 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Adaptive Optimization with Delayed Preconditioners
Dec 01, 2022Privacy noise may negate the benefits of using adaptive optimizers in differentially private model training. Prior works typically address this issue by using auxiliary information (e.g., public data) to boost the effectiveness of adaptive optimization. In this work, we explore techniques to estimate and efficiently adapt to gradient geometry in private adaptive optimization without auxiliary data. Motivated by the observation that adaptive methods can tolerate stale preconditioners, we propose differentially private adaptive training with delayed preconditioners (DP^2), a simple method that constructs delayed but less noisy preconditioners to better realize the benefits of adaptivity. Theoretically, we provide convergence guarantees for our method for both convex and non-convex problems, and analyze trade-offs between delay and privacy noise reduction. Empirically, we explore DP^2 across several real-world datasets, demonstrating that it can improve convergence speed by as much as 4x relative to non-adaptive baselines and match the performance of state-of-the-art optimization methods that require auxiliary data.
On the Algorithmic Stability and Generalization of Adaptive Optimization Methods
Nov 08, 2022



Despite their popularity in deep learning and machine learning in general, the theoretical properties of adaptive optimizers such as Adagrad, RMSProp, Adam or AdamW are not yet fully understood. In this paper, we develop a novel framework to study the stability and generalization of these optimization methods. Based on this framework, we show provable guarantees about such properties that depend heavily on a single parameter $\beta_2$. Our empirical experiments support our claims and provide practical insights into the stability and generalization properties of adaptive optimization methods.
Large Models are Parsimonious Learners: Activation Sparsity in Trained Transformers
Oct 12, 2022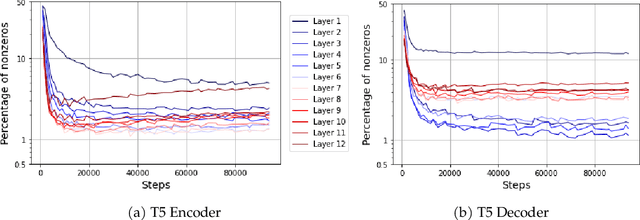

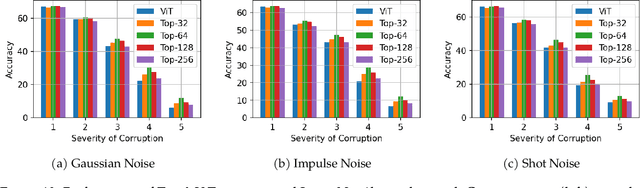
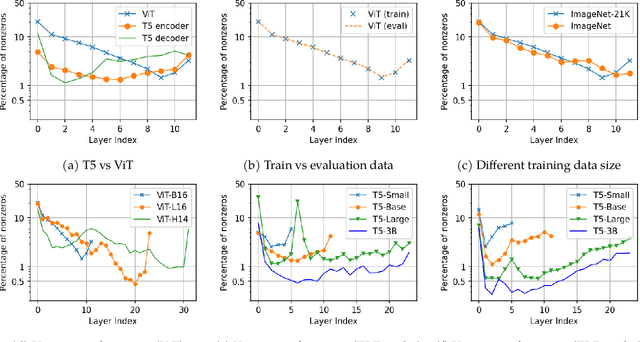
This paper studies the curious phenomenon for machine learning models with Transformer architectures that their activation maps are sparse. By activation map we refer to the intermediate output of the multi-layer perceptrons (MLPs) after a ReLU activation function, and by "sparse" we mean that on average very few entries (e.g., 3.0% for T5-Base and 6.3% for ViT-B16) are nonzero for each input to MLP. Moreover, larger Transformers with more layers and wider MLP hidden dimensions are sparser as measured by the percentage of nonzero entries. Through extensive experiments we demonstrate that the emergence of sparsity is a prevalent phenomenon that occurs for both natural language processing and vision tasks, on both training and evaluation data, for Transformers of various configurations, at layers of all depth levels, as well as for other architectures including MLP-mixers and 2-layer MLPs. We show that sparsity also emerges using training datasets with random labels, or with random inputs, or with infinite amount of data, demonstrating that sparsity is not a result of a specific family of datasets. We discuss how sparsity immediately implies a way to significantly reduce the FLOP count and improve efficiency for Transformers. Moreover, we demonstrate perhaps surprisingly that enforcing an even sparser activation via Top-k thresholding with a small value of k brings a collection of desired but missing properties for Transformers, namely less sensitivity to noisy training data, more robustness to input corruptions, and better calibration for their prediction confidence.
