 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Active Learning for the Search of Small-molecule Protein Binders
May 02, 2024



Despite substantial progress in machine learning for scientific discovery in recent years, truly de novo design of small molecules which exhibit a property of interest remains a significant challenge. We introduce LambdaZero, a generative active learning approach to search for synthesizable molecules. Powered by deep reinforcement learning, LambdaZero learns to search over the vast space of molecules to discover candidates with a desired property. We apply LambdaZero with molecular docking to design novel small molecules that inhibit the enzyme soluble Epoxide Hydrolase 2 (sEH), while enforcing constraints on synthesizability and drug-likeliness. LambdaZero provides an exponential speedup in terms of the number of calls to the expensive molecular docking oracle, and LambdaZero de novo designed molecules reach docking scores that would otherwise require the virtual screening of a hundred billion molecules. Importantly, LambdaZero discovers novel scaffolds of synthesizable, drug-like inhibitors for sEH. In in vitro experimental validation, a series of ligands from a generated quinazoline-based scaffold were synthesized, and the lead inhibitor N-(4,6-di(pyrrolidin-1-yl)quinazolin-2-yl)-N-methylbenzamide (UM0152893) displayed sub-micromolar enzyme inhibition of sEH.
DistGNN-MB: Distributed Large-Scale Graph Neural Network Training on x86 via Minibatch Sampling
Nov 11, 2022



