 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBB-Patch: BlackBox Adversarial Patch-Attack using Zeroth-Order Optimization
May 09, 2024



Deep Learning has become popular due to its vast applications in almost all domains. However, models trained using deep learning are prone to failure for adversarial samples and carry a considerable risk in sensitive applications. Most of these adversarial attack strategies assume that the adversary has access to the training data, the model parameters, and the input during deployment, hence, focus on perturbing the pixel level information present in the input image. Adversarial Patches were introduced to the community which helped in bringing out the vulnerability of deep learning models in a much more pragmatic manner but here the attacker has a white-box access to the model parameters. Recently, there has been an attempt to develop these adversarial attacks using black-box techniques. However, certain assumptions such as availability large training data is not valid for a real-life scenarios. In a real-life scenario, the attacker can only assume the type of model architecture used from a select list of state-of-the-art architectures while having access to only a subset of input dataset. Hence, we propose an black-box adversarial attack strategy that produces adversarial patches which can be applied anywhere in the input image to perform an adversarial attack.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
PEg TRAnsfer Workflow recognition challenge report: Does multi-modal data improve recognition?
Feb 11, 2022
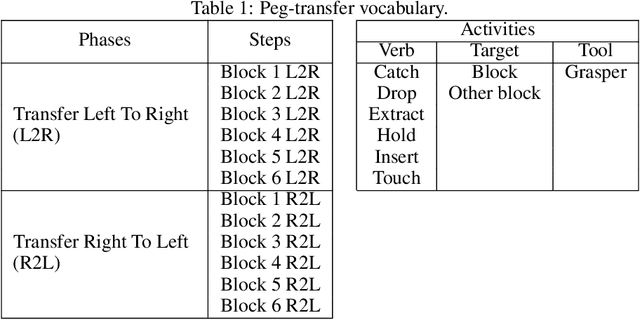
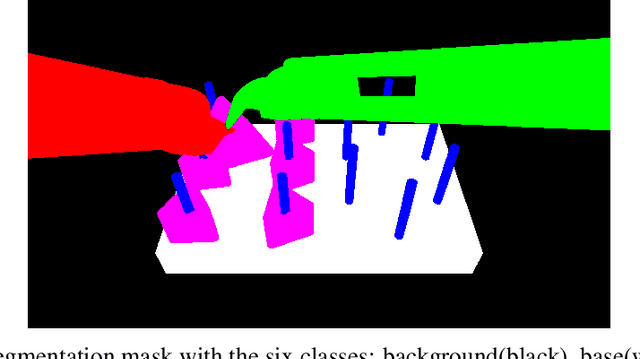
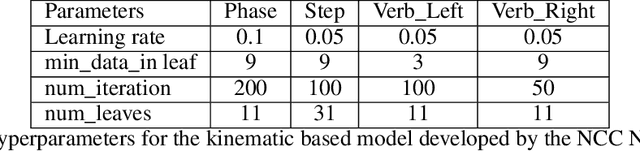
This paper presents the design and results of the "PEg TRAnsfert Workflow recognition" (PETRAW) challenge whose objective was to develop surgical workflow recognition methods based on one or several modalities, among video, kinematic, and segmentation data, in order to study their added value. The PETRAW challenge provided a data set of 150 peg transfer sequences performed on a virtual simulator. This data set was composed of videos, kinematics, semantic segmentation, and workflow annotations which described the sequences at three different granularity levels: phase, step, and activity. Five tasks were proposed to the participants: three of them were related to the recognition of all granularities with one of the available modalities, while the others addressed the recognition with a combination of modalities. Average application-dependent balanced accuracy (AD-Accuracy) was used as evaluation metric to take unbalanced classes into account and because it is more clinically relevant than a frame-by-frame score. Seven teams participated in at least one task and four of them in all tasks. Best results are obtained with the use of the video and the kinematics data with an AD-Accuracy between 93% and 90% for the four teams who participated in all tasks. The improvement between video/kinematic-based methods and the uni-modality ones was significant for all of the teams. However, the difference in testing execution time between the video/kinematic-based and the kinematic-based methods has to be taken into consideration. Is it relevant to spend 20 to 200 times more computing time for less than 3% of improvement? The PETRAW data set is publicly available at www.synapse.org/PETRAW to encourage further research in surgical workflow recognition.