Private Adaptive Optimization with Side Information
Feb 12, 2022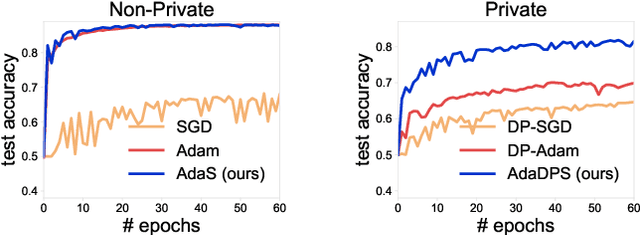

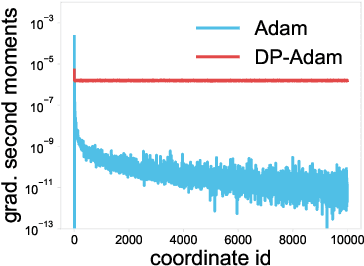
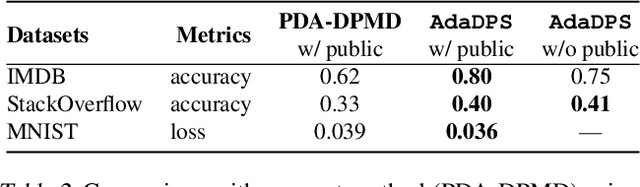
Adaptive optimization methods have become the default solvers for many machine learning tasks. Unfortunately, the benefits of adaptivity may degrade when training with differential privacy, as the noise added to ensure privacy reduces the effectiveness of the adaptive preconditioner. To this end, we propose AdaDPS, a general framework that uses non-sensitive side information to precondition the gradients, allowing the effective use of adaptive methods in private settings. We formally show AdaDPS reduces the amount of noise needed to achieve similar privacy guarantees, thereby improving optimization performance. Empirically, we leverage simple and readily available side information to explore the performance of AdaDPS in practice, comparing to strong baselines in both centralized and federated settings. Our results show that AdaDPS improves accuracy by 7.7% (absolute) on average -- yielding state-of-the-art privacy-utility trade-offs on large-scale text and image benchmarks.
Robust Training of Neural Networks using Scale Invariant Architectures
Feb 02, 2022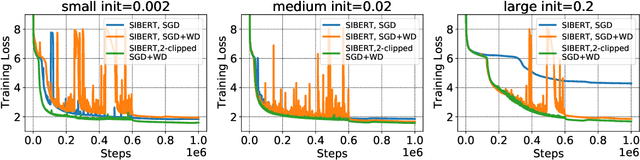
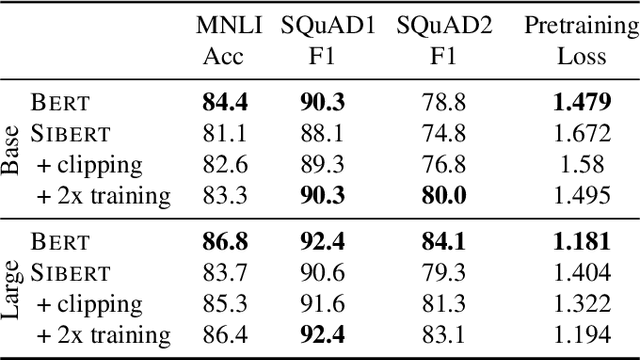
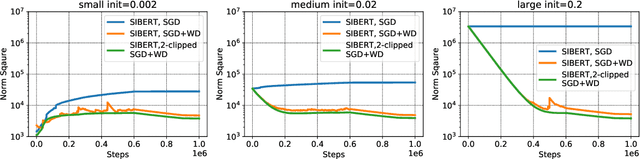

In contrast to SGD, adaptive gradient methods like Adam allow robust training of modern deep networks, especially large language models. However, the use of adaptivity not only comes at the cost of extra memory but also raises the fundamental question: can non-adaptive methods like SGD enjoy similar benefits? In this paper, we provide an affirmative answer to this question by proposing to achieve both robust and memory-efficient training via the following general recipe: (1) modify the architecture and make it scale invariant, i.e. the scale of parameter doesn't affect the output of the network, (2) train with SGD and weight decay, and optionally (3) clip the global gradient norm proportional to weight norm multiplied by $\sqrt{\tfrac{2\lambda}{\eta}}$, where $\eta$ is learning rate and $\lambda$ is weight decay. We show that this general approach is robust to rescaling of parameter and loss by proving that its convergence only depends logarithmically on the scale of initialization and loss, whereas the standard SGD might not even converge for many initializations. Following our recipe, we design a scale invariant version of BERT, called SIBERT, which when trained simply by vanilla SGD achieves performance comparable to BERT trained by adaptive methods like Adam on downstream tasks.
