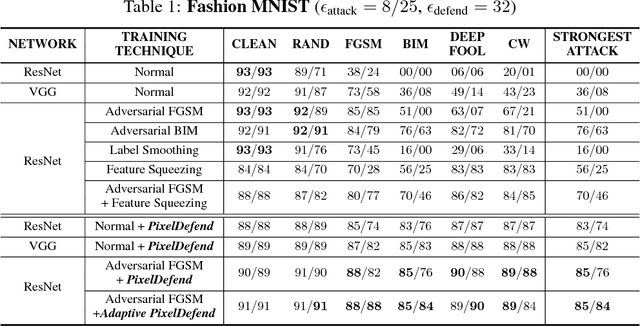
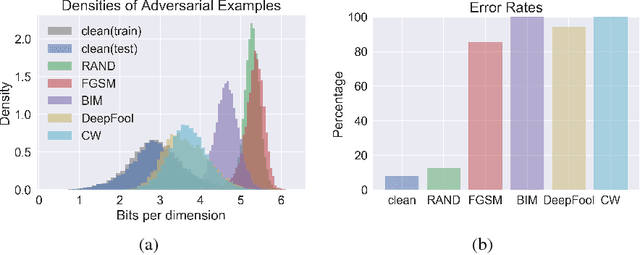
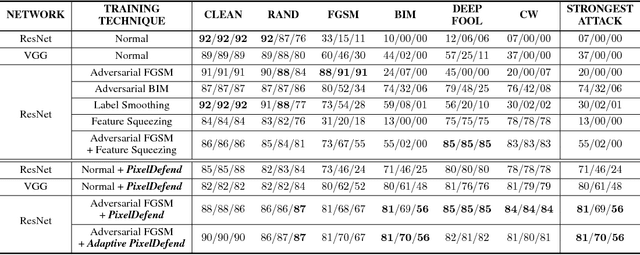
Adversarial perturbations of normal images are usually imperceptible to humans, but they can seriously confuse state-of-the-art machine learning models. What makes them so special in the eyes of image classifiers? In this paper, we show empirically that adversarial examples mainly lie in the low probability regions of the training distribution, regardless of attack types and targeted models. Using statistical hypothesis testing, we find that modern neural density models are surprisingly good at detecting imperceptible image perturbations. Based on this discovery, we devised PixelDefend, a new approach that purifies a maliciously perturbed image by moving it back towards the distribution seen in the training data. The purified image is then run through an unmodified classifier, making our method agnostic to both the classifier and the attacking method. As a result, PixelDefend can be used to protect already deployed models and be combined with other model-specific defenses. Experiments show that our method greatly improves resilience across a wide variety of state-of-the-art attacking methods, increasing accuracy on the strongest attack from 63% to 84% for Fashion MNIST and from 32% to 70% for CIFAR-10.
Deep Directional Statistics: Pose Estimation with Uncertainty Quantification
May 09, 2018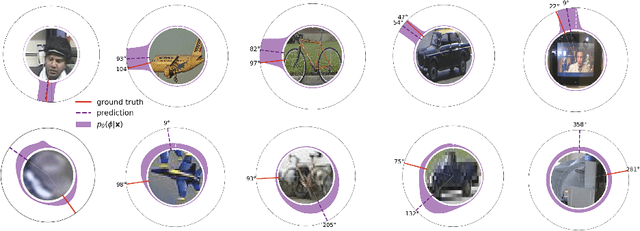

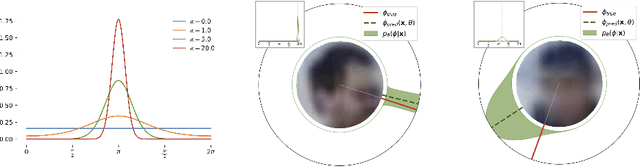
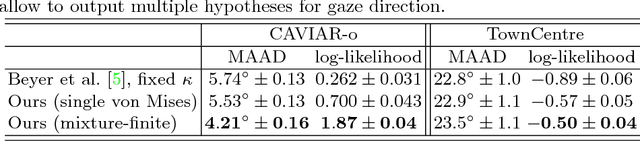
Modern deep learning systems successfully solve many perception tasks such as object pose estimation when the input image is of high quality. However, in challenging imaging conditions such as on low-resolution images or when the image is corrupted by imaging artifacts, current systems degrade considerably in accuracy. While a loss in performance is unavoidable, we would like our models to quantify their uncertainty in order to achieve robustness against images of varying quality. Probabilistic deep learning models combine the expressive power of deep learning with uncertainty quantification. In this paper, we propose a novel probabilistic deep learning model for the task of angular regression. Our model uses von Mises distributions to predict a distribution over object pose angle. Whereas a single von Mises distribution is making strong assumptions about the shape of the distribution, we extend the basic model to predict a mixture of von Mises distributions. We show how to learn a mixture model using a finite and infinite number of mixture components. Our model allows for likelihood-based training and efficient inference at test time. We demonstrate on a number of challenging pose estimation datasets that our model produces calibrated probability predictions and competitive or superior point estimates compared to the current state-of-the-art.