Training Graph Neural Networks, on graphs containing billions of vertices and edges, at scale using minibatch sampling poses a key challenge: strong-scaling graphs and training examples results in lower compute and higher communication volume and potential performance loss. DistGNN-MB employs a novel Historical Embedding Cache combined with compute-communication overlap to address this challenge. On a 32-node (64-socket) cluster of $3^{rd}$ generation Intel Xeon Scalable Processors with 36 cores per socket, DistGNN-MB trains 3-layer GraphSAGE and GAT models on OGBN-Papers100M to convergence with epoch times of 2 seconds and 4.9 seconds, respectively, on 32 compute nodes. At this scale, DistGNN-MB trains GraphSAGE 5.2x faster than the widely-used DistDGL. DistGNN-MB trains GraphSAGE and GAT 10x and 17.2x faster, respectively, as compute nodes scale from 2 to 32.
DistGNN: Scalable Distributed Training for Large-Scale Graph Neural Networks
Apr 16, 2021
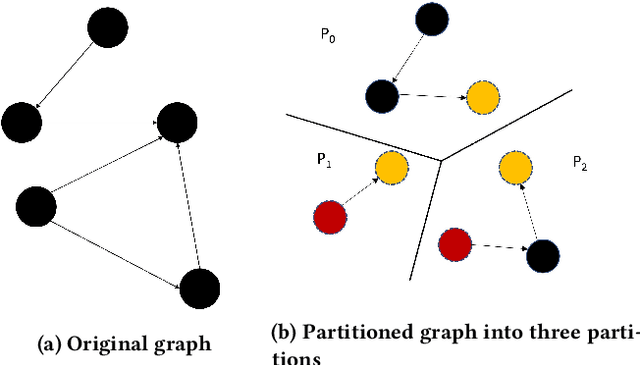
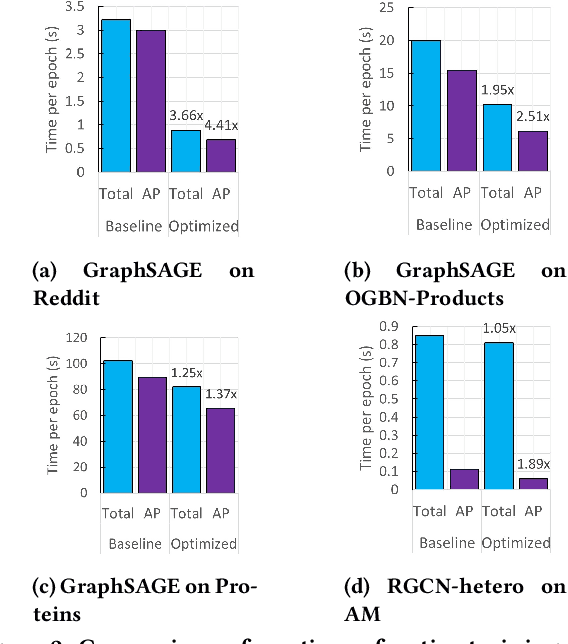
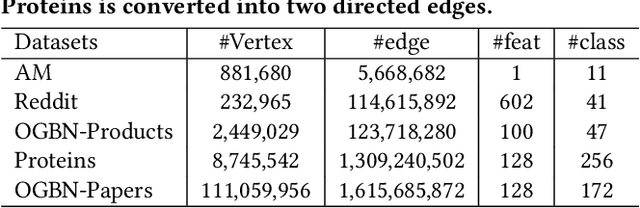
Full-batch training on Graph Neural Networks (GNN) to learn the structure of large graphs is a critical problem that needs to scale to hundreds of compute nodes to be feasible. It is challenging due to large memory capacity and bandwidth requirements on a single compute node and high communication volumes across multiple nodes. In this paper, we present DistGNN that optimizes the well-known Deep Graph Library (DGL) for full-batch training on CPU clusters via an efficient shared memory implementation, communication reduction using a minimum vertex-cut graph partitioning algorithm and communication avoidance using a family of delayed-update algorithms. Our results on four common GNN benchmark datasets: Reddit, OGB-Products, OGB-Papers and Proteins, show up to 3.7x speed-up using a single CPU socket and up to 97x speed-up using 128 CPU sockets, respectively, over baseline DGL implementations running on a single CPU socket
