 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Prevent than Tackle: Valuing Defense in Soccer Based on Graph Neural Networks
Dec 11, 2025



Evaluating defensive performance in soccer remains challenging, as effective defending is often expressed not through visible on-ball actions such as interceptions and tackles, but through preventing dangerous opportunities before they arise. Existing approaches have largely focused on valuing on-ball actions, leaving much of defenders' true impact unmeasured. To address this gap, we propose DEFCON (DEFensive CONtribution evaluator), a comprehensive framework that quantifies player-level defensive contributions for every attacking situation in soccer. Leveraging Graph Attention Networks, DEFCON estimates the success probability and expected value of each attacking option, along with each defender's responsibility for stopping it. These components yield an Expected Possession Value (EPV) for the attacking team before and after each action, and DEFCON assigns positive or negative credits to defenders according to whether they reduced or increased the opponent's EPV. Trained on 2023-24 and evaluated on 2024-25 Eredivisie event and tracking data, DEFCON's aggregated player credits exhibit strong positive correlations with market valuations. Finally, we showcase several practical applications, including in-game timelines of defensive contributions, spatial analyses across pitch zones, and pairwise summaries of attacker-defender interactions.
Adaptive Graph Rewiring to Mitigate Over-Squashing in Mesh-Based GNNs for Fluid Dynamics Simulations
Nov 16, 2025Mesh-based simulation using Graph Neural Networks (GNNs) has been recognized as a promising approach for modeling fluid dynamics. However, the mesh refinement techniques which allocate finer resolution to regions with steep gradients can induce the over-squashing problem in mesh-based GNNs, which prevents the capture of long-range physical interactions. Conventional graph rewiring methods attempt to alleviate this issue by adding new edges, but they typically complete all rewiring operations before applying them to the GNN. These approaches are physically unrealistic, as they assume instantaneous interactions between distant nodes and disregard the distance information between particles. To address these limitations, we propose a novel framework, called Adaptive Graph Rewiring in Mesh-Based Graph Neural Networks (AdaMeshNet), that introduces an adaptive rewiring process into the message-passing procedure to model the gradual propagation of physical interactions. Our method computes a rewiring delay score for bottleneck nodes in the mesh graph, based on the shortest-path distance and the velocity difference. Using this score, it dynamically selects the message-passing layer at which new edges are rewired, which can lead to adaptive rewiring in a mesh graph. Extensive experiments on mesh-based fluid simulations demonstrate that AdaMeshNet outperforms conventional rewiring methods, effectively modeling the sequential nature of physical interactions and enabling more accurate predictions.
Self-Explainable Temporal Graph Networks based on Graph Information Bottleneck
Jun 19, 2024



Temporal Graph Neural Networks (TGNN) have the ability to capture both the graph topology and dynamic dependencies of interactions within a graph over time. There has been a growing need to explain the predictions of TGNN models due to the difficulty in identifying how past events influence their predictions. Since the explanation model for a static graph cannot be readily applied to temporal graphs due to its inability to capture temporal dependencies, recent studies proposed explanation models for temporal graphs. However, existing explanation models for temporal graphs rely on post-hoc explanations, requiring separate models for prediction and explanation, which is limited in two aspects: efficiency and accuracy of explanation. In this work, we propose a novel built-in explanation framework for temporal graphs, called Self-Explainable Temporal Graph Networks based on Graph Information Bottleneck (TGIB). TGIB provides explanations for event occurrences by introducing stochasticity in each temporal event based on the Information Bottleneck theory. Experimental results demonstrate the superiority of TGIB in terms of both the link prediction performance and explainability compared to state-of-the-art methods. This is the first work that simultaneously performs prediction and explanation for temporal graphs in an end-to-end manner.