A Field Guide to Federated Optimization
Jul 14, 2021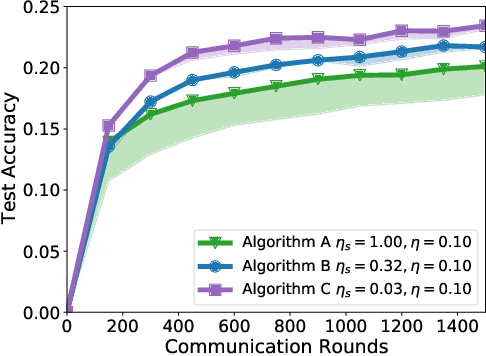


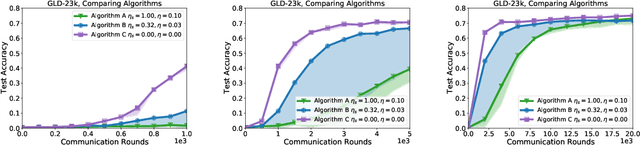
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Distilling Double Descent
Feb 13, 2021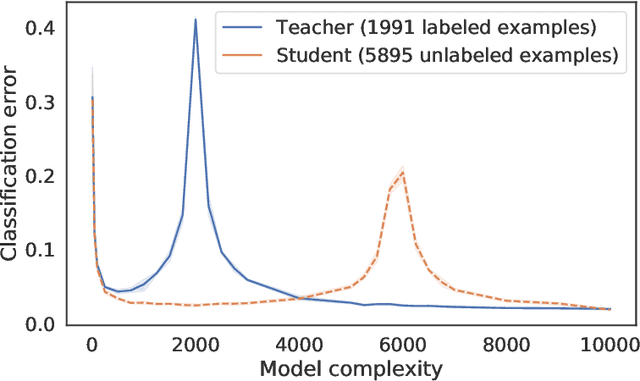
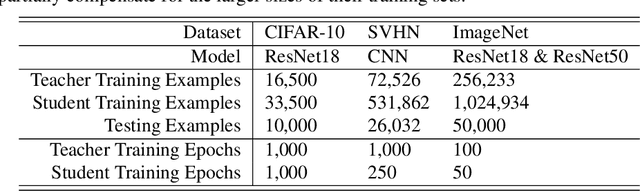
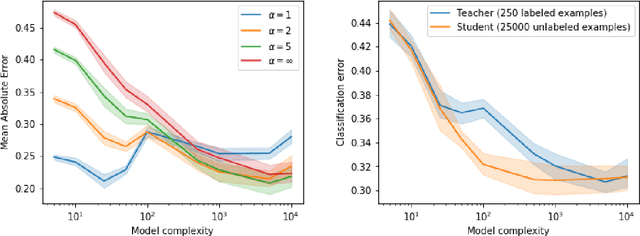
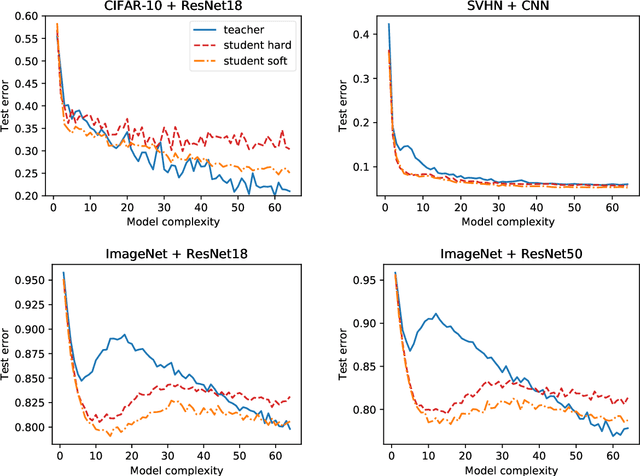
Distillation is the technique of training a "student" model based on examples that are labeled by a separate "teacher" model, which itself is trained on a labeled dataset. The most common explanations for why distillation "works" are predicated on the assumption that student is provided with \emph{soft} labels, \eg probabilities or confidences, from the teacher model. In this work, we show, that, even when the teacher model is highly overparameterized, and provides \emph{hard} labels, using a very large held-out unlabeled dataset to train the student model can result in a model that outperforms more "traditional" approaches. Our explanation for this phenomenon is based on recent work on "double descent". It has been observed that, once a model's complexity roughly exceeds the amount required to memorize the training data, increasing the complexity \emph{further} can, counterintuitively, result in \emph{better} generalization. Researchers have identified several settings in which it takes place, while others have made various attempts to explain it (thus far, with only partial success). In contrast, we avoid these questions, and instead seek to \emph{exploit} this phenomenon by demonstrating that a highly-overparameterized teacher can avoid overfitting via double descent, while a student trained on a larger independent dataset labeled by this teacher will avoid overfitting due to the size of its training set.
