 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGD: The Role of Implicit Regularization, Batch-size and Multiple-epochs
Jul 11, 2021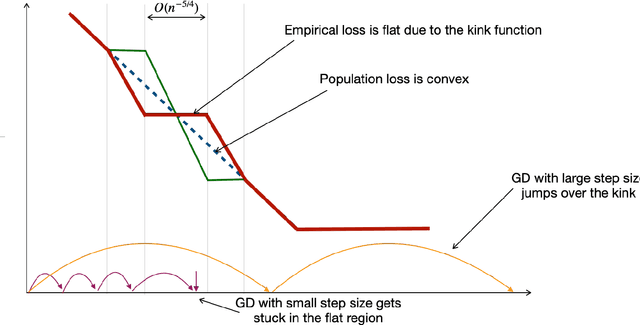
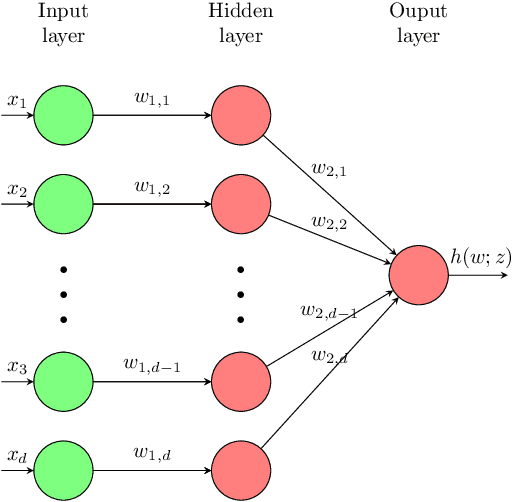
Multi-epoch, small-batch, Stochastic Gradient Descent (SGD) has been the method of choice for learning with large over-parameterized models. A popular theory for explaining why SGD works well in practice is that the algorithm has an implicit regularization that biases its output towards a good solution. Perhaps the theoretically most well understood learning setting for SGD is that of Stochastic Convex Optimization (SCO), where it is well known that SGD learns at a rate of $O(1/\sqrt{n})$, where $n$ is the number of samples. In this paper, we consider the problem of SCO and explore the role of implicit regularization, batch size and multiple epochs for SGD. Our main contributions are threefold: (a) We show that for any regularizer, there is an SCO problem for which Regularized Empirical Risk Minimzation fails to learn. This automatically rules out any implicit regularization based explanation for the success of SGD. (b) We provide a separation between SGD and learning via Gradient Descent on empirical loss (GD) in terms of sample complexity. We show that there is an SCO problem such that GD with any step size and number of iterations can only learn at a suboptimal rate: at least $\widetilde{\Omega}(1/n^{5/12})$. (c) We present a multi-epoch variant of SGD commonly used in practice. We prove that this algorithm is at least as good as single pass SGD in the worst case. However, for certain SCO problems, taking multiple passes over the dataset can significantly outperform single pass SGD. We extend our results to the general learning setting by showing a problem which is learnable for any data distribution, and for this problem, SGD is strictly better than RERM for any regularization function. We conclude by discussing the implications of our results for deep learning, and show a separation between SGD and ERM for two layer diagonal neural networks.