Interpretable Prototype-based Graph Information Bottleneck
Oct 30, 2023The success of Graph Neural Networks (GNNs) has led to a need for understanding their decision-making process and providing explanations for their predictions, which has given rise to explainable AI (XAI) that offers transparent explanations for black-box models. Recently, the use of prototypes has successfully improved the explainability of models by learning prototypes to imply training graphs that affect the prediction. However, these approaches tend to provide prototypes with excessive information from the entire graph, leading to the exclusion of key substructures or the inclusion of irrelevant substructures, which can limit both the interpretability and the performance of the model in downstream tasks. In this work, we propose a novel framework of explainable GNNs, called interpretable Prototype-based Graph Information Bottleneck (PGIB) that incorporates prototype learning within the information bottleneck framework to provide prototypes with the key subgraph from the input graph that is important for the model prediction. This is the first work that incorporates prototype learning into the process of identifying the key subgraphs that have a critical impact on the prediction performance. Extensive experiments, including qualitative analysis, demonstrate that PGIB outperforms state-of-the-art methods in terms of both prediction performance and explainability.
Unsupervised Episode Generation for Graph Meta-learning
Jun 27, 2023



In this paper, we investigate Unsupervised Episode Generation methods to solve Few-Shot Node-Classification (FSNC) problem via Meta-learning without labels. Dominant meta-learning methodologies for FSNC were developed under the existence of abundant labeled nodes for training, which however may not be possible to obtain in the real-world. Although few studies have been proposed to tackle the label-scarcity problem, they still rely on a limited amount of labeled data, which hinders the full utilization of the information of all nodes in a graph. Despite the effectiveness of Self-Supervised Learning (SSL) approaches on FSNC without labels, they mainly learn generic node embeddings without consideration on the downstream task to be solved, which may limit its performance. In this work, we propose unsupervised episode generation methods to benefit from their generalization ability for FSNC tasks while resolving label-scarcity problem. We first propose a method that utilizes graph augmentation to generate training episodes called g-UMTRA, which however has several drawbacks, i.e., 1) increased training time due to the computation of augmented features and 2) low applicability to existing baselines. Hence, we propose Neighbors as Queries (NaQ), which generates episodes from structural neighbors found by graph diffusion. Our proposed methods are model-agnostic, that is, they can be plugged into any existing graph meta-learning models, while not sacrificing much of their performance or sometimes even improving them. We provide theoretical insights to support why our unsupervised episode generation methodologies work, and extensive experimental results demonstrate the potential of our unsupervised episode generation methods for graph meta-learning towards FSNC problems.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021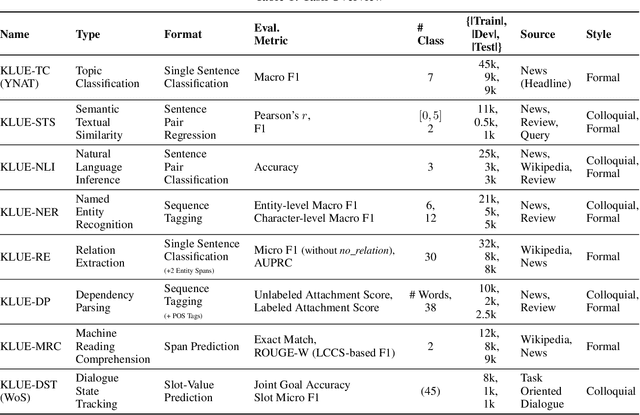
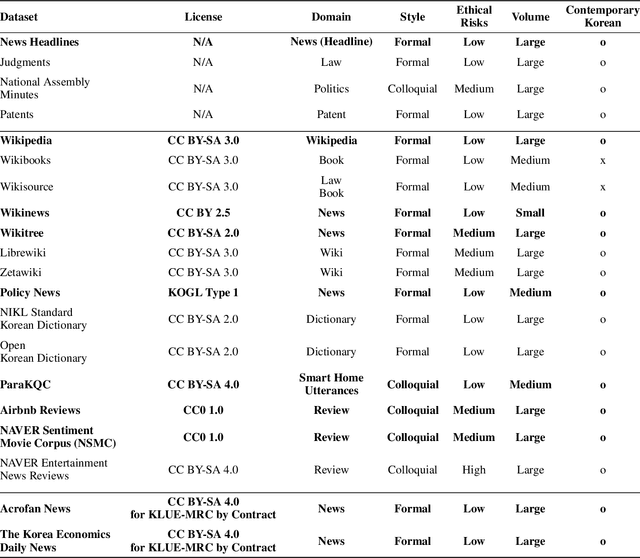
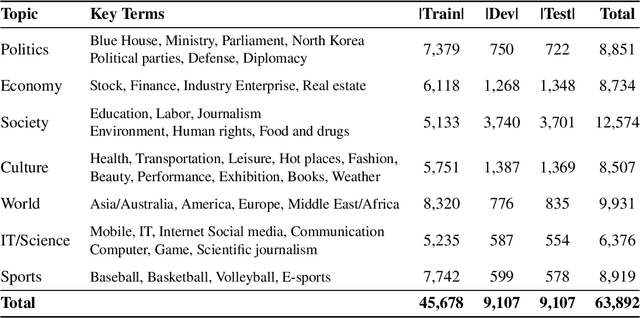
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.