Tensor Processing Primitives: A Programming Abstraction for Efficiency and Portability in Deep Learning Workloads
Apr 14, 2021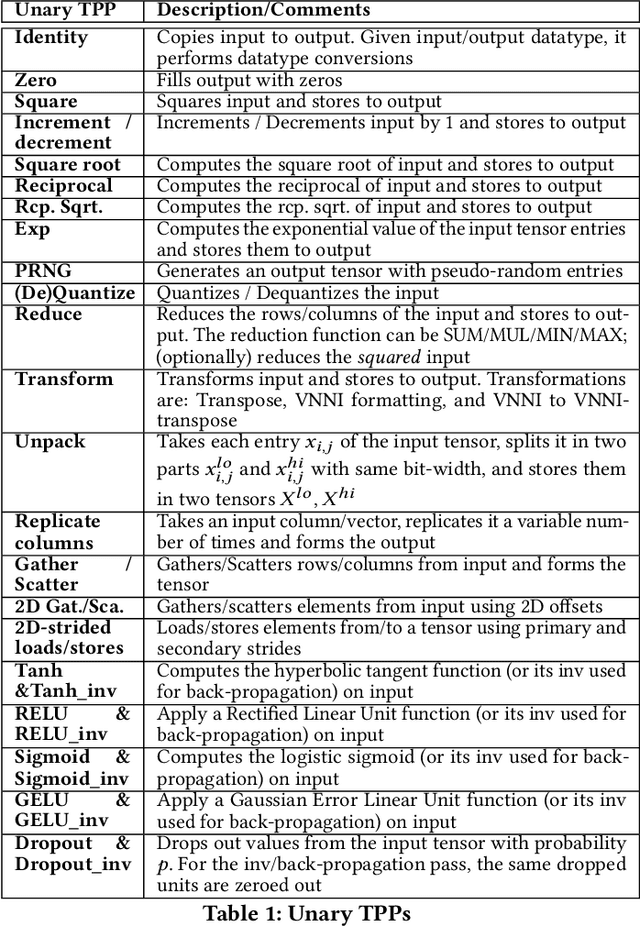
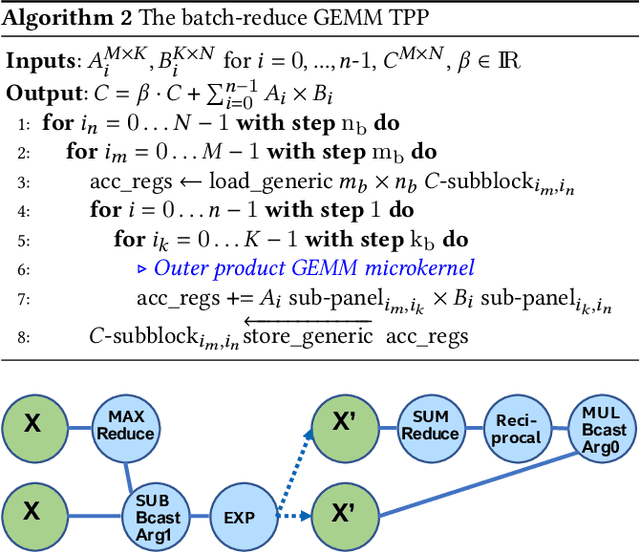
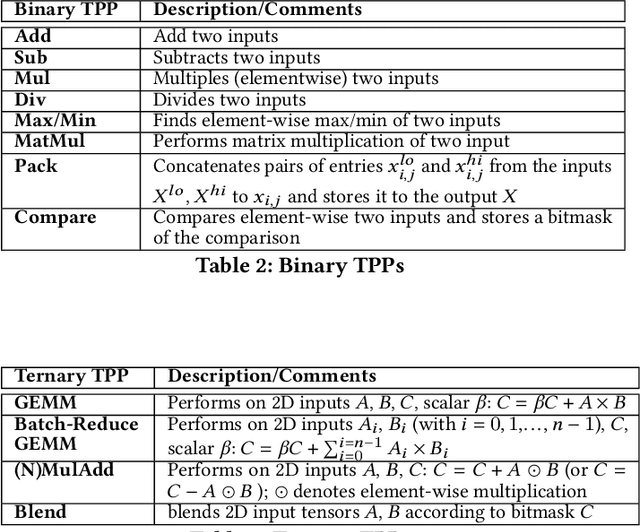
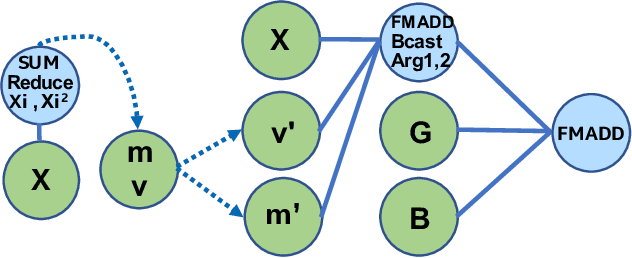
During the past decade, novel Deep Learning (DL) algorithms/workloads and hardware have been developed to tackle a wide range of problems. Despite the advances in workload/hardware ecosystems, the programming methodology of DL-systems is stagnant. DL-workloads leverage either highly-optimized, yet platform-specific and inflexible kernels from DL-libraries, or in the case of novel operators, reference implementations are built via DL-framework primitives with underwhelming performance. This work introduces the Tensor Processing Primitives (TPP), a programming abstraction striving for efficient, portable implementation of DL-workloads with high-productivity. TPPs define a compact, yet versatile set of 2D-tensor operators (or a virtual Tensor ISA), which subsequently can be utilized as building-blocks to construct complex operators on high-dimensional tensors. The TPP specification is platform-agnostic, thus code expressed via TPPs is portable, whereas the TPP implementation is highly-optimized and platform-specific. We demonstrate the efficacy of our approach using standalone kernels and end-to-end DL-workloads expressed entirely via TPPs that outperform state-of-the-art implementations on multiple platforms.
