 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Influence Function
Jul 17, 2020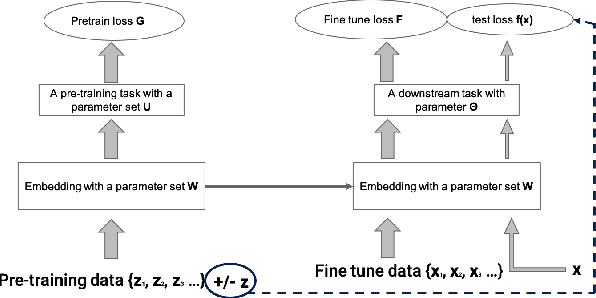
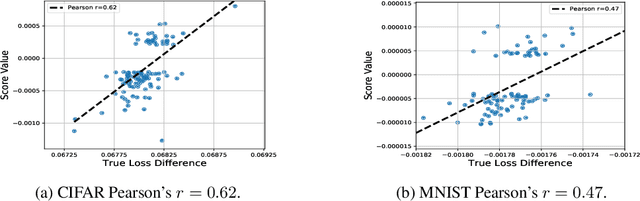

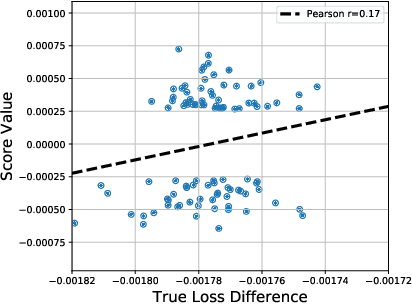
Multi-stage training and knowledge transfer, from a large-scale pretraining task to various finetuning tasks, have revolutionized natural language processing and computer vision resulting in state-of-the-art performance improvements. In this paper, we develop a multi-stage influence function score to track predictions from a finetuned model all the way back to the pretraining data. With this score, we can identify the pretraining examples in the pretraining task that contribute most to a prediction in the finetuning task. The proposed multi-stage influence function generalizes the original influence function for a single model in (Koh & Liang, 2017), thereby enabling influence computation through both pretrained and finetuned models. We study two different scenarios with the pretrained embeddings fixed or updated in the finetuning tasks. We test our proposed method in various experiments to show its effectiveness and potential applications.
Long-tail learning via logit adjustment
Jul 14, 2020
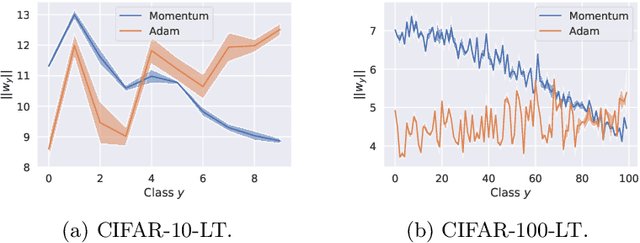
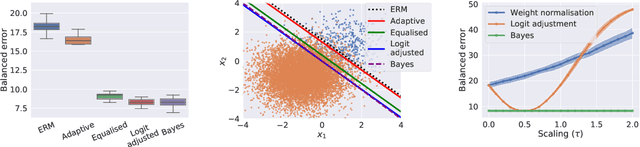
Real-world classification problems typically exhibit an imbalanced or long-tailed label distribution, wherein many labels are associated with only a few samples. This poses a challenge for generalisation on such labels, and also makes na\"ive learning biased towards dominant labels. In this paper, we present two simple modifications of standard softmax cross-entropy training to cope with these challenges. Our techniques revisit the classic idea of logit adjustment based on the label frequencies, either applied post-hoc to a trained model, or enforced in the loss during training. Such adjustment encourages a large relative margin between logits of rare versus dominant labels. These techniques unify and generalise several recent proposals in the literature, while possessing firmer statistical grounding and empirical performance.