An Empirical Study on Measuring the Similarity of Sentential Arguments with Language Model Domain Adaptation
Feb 19, 2021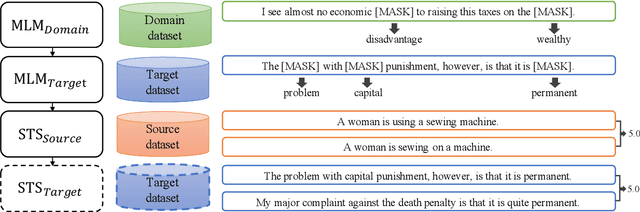

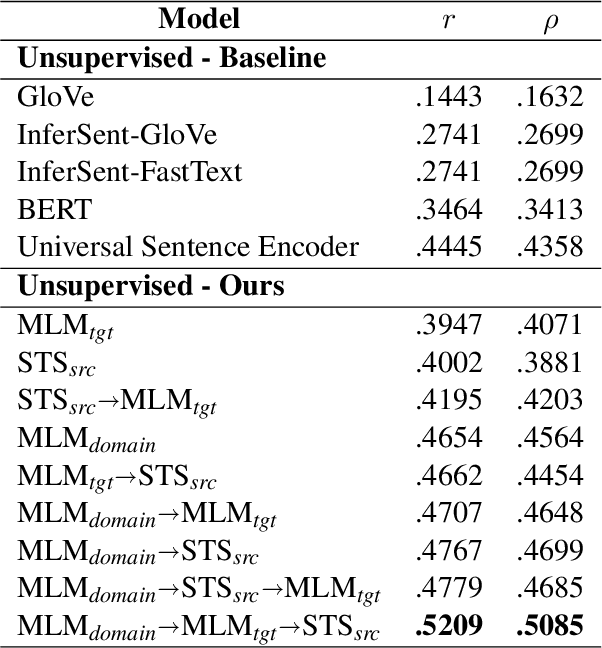
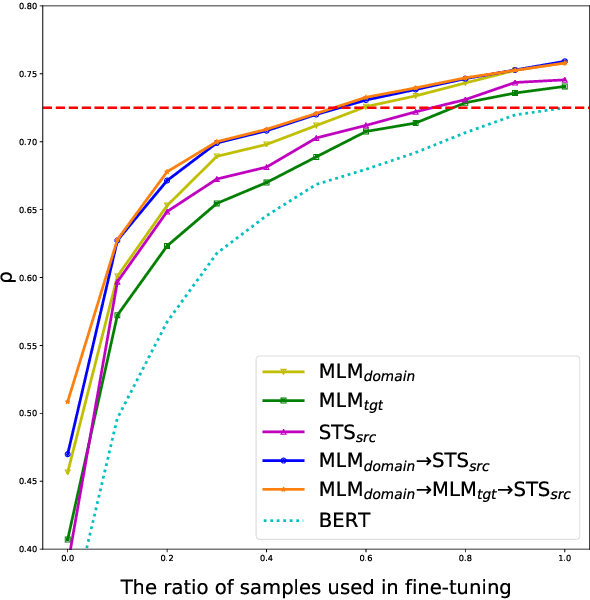
Measuring the similarity between two different sentential arguments is an important task in argument mining. However, one of the challenges in this field is that the dataset must be annotated using expertise in a variety of topics, making supervised learning with labeled data expensive. In this paper, we investigated whether this problem could be alleviated through transfer learning. We first adapted a pretrained language model to a domain of interest using self-supervised learning. Then, we fine-tuned the model to a task of measuring the similarity between sentences taken from different domains. Our approach improves a correlation with human-annotated similarity scores compared to competitive baseline models on the Argument Facet Similarity dataset in an unsupervised setting. Moreover, we achieve comparable performance to a fully supervised baseline model by using only about 60% of the labeled data samples. We believe that our work suggests the possibility of a generalized argument clustering model for various argumentative topics.