Federated Functional Gradient Boosting
Mar 11, 2021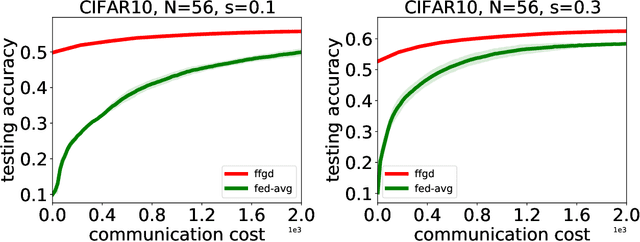
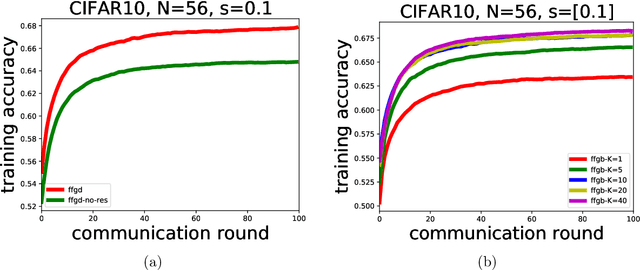
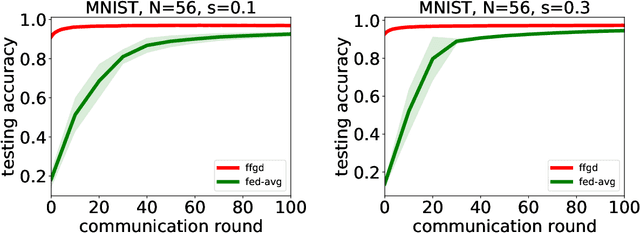
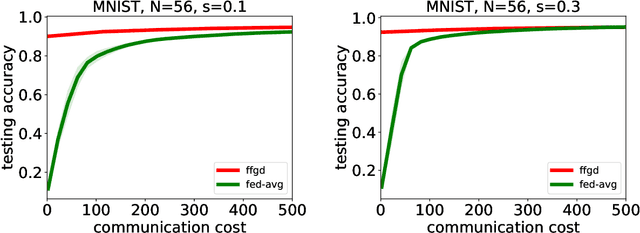
In this paper, we initiate a study of functional minimization in Federated Learning. First, in the semi-heterogeneous setting, when the marginal distributions of the feature vectors on client machines are identical, we develop the federated functional gradient boosting (FFGB) method that provably converges to the global minimum. Subsequently, we extend our results to the fully-heterogeneous setting (where marginal distributions of feature vectors may differ) by designing an efficient variant of FFGB called FFGB.C, with provable convergence to a neighborhood of the global minimum within a radius that depends on the total variation distances between the client feature distributions. For the special case of square loss, but still in the fully heterogeneous setting, we design the FFGB.L method that also enjoys provable convergence to a neighborhood of the global minimum but within a radius depending on the much tighter Wasserstein-1 distances. For both FFGB.C and FFGB.L, the radii of convergence shrink to zero as the feature distributions become more homogeneous. Finally, we conduct proof-of-concept experiments to demonstrate the benefits of our approach against natural baselines.
A Multiclass Boosting Framework for Achieving Fast and Provable Adversarial Robustness
Mar 03, 2021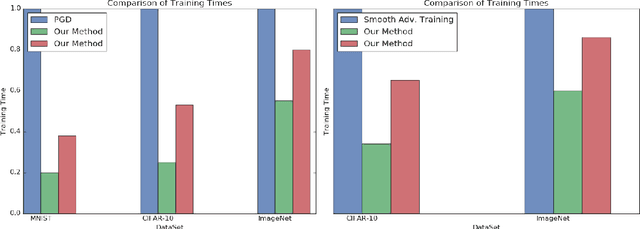
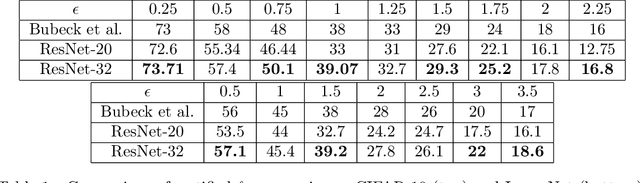
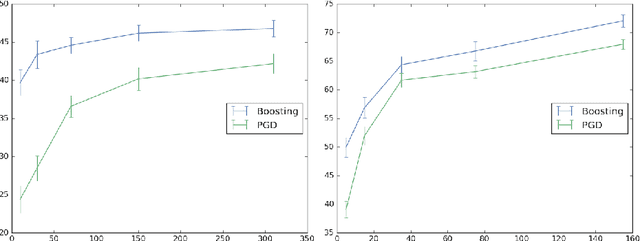

Alongside the well-publicized accomplishments of deep neural networks there has emerged an apparent bug in their success on tasks such as object recognition: with deep models trained using vanilla methods, input images can be slightly corrupted in order to modify output predictions, even when these corruptions are practically invisible. This apparent lack of robustness has led researchers to propose methods that can help to prevent an adversary from having such capabilities. The state-of-the-art approaches have incorporated the robustness requirement into the loss function, and the training process involves taking stochastic gradient descent steps not using original inputs but on adversarially-corrupted ones. In this paper we propose a multiclass boosting framework to ensure adversarial robustness. Boosting algorithms are generally well-suited for adversarial scenarios, as they were classically designed to satisfy a minimax guarantee. We provide a theoretical foundation for this methodology and describe conditions under which robustness can be achieved given a weak training oracle. We show empirically that adversarially-robust multiclass boosting not only outperforms the state-of-the-art methods, it does so at a fraction of the training time.