Deep Graph Library Optimizations for Intel(R) x86 Architecture
Jul 13, 2020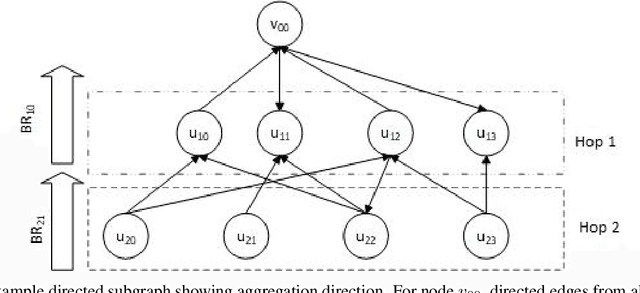
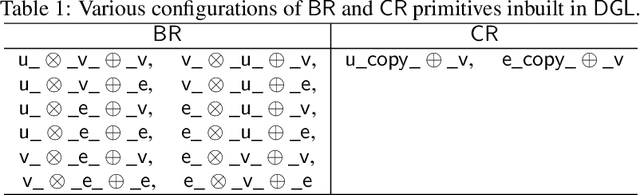
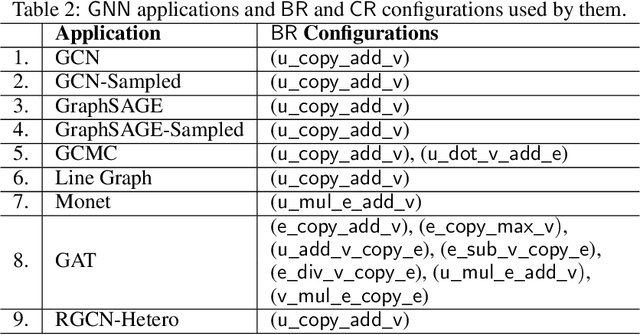
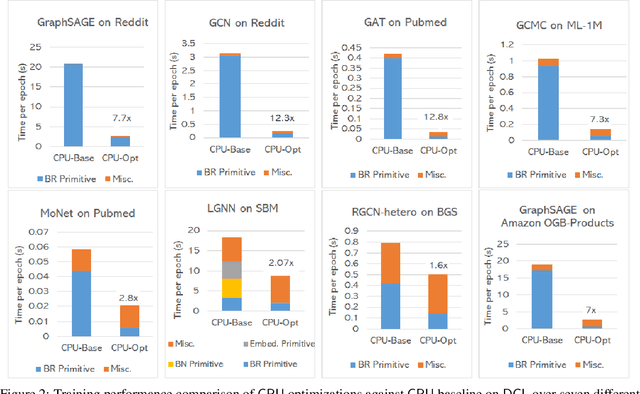
The Deep Graph Library (DGL) was designed as a tool to enable structure learning from graphs, by supporting a core abstraction for graphs, including the popular Graph Neural Networks (GNN). DGL contains implementations of all core graph operations for both the CPU and GPU. In this paper, we focus specifically on CPU implementations and present performance analysis, optimizations and results across a set of GNN applications using the latest version of DGL(0.4.3). Across 7 applications, we achieve speed-ups ranging from1 1.5x-13x over the baseline CPU implementations.