$O(n)$ Connections are Expressive Enough: Universal Approximability of Sparse Transformers
Jun 08, 2020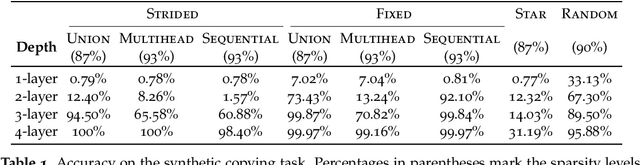
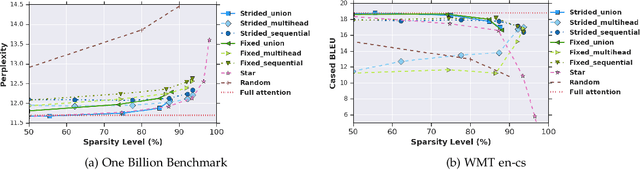
Transformer networks use pairwise attention to compute contextual embeddings of inputs, and have redefined the state of the art in many NLP tasks. However, these models suffer from quadratic computational cost in the input sequence length $n$ to compute attention in each layer. This has prompted recent research into faster attention models, with a predominant approach involving sparsifying the connections in the attention layers. While empirically promising for long sequences, fundamental questions remain unanswered: Can sparse transformers approximate any arbitrary sequence-to-sequence function, similar to their dense counterparts? How does the sparsity pattern and the sparsity level affect their performance? In this paper, we address these questions and provide a unifying framework that captures existing sparse attention models. Our analysis proposes sufficient conditions under which we prove that a sparse attention model can universally approximate any sequence-to-sequence function. Surprisingly, our results show the existence of models with only $O(n)$ connections per attention layer that can approximate the same function class as the dense model with $n^2$ connections. Lastly, we present experiments comparing different patterns/levels of sparsity on standard NLP tasks.
Evaluations and Methods for Explanation through Robustness Analysis
May 31, 2020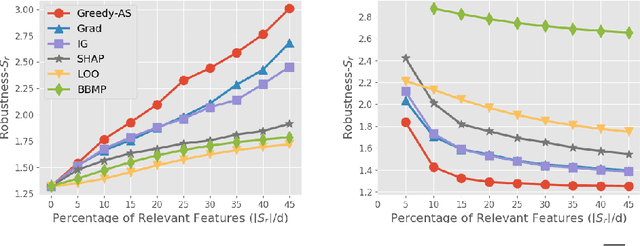


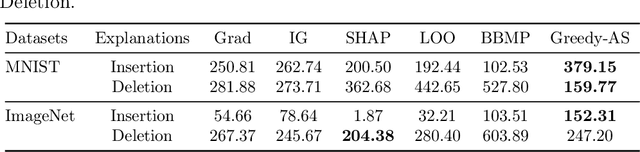
Among multiple ways of interpreting a machine learning model, measuring the importance of a set of features tied to a prediction is probably one of the most intuitive ways to explain a model. In this paper, we establish the link between a set of features to a prediction with a new evaluation criterion, robustness analysis, which measures the minimum distortion distance of adversarial perturbation. By measuring the tolerance level for an adversarial attack, we can extract a set of features that provides the most robust support for a prediction, and also can extract a set of features that contrasts the current prediction to a target class by setting a targeted adversarial attack. By applying this methodology to various prediction tasks across multiple domains, we observe the derived explanations are indeed capturing the significant feature set qualitatively and quantitatively.