Learning with User-Level Privacy
Mar 02, 2021We propose and analyze algorithms to solve a range of learning tasks under user-level differential privacy constraints. Rather than guaranteeing only the privacy of individual samples, user-level DP protects a user's entire contribution ($m \ge 1$ samples), providing more stringent but more realistic protection against information leaks. We show that for high-dimensional mean estimation, empirical risk minimization with smooth losses, stochastic convex optimization, and learning hypothesis class with finite metric entropy, the privacy cost decreases as $O(1/\sqrt{m})$ as users provide more samples. In contrast, when increasing the number of users $n$, the privacy cost decreases at a faster $O(1/n)$ rate. We complement these results with lower bounds showing the worst-case optimality of our algorithm for mean estimation and stochastic convex optimization. Our algorithms rely on novel techniques for private mean estimation in arbitrary dimension with error scaling as the concentration radius $\tau$ of the distribution rather than the entire range. Under uniform convergence, we derive an algorithm that privately answers a sequence of $K$ adaptively chosen queries with privacy cost proportional to $\tau$, and apply it to solve the learning tasks we consider.
Mime: Mimicking Centralized Stochastic Algorithms in Federated Learning
Aug 08, 2020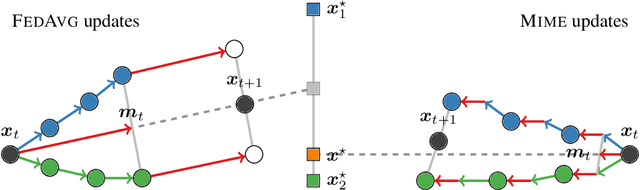

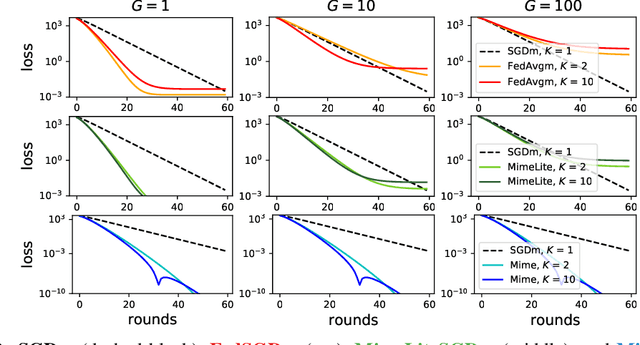

Federated learning is a challenging optimization problem due to the heterogeneity of the data across different clients. Such heterogeneity has been observed to induce client drift and significantly degrade the performance of algorithms designed for this setting. In contrast, centralized learning with centrally collected data does not experience such drift, and has seen great empirical and theoretical progress with innovations such as momentum, adaptivity, etc. In this work, we propose a general framework Mime which mitigates client-drift and adapts arbitrary centralized optimization algorithms (e.g.\ SGD, Adam, etc.) to federated learning. Mime uses a combination of control-variates and server-level statistics (e.g. momentum) at every client-update step to ensure that each local update mimics that of the centralized method. Our thorough theoretical and empirical analyses strongly establish Mime's superiority over other baselines.