Hardware Acceleration of Sparse and Irregular Tensor Computations of ML Models: A Survey and Insights
Jul 02, 2020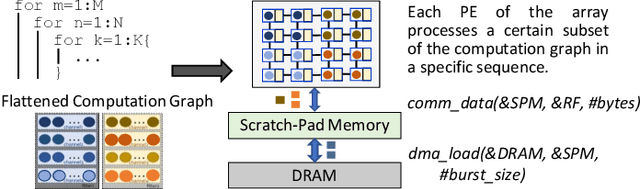


Machine learning (ML) models are widely used in many domains including media processing and generation, computer vision, medical diagnosis, embedded systems, high-performance and scientific computing, and recommendation systems. For efficiently processing these computational- and memory-intensive applications, tensors of these over-parameterized models are compressed by leveraging sparsity, size reduction, and quantization of tensors. Unstructured sparsity and tensors with varying dimensions yield irregular-shaped computation, communication, and memory access patterns; processing them on hardware accelerators in a conventional manner does not inherently leverage acceleration opportunities. This paper provides a comprehensive survey on how to efficiently execute sparse and irregular tensor computations of ML models on hardware accelerators. In particular, it discusses additional enhancement modules in architecture design and software support; categorizes different hardware designs and acceleration techniques and analyzes them in terms of hardware and execution costs; highlights further opportunities in terms of hardware/software/algorithm co-design optimizations and joint optimizations among described hardware and software enhancement modules. The takeaways from this paper include: understanding the key challenges in accelerating sparse, irregular-shaped, and quantized tensors; understanding enhancements in acceleration systems for supporting their efficient computations; analyzing trade-offs in opting for a specific type of design enhancement; understanding how to map and compile models with sparse tensors on the accelerators; understanding recent design trends for efficient accelerations and further opportunities.
PolyDL: Polyhedral Optimizations for Creation of High Performance DL primitives
Jun 02, 2020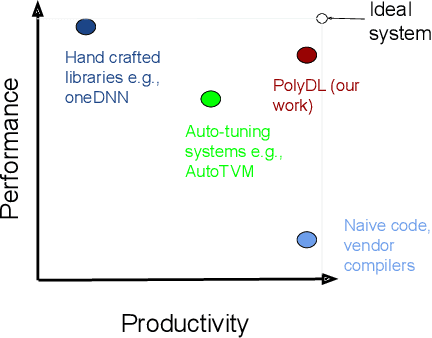
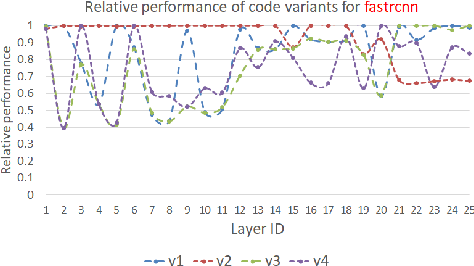
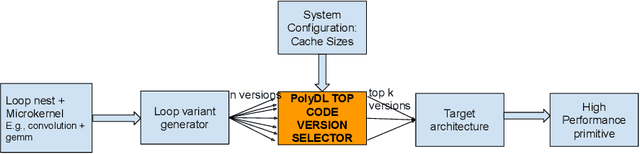

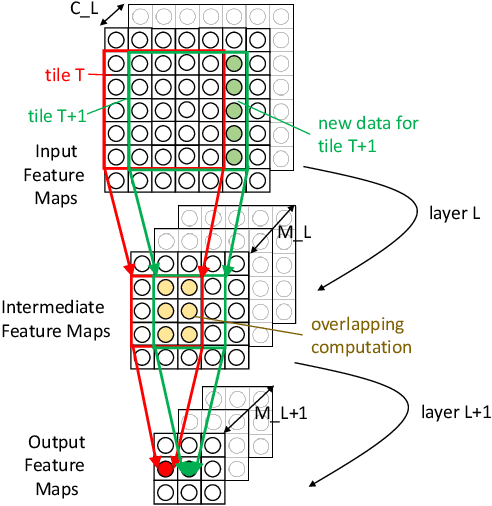
Deep Neural Networks (DNNs) have revolutionized many aspects of our lives. The use of DNNs is becoming ubiquitous including in softwares for image recognition, speech recognition, speech synthesis, language translation, to name a few. he training of DNN architectures however is computationally expensive. Once the model is created, its use in the intended application - the inference task, is computationally heavy too and the inference needs to be fast for real time use. For obtaining high performance today, the code of Deep Learning (DL) primitives optimized for specific architectures by expert programmers exposed via libraries is the norm. However, given the constant emergence of new DNN architectures, creating hand optimized code is expensive, slow and is not scalable. To address this performance-productivity challenge, in this paper we present compiler algorithms to automatically generate high performance implementations of DL primitives that closely match the performance of hand optimized libraries. We develop novel data reuse analysis algorithms using the polyhedral model to derive efficient execution schedules automatically. In addition, because most DL primitives use some variant of matrix multiplication at their core, we develop a flexible framework where it is possible to plug in library implementations of the same in lieu of a subset of the loops. We show that such a hybrid compiler plus a minimal library-use approach results in state-of-the-art performance. We develop compiler algorithms to also perform operator fusions that reduce data movement through the memory hierarchy of the computer system.