Why distillation helps: a statistical perspective
May 21, 2020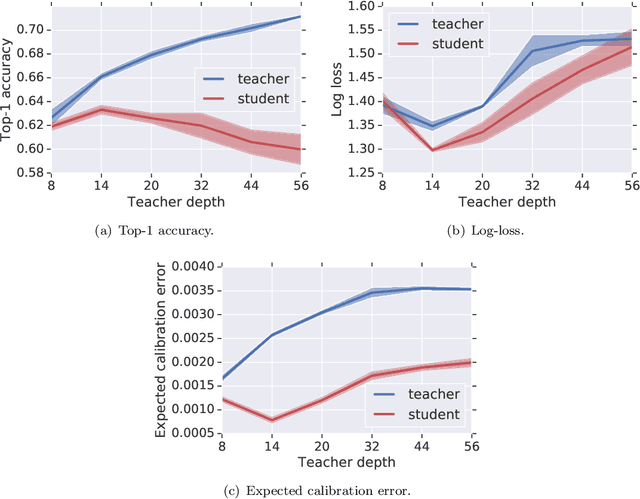
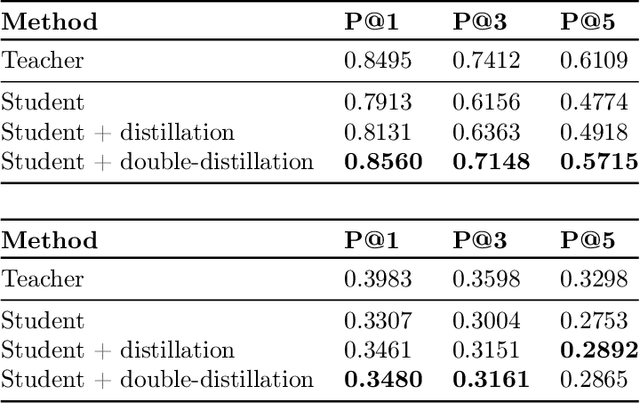
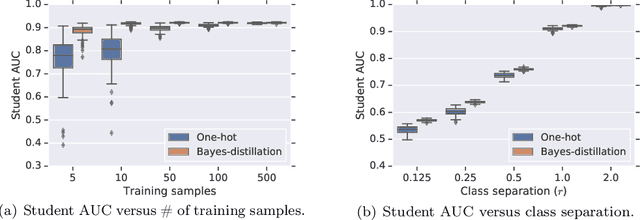
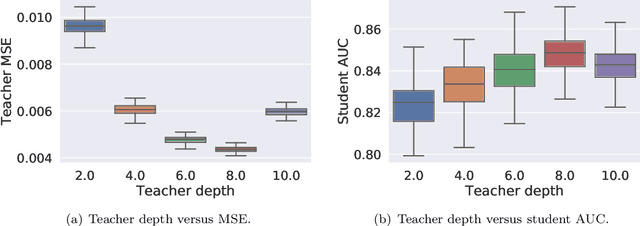
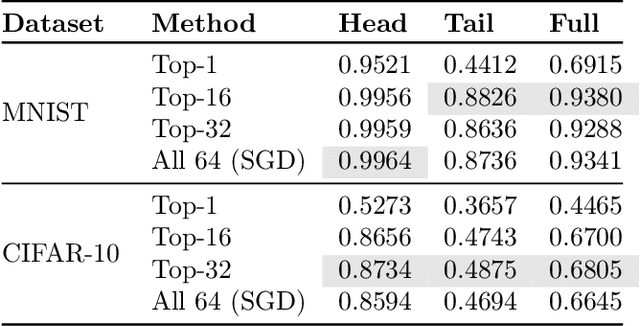
Knowledge distillation is a technique for improving the performance of a simple "student" model by replacing its one-hot training labels with a distribution over labels obtained from a complex "teacher" model. While this simple approach has proven widely effective, a basic question remains unresolved: why does distillation help? In this paper, we present a statistical perspective on distillation which addresses this question, and provides a novel connection to extreme multiclass retrieval techniques. Our core observation is that the teacher seeks to estimate the underlying (Bayes) class-probability function. Building on this, we establish a fundamental bias-variance tradeoff in the student's objective: this quantifies how approximate knowledge of these class-probabilities can significantly aid learning. Finally, we show how distillation complements existing negative mining techniques for extreme multiclass retrieval, and propose a unified objective which combines these ideas.
Doubly-stochastic mining for heterogeneous retrieval
Apr 23, 2020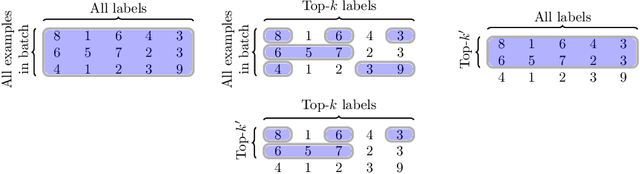


Modern retrieval problems are characterised by training sets with potentially billions of labels, and heterogeneous data distributions across subpopulations (e.g., users of a retrieval system may be from different countries), each of which poses a challenge. The first challenge concerns scalability: with a large number of labels, standard losses are difficult to optimise even on a single example. The second challenge concerns uniformity: one ideally wants good performance on each subpopulation. While several solutions have been proposed to address the first challenge, the second challenge has received relatively less attention. In this paper, we propose doubly-stochastic mining (S2M ), a stochastic optimization technique that addresses both challenges. In each iteration of S2M, we compute a per-example loss based on a subset of hardest labels, and then compute the minibatch loss based on the hardest examples. We show theoretically and empirically that by focusing on the hardest examples, S2M ensures that all data subpopulations are modelled well.