Mime: Mimicking Centralized Stochastic Algorithms in Federated Learning
Aug 08, 2020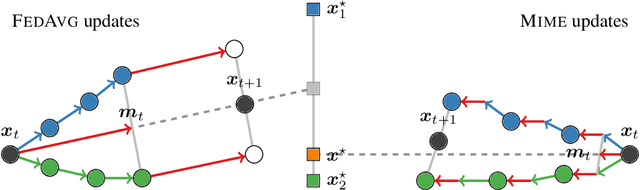

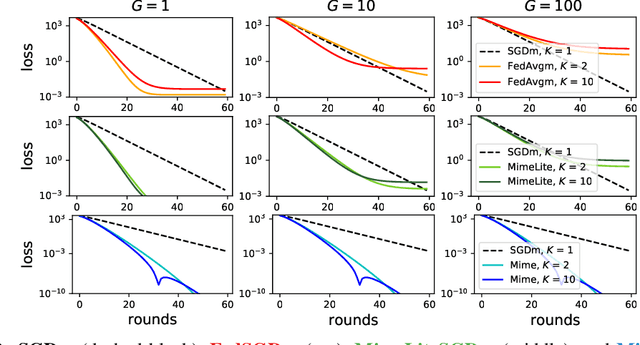

Federated learning is a challenging optimization problem due to the heterogeneity of the data across different clients. Such heterogeneity has been observed to induce client drift and significantly degrade the performance of algorithms designed for this setting. In contrast, centralized learning with centrally collected data does not experience such drift, and has seen great empirical and theoretical progress with innovations such as momentum, adaptivity, etc. In this work, we propose a general framework Mime which mitigates client-drift and adapts arbitrary centralized optimization algorithms (e.g.\ SGD, Adam, etc.) to federated learning. Mime uses a combination of control-variates and server-level statistics (e.g. momentum) at every client-update step to ensure that each local update mimics that of the centralized method. Our thorough theoretical and empirical analyses strongly establish Mime's superiority over other baselines.
$O(n)$ Connections are Expressive Enough: Universal Approximability of Sparse Transformers
Jun 08, 2020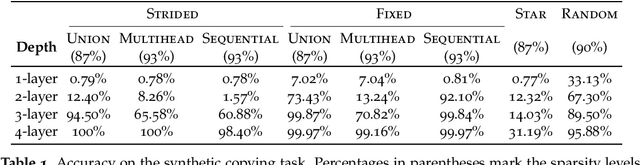
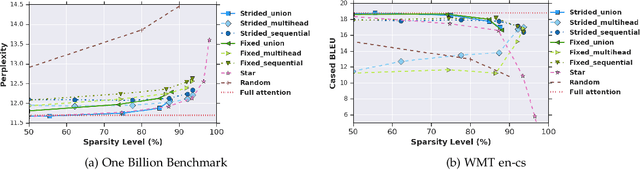
Transformer networks use pairwise attention to compute contextual embeddings of inputs, and have redefined the state of the art in many NLP tasks. However, these models suffer from quadratic computational cost in the input sequence length $n$ to compute attention in each layer. This has prompted recent research into faster attention models, with a predominant approach involving sparsifying the connections in the attention layers. While empirically promising for long sequences, fundamental questions remain unanswered: Can sparse transformers approximate any arbitrary sequence-to-sequence function, similar to their dense counterparts? How does the sparsity pattern and the sparsity level affect their performance? In this paper, we address these questions and provide a unifying framework that captures existing sparse attention models. Our analysis proposes sufficient conditions under which we prove that a sparse attention model can universally approximate any sequence-to-sequence function. Surprisingly, our results show the existence of models with only $O(n)$ connections per attention layer that can approximate the same function class as the dense model with $n^2$ connections. Lastly, we present experiments comparing different patterns/levels of sparsity on standard NLP tasks.