PolyScientist: Automatic Loop Transformations Combined with Microkernels for Optimization of Deep Learning Primitives
Feb 06, 2020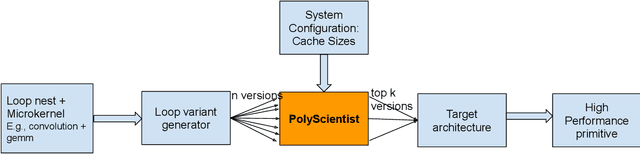
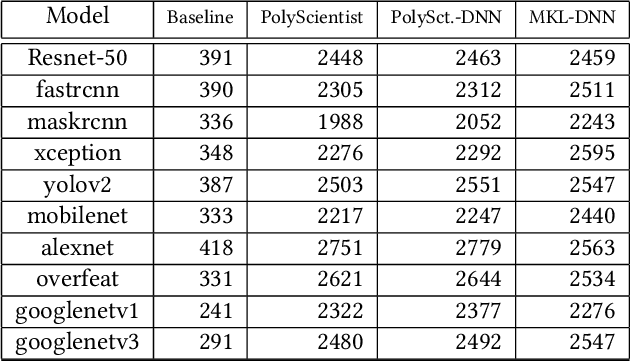
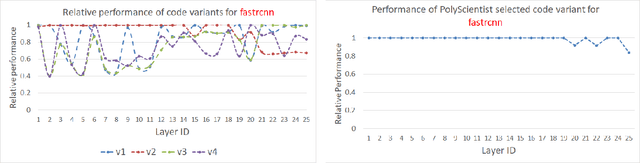

At the heart of deep learning training and inferencing are computationally intensive primitives such as convolutions which form the building blocks of deep neural networks. Researchers have taken two distinct approaches to creating high performance implementations of deep learning kernels, namely, 1) library development exemplified by Intel MKL-DNN for CPUs, 2) automatic compilation represented by the TensorFlow XLA compiler. The two approaches have their drawbacks: even though a custom built library can deliver very good performance, the cost and time of development of the library can be high. Automatic compilation of kernels is attractive but in practice, till date, automatically generated implementations lag expert coded kernels in performance by orders of magnitude. In this paper, we develop a hybrid solution to the development of deep learning kernels that achieves the best of both worlds: the expert coded microkernels are utilized for the innermost loops of kernels and we use the advanced polyhedral technology to automatically tune the outer loops for performance. We design a novel polyhedral model based data reuse algorithm to optimize the outer loops of the kernel. Through experimental evaluation on an important class of deep learning primitives namely convolutions, we demonstrate that the approach we develop attains the same levels of performance as Intel MKL-DNN, a hand coded deep learning library.