Semantic Relation Classification via Bidirectional LSTM Networks with Entity-aware Attention using Latent Entity Typing
Jan 23, 2019
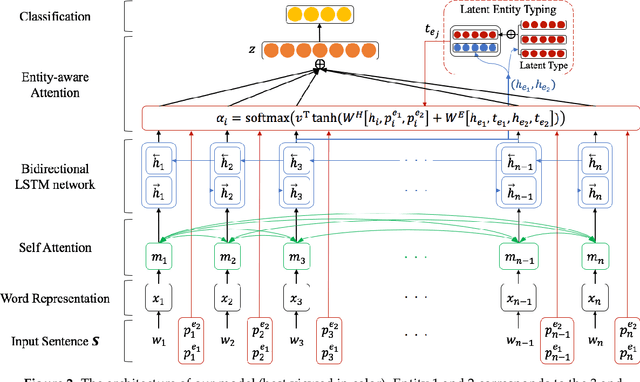
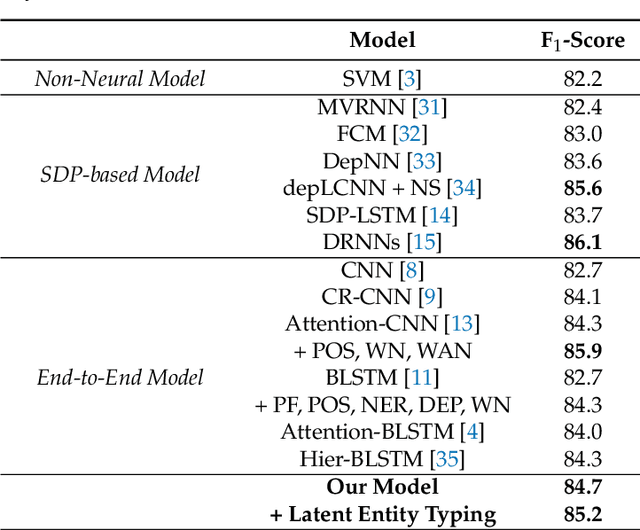
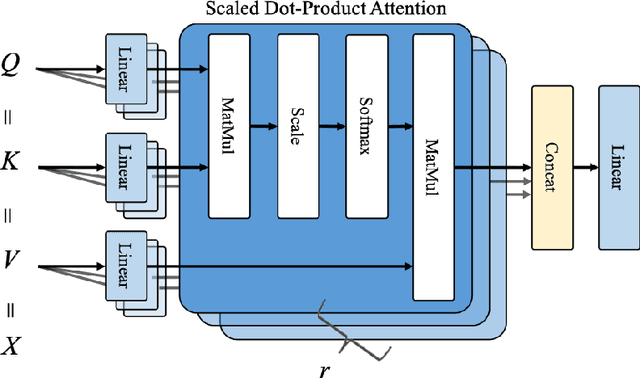
Classifying semantic relations between entity pairs in sentences is an important task in Natural Language Processing (NLP). Most previous models for relation classification rely on the high-level lexical and syntactic features obtained by NLP tools such as WordNet, dependency parser, part-of-speech (POS) tagger, and named entity recognizers (NER). In addition, state-of-the-art neural models based on attention mechanisms do not fully utilize information of entity that may be the most crucial features for relation classification. To address these issues, we propose a novel end-to-end recurrent neural model which incorporates an entity-aware attention mechanism with a latent entity typing (LET) method. Our model not only utilizes entities and their latent types as features effectively but also is more interpretable by visualizing attention mechanisms applied to our model and results of LET. Experimental results on the SemEval-2010 Task 8, one of the most popular relation classification task, demonstrate that our model outperforms existing state-of-the-art models without any high-level features.