Why distillation helps: a statistical perspective
May 21, 2020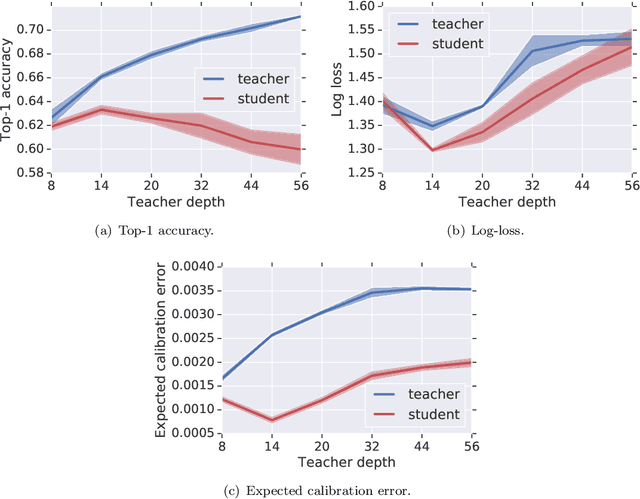
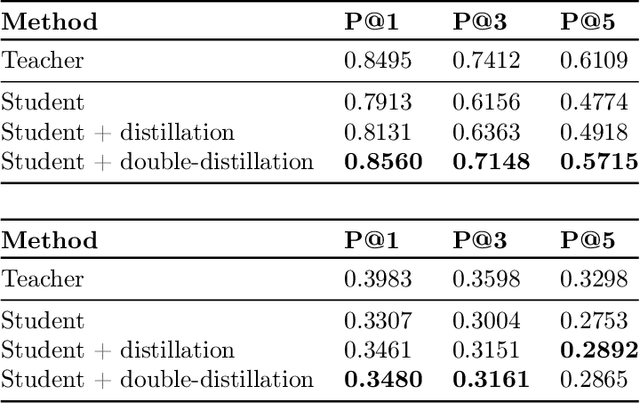
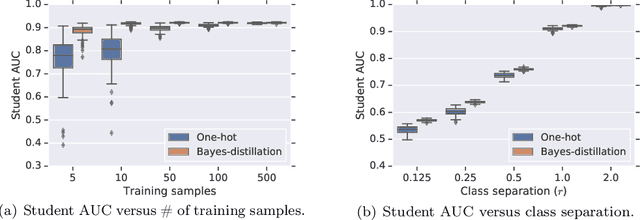
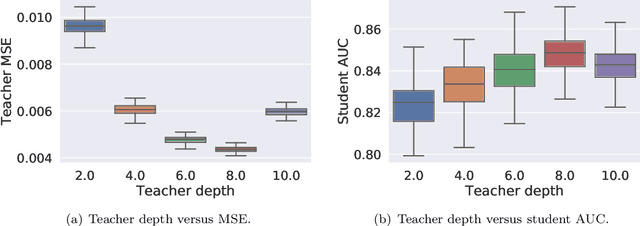
Knowledge distillation is a technique for improving the performance of a simple "student" model by replacing its one-hot training labels with a distribution over labels obtained from a complex "teacher" model. While this simple approach has proven widely effective, a basic question remains unresolved: why does distillation help? In this paper, we present a statistical perspective on distillation which addresses this question, and provides a novel connection to extreme multiclass retrieval techniques. Our core observation is that the teacher seeks to estimate the underlying (Bayes) class-probability function. Building on this, we establish a fundamental bias-variance tradeoff in the student's objective: this quantifies how approximate knowledge of these class-probabilities can significantly aid learning. Finally, we show how distillation complements existing negative mining techniques for extreme multiclass retrieval, and propose a unified objective which combines these ideas.