Estimating Training Data Influence by Tracking Gradient Descent
Feb 19, 2020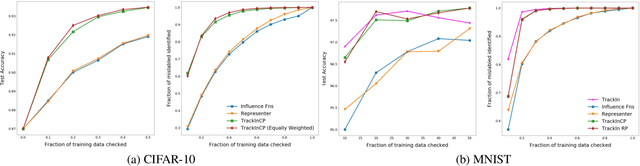

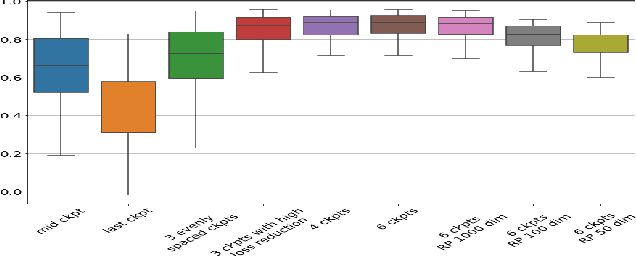
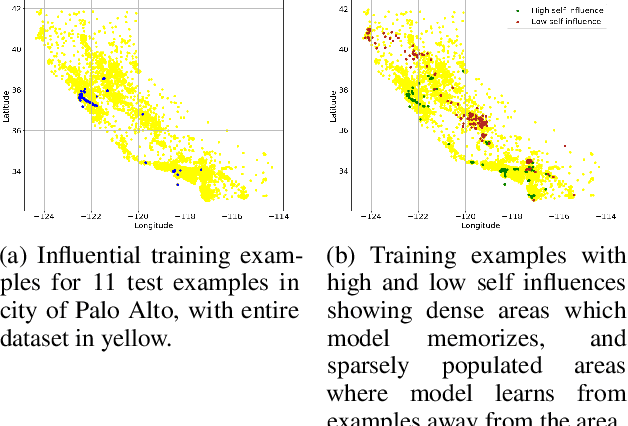
We introduce a method called TrackIn that computes the influence of a training example on a prediction made by the model, by tracking how the loss on the test point changes during the training process whenever the training example of interest was utilized. We provide a scalable implementation of TrackIn via a combination of a few key ideas: (a) a first-order approximation to the exact computation, (b) using random projections to speed up the computation of the first-order approximation for large models, (c) using saved checkpoints of standard training procedures, and (d) cherry-picking layers of a deep neural network. An experimental evaluation shows that TrackIn is more effective in identifying mislabelled training examples than other related methods such as influence functions and representer points. We also discuss insights from applying the method on vision, regression and natural language tasks.
A Deep Conditioning Treatment of Neural Networks
Feb 04, 2020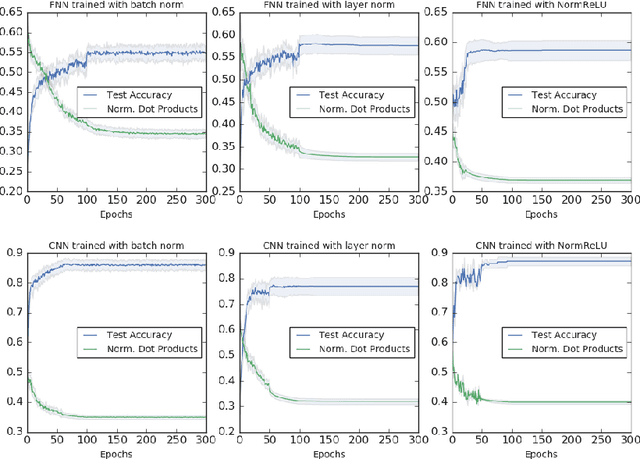
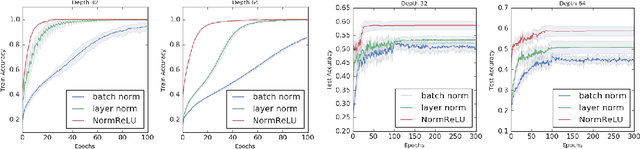
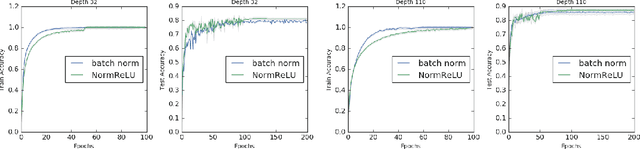
We study the role of depth in training randomly initialized overparameterized neural networks. We give the first general result showing that depth improves trainability of neural networks by improving the {\em conditioning} of certain kernel matrices of the input data. This result holds for arbitrary non-linear activation functions, and we provide a characterization of the improvement in conditioning as a function of the degree of non-linearity and the depth of the network. We provide versions of the result that hold for training just the top layer of the neural network, as well as for training all layers, via the neural tangent kernel. As applications of these general results, we provide a generalization of the results of Das et al. (2019) showing that learnability of deep random neural networks with arbitrary non-linear activations (under mild assumptions) degrades exponentially with depth. Additionally, we show how benign overfitting can occur in deep neural networks via the results of Bartlett et al. (2019b).