Federated Learning with Only Positive Labels
Apr 21, 2020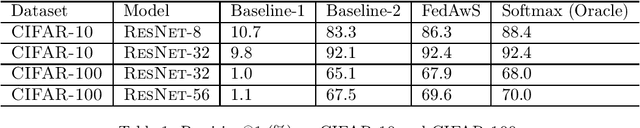

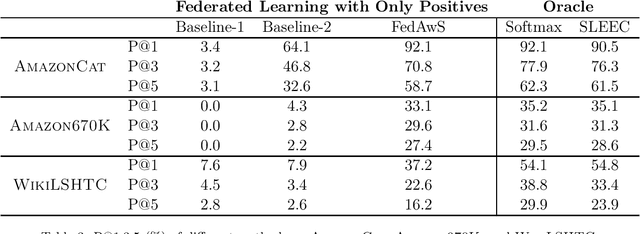

We consider learning a multi-class classification model in the federated setting, where each user has access to the positive data associated with only a single class. As a result, during each federated learning round, the users need to locally update the classifier without having access to the features and the model parameters for the negative classes. Thus, naively employing conventional decentralized learning such as the distributed SGD or Federated Averaging may lead to trivial or extremely poor classifiers. In particular, for the embedding based classifiers, all the class embeddings might collapse to a single point. To address this problem, we propose a generic framework for training with only positive labels, namely Federated Averaging with Spreadout (FedAwS), where the server imposes a geometric regularizer after each round to encourage classes to be spreadout in the embedding space. We show, both theoretically and empirically, that FedAwS can almost match the performance of conventional learning where users have access to negative labels. We further extend the proposed method to the settings with large output spaces.
Robust Large-Margin Learning in Hyperbolic Space
Apr 11, 2020

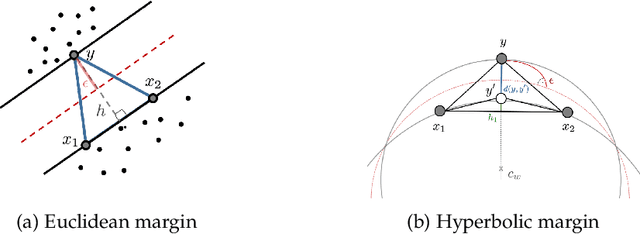

Recently, there has been a surge of interest in representation learning in hyperbolic spaces, driven by their ability to represent hierarchical data with significantly fewer dimensions than standard Euclidean spaces. However, the viability and benefits of hyperbolic spaces for downstream machine learning tasks have received less attention. In this paper, we present, to our knowledge, the first theoretical guarantees for learning a classifier in hyperbolic rather than Euclidean space. Specifically, we consider the problem of learning a large-margin classifier for data possessing a hierarchical structure. Our first contribution is a hyperbolic perceptron algorithm, which provably converges to a separating hyperplane. We then provide an algorithm to efficiently learn a large-margin hyperplane, relying on the careful injection of adversarial examples. Finally, we prove that for hierarchical data that embeds well into hyperbolic space, the low embedding dimension ensures superior guarantees when learning the classifier directly in hyperbolic space.
Does label smoothing mitigate label noise?
Mar 05, 2020
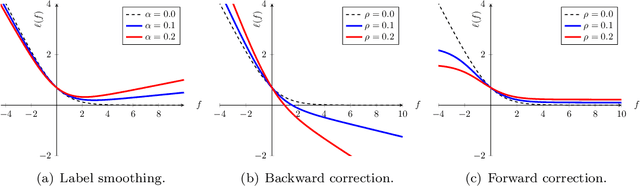
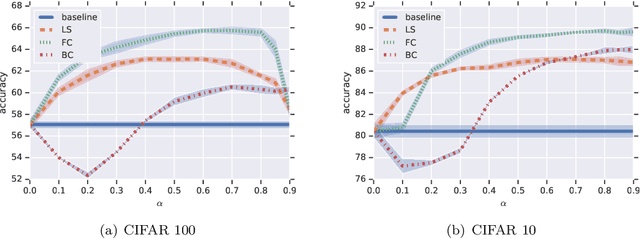

Label smoothing is commonly used in training deep learning models, wherein one-hot training labels are mixed with uniform label vectors. Empirically, smoothing has been shown to improve both predictive performance and model calibration. In this paper, we study whether label smoothing is also effective as a means of coping with label noise. While label smoothing apparently amplifies this problem --- being equivalent to injecting symmetric noise to the labels --- we show how it relates to a general family of loss-correction techniques from the label noise literature. Building on this connection, we show that label smoothing is competitive with loss-correction under label noise. Further, we show that when distilling models from noisy data, label smoothing of the teacher is beneficial; this is in contrast to recent findings for noise-free problems, and sheds further light on settings where label smoothing is beneficial.