DSAC - Differentiable RANSAC for Camera Localization
Mar 21, 2018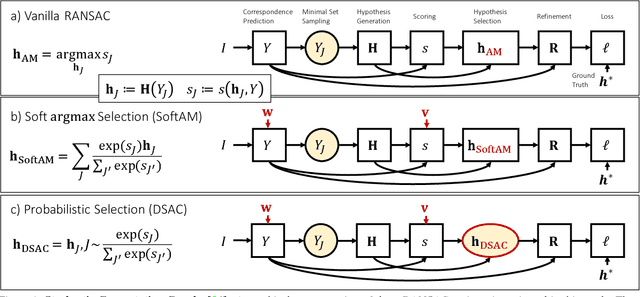
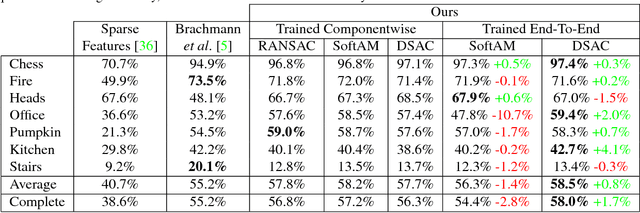

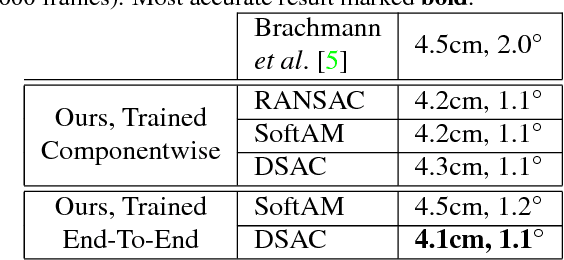
RANSAC is an important algorithm in robust optimization and a central building block for many computer vision applications. In recent years, traditionally hand-crafted pipelines have been replaced by deep learning pipelines, which can be trained in an end-to-end fashion. However, RANSAC has so far not been used as part of such deep learning pipelines, because its hypothesis selection procedure is non-differentiable. In this work, we present two different ways to overcome this limitation. The most promising approach is inspired by reinforcement learning, namely to replace the deterministic hypothesis selection by a probabilistic selection for which we can derive the expected loss w.r.t. to all learnable parameters. We call this approach DSAC, the differentiable counterpart of RANSAC. We apply DSAC to the problem of camera localization, where deep learning has so far failed to improve on traditional approaches. We demonstrate that by directly minimizing the expected loss of the output camera poses, robustly estimated by RANSAC, we achieve an increase in accuracy. In the future, any deep learning pipeline can use DSAC as a robust optimization component.
Hybrid VAE: Improving Deep Generative Models using Partial Observations
Nov 30, 2017
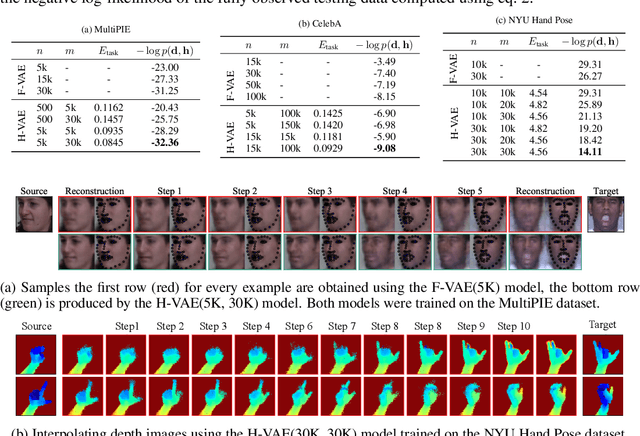
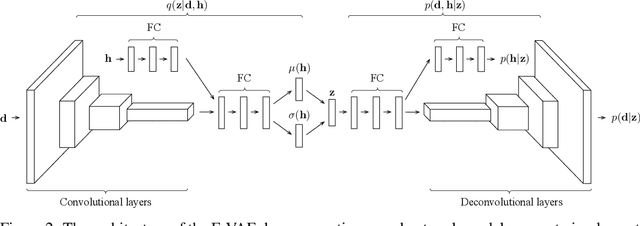
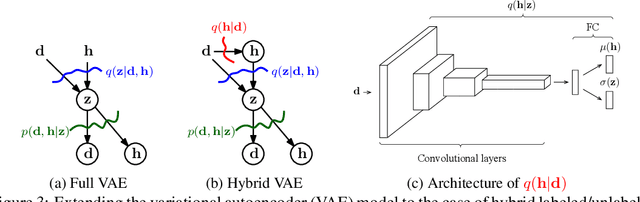
Deep neural network models trained on large labeled datasets are the state-of-the-art in a large variety of computer vision tasks. In many applications, however, labeled data is expensive to obtain or requires a time consuming manual annotation process. In contrast, unlabeled data is often abundant and available in large quantities. We present a principled framework to capitalize on unlabeled data by training deep generative models on both labeled and unlabeled data. We show that such a combination is beneficial because the unlabeled data acts as a data-driven form of regularization, allowing generative models trained on few labeled samples to reach the performance of fully-supervised generative models trained on much larger datasets. We call our method Hybrid VAE (H-VAE) as it contains both the generative and the discriminative parts. We validate H-VAE on three large-scale datasets of different modalities: two face datasets: (MultiPIE, CelebA) and a hand pose dataset (NYU Hand Pose). Our qualitative visualizations further support improvements achieved by using partial observations.