SEERL: Sample Efficient Ensemble Reinforcement Learning
Jan 15, 2020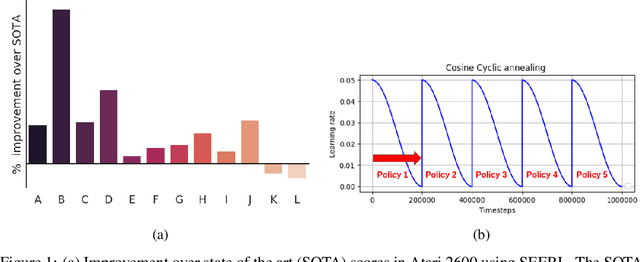
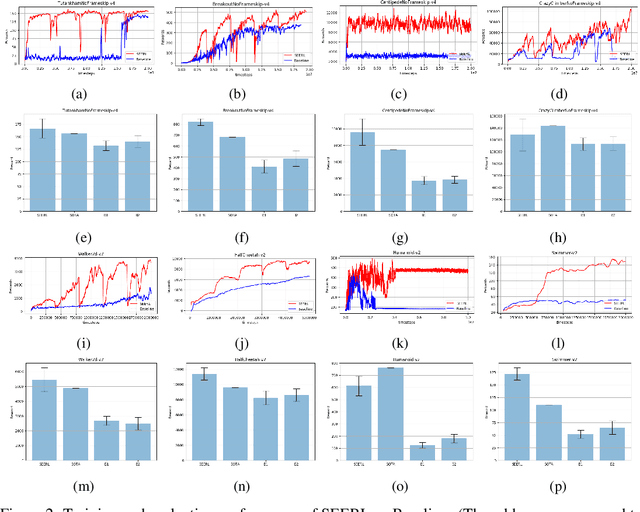
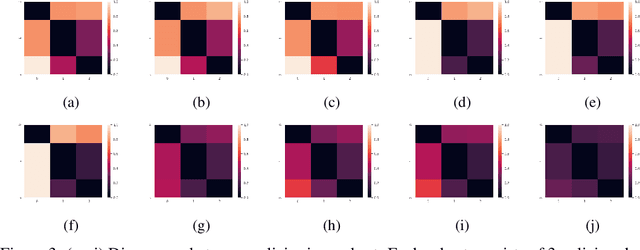
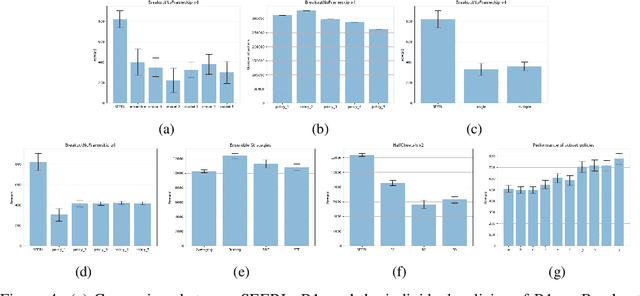
Ensemble learning is a very prevalent method employed in machine learning. The relative success of ensemble methods is attributed to its ability to tackle a wide range of instances and complex problems that require different low-level approaches. However, ensemble methods are relatively less popular in reinforcement learning owing to the high sample complexity and computational expense involved. We present a new training and evaluation framework for model-free algorithms that use ensembles of policies obtained from a single training instance. These policies are diverse in nature and are learned through directed perturbation of the model parameters at regular intervals. We show that learning an adequately diverse set of policies is required for a good ensemble while extreme diversity can prove detrimental to overall performance. We evaluate our approach to challenging discrete and continuous control tasks and also discuss various ensembling strategies. Our framework is substantially sample efficient, computationally inexpensive and is seen to outperform state of the art(SOTA) scores in Atari 2600 and Mujoco. Video results can be found at https://www.youtube.com/channel/UC95Kctu9Mp8BlFmtGD2TGTA