Adaptive Federated Optimization
Feb 29, 2020
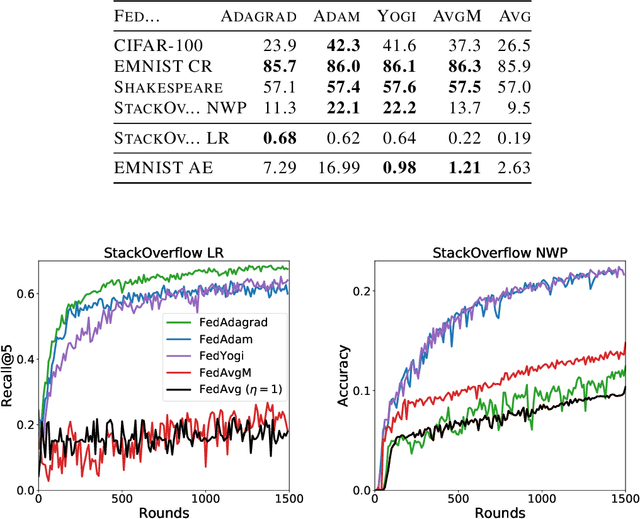
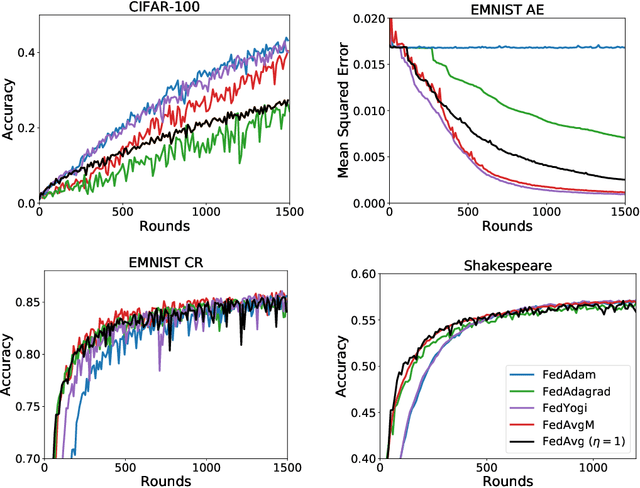
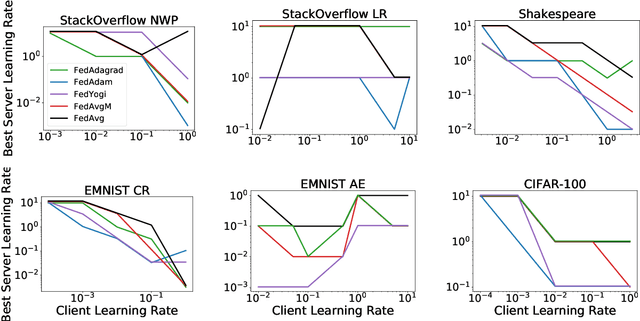
Federated learning is a distributed machine learning paradigm in which a large number of clients coordinate with a central server to learn a model without sharing their own training data. Due to the heterogeneity of the client datasets, standard federated optimization methods such as Federated Averaging (FedAvg) are often difficult to tune and exhibit unfavorable convergence behavior. In non-federated settings, adaptive optimization methods have had notable success in combating such issues. In this work, we propose federated versions of adaptive optimizers, including Adagrad, Adam, and Yogi, and analyze their convergence in the presence of heterogeneous data for general nonconvex settings. Our results highlight the interplay between client heterogeneity and communication efficiency. We also perform extensive experiments on these methods and show that the use of adaptive optimizers can significantly improve the performance of federated learning.