SCAFFOLD: Stochastic Controlled Averaging for On-Device Federated Learning
Oct 14, 2019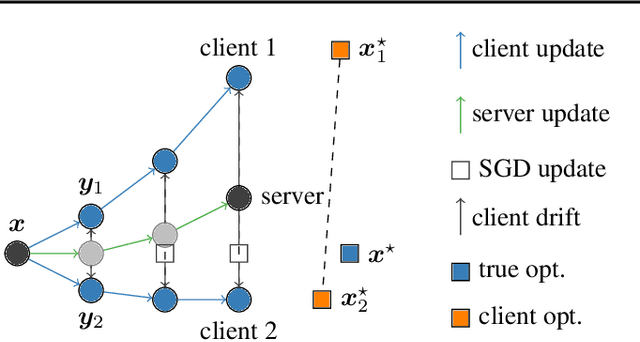
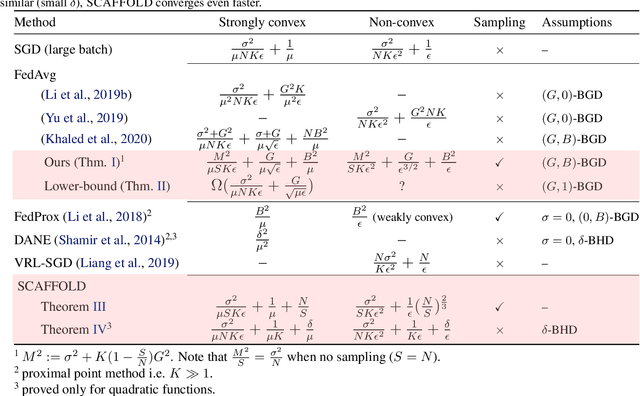
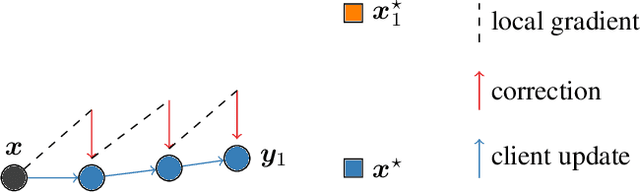
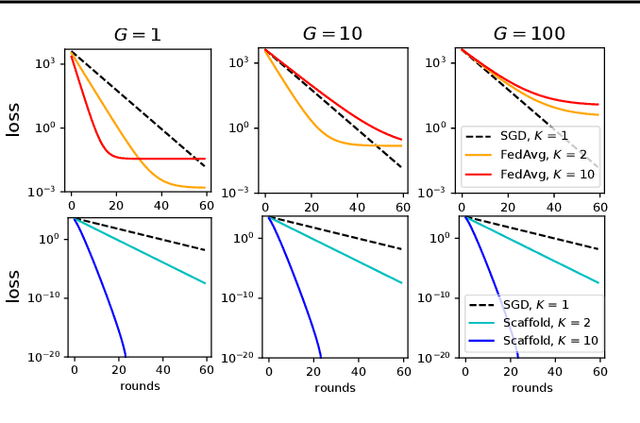
Federated learning is a key scenario in modern large-scale machine learning. In that scenario, the training data remains distributed over a large number of clients, which may be phones, other mobile devices, or network sensors and a centralized model is learned without ever transmitting client data over the network. The standard optimization algorithm used in this scenario is Federated Averaging (FedAvg). However, when client data is heterogeneous, which is typical in applications, FedAvg does not admit a favorable convergence guarantee. This is because local updates on clients can drift apart, which also explains the slow convergence and hard-to-tune nature of FedAvg in practice. This paper presents a new Stochastic Controlled Averaging algorithm (SCAFFOLD) which uses control variates to reduce the drift between different clients. We prove that the algorithm requires significantly fewer rounds of communication and benefits from favorable convergence guarantees.