High Performance Scalable FPGA Accelerator for Deep Neural Networks
Aug 29, 2019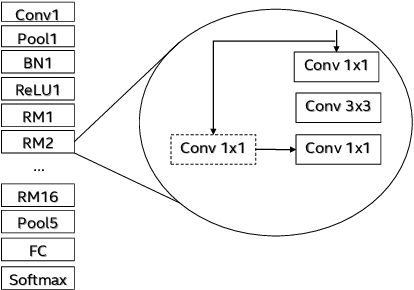
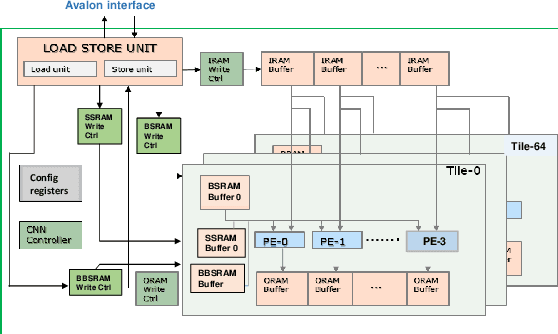
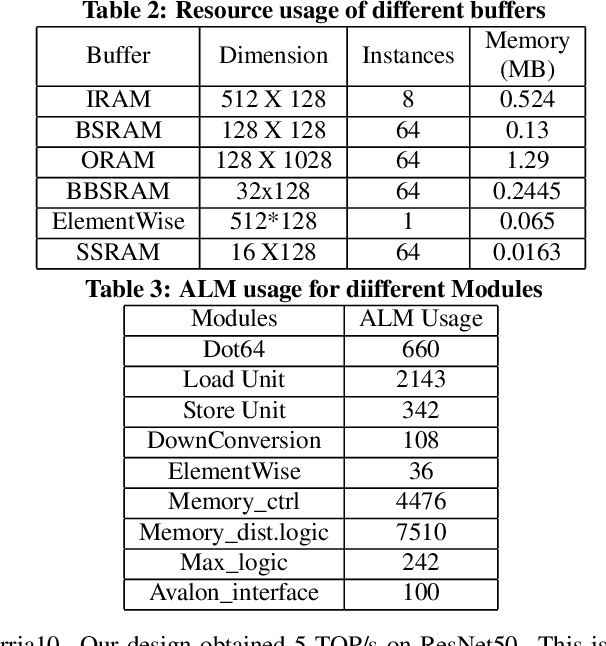
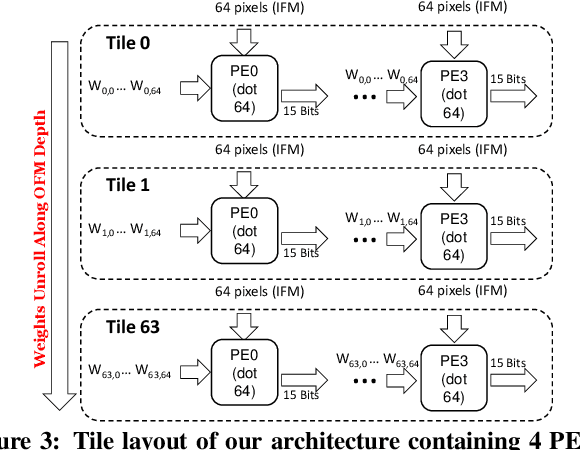
Low-precision is the first order knob for achieving higher Artificial Intelligence Operations (AI-TOPS). However the algorithmic space for sub-8-bit precision compute is diverse, with disruptive changes happening frequently, making FPGAs a natural choice for Deep Neural Network inference, In this work we present an FPGA-based accelerator for CNN inference acceleration. We use {\it INT-8-2} compute (with {\it 8 bit} activation and {2 bit} weights) which is recently showing promise in the literature, and which no known ASIC, CPU or GPU natively supports today. Using a novel Adaptive Logic Module (ALM) based design, as a departure from traditional DSP based designs, we are able to achieve high performance measurement of 5 AI-TOPS for {\it Arria10} and project a performance of 76 AI-TOPS at 0.7 TOPS/W for {\it Stratix10}. This exceeds known CPU, GPU performance and comes close to best known ASIC (TPU) numbers, while retaining the versatility of the FPGA platform for other applications.