On the Convergence of Adam and Beyond
Apr 19, 2019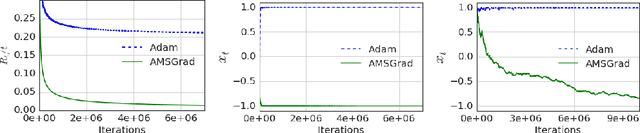
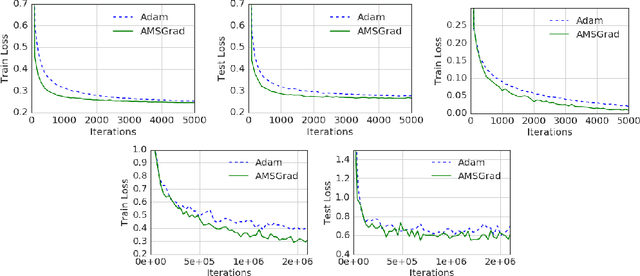
Several recently proposed stochastic optimization methods that have been successfully used in training deep networks such as RMSProp, Adam, Adadelta, Nadam are based on using gradient updates scaled by square roots of exponential moving averages of squared past gradients. In many applications, e.g. learning with large output spaces, it has been empirically observed that these algorithms fail to converge to an optimal solution (or a critical point in nonconvex settings). We show that one cause for such failures is the exponential moving average used in the algorithms. We provide an explicit example of a simple convex optimization setting where Adam does not converge to the optimal solution, and describe the precise problems with the previous analysis of Adam algorithm. Our analysis suggests that the convergence issues can be fixed by endowing such algorithms with `long-term memory' of past gradients, and propose new variants of the Adam algorithm which not only fix the convergence issues but often also lead to improved empirical performance.
Hypothesis Set Stability and Generalization
Apr 17, 2019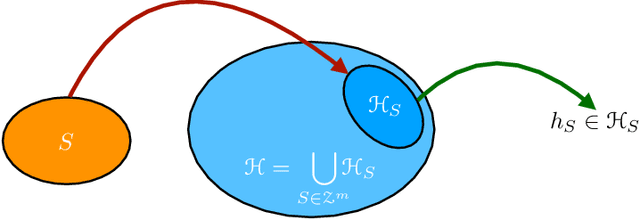
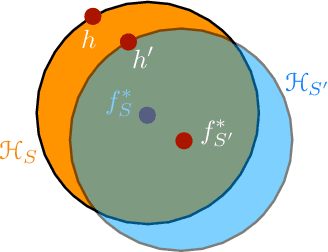
We present an extensive study of generalization for data-dependent hypothesis sets. We give a general learning guarantee for data-dependent hypothesis sets based on a notion of transductive Rademacher complexity. Our main results are two generalization bounds for data-dependent hypothesis sets expressed in terms of a notion of hypothesis set stability and a notion of Rademacher complexity for data-dependent hypothesis sets that we introduce. These bounds admit as special cases both standard Rademacher complexity bounds and algorithm-dependent uniform stability bounds. We also illustrate the use of these learning bounds in the analysis of several scenarios.