 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Mismatch Doesn't Always Prevent Cross-Lingual Transfer Learning
Nov 30, 2022



Cross-lingual transfer learning without labeled target language data or parallel text has been surprisingly effective in zero-shot cross-lingual classification, question answering, unsupervised machine translation, etc. However, some recent publications have claimed that domain mismatch prevents cross-lingual transfer, and their results show that unsupervised bilingual lexicon induction (UBLI) and unsupervised neural machine translation (UNMT) do not work well when the underlying monolingual corpora come from different domains (e.g., French text from Wikipedia but English text from UN proceedings). In this work, we show that a simple initialization regimen can overcome much of the effect of domain mismatch in cross-lingual transfer. We pre-train word and contextual embeddings on the concatenated domain-mismatched corpora, and use these as initializations for three tasks: MUSE UBLI, UN Parallel UNMT, and the SemEval 2017 cross-lingual word similarity task. In all cases, our results challenge the conclusions of prior work by showing that proper initialization can recover a large portion of the losses incurred by domain mismatch.
* 8 pages, 1 figure. Published/presented at LREC (2022)
A Systematic Analysis of Morphological Content in BERT Models for Multiple Languages
Apr 06, 2020
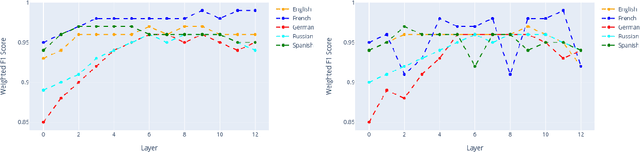


This work describes experiments which probe the hidden representations of several BERT-style models for morphological content. The goal is to examine the extent to which discrete linguistic structure, in the form of morphological features and feature values, presents itself in the vector representations and attention distributions of pre-trained language models for five European languages. The experiments contained herein show that (i) Transformer architectures largely partition their embedding space into convex sub-regions highly correlated with morphological feature value, (ii) the contextualized nature of transformer embeddings allows models to distinguish ambiguous morphological forms in many, but not all cases, and (iii) very specific attention head/layer combinations appear to hone in on subject-verb agreement.
Are Pre-trained Language Models Aware of Phrases? Simple but Strong Baselines for Grammar Induction
Jan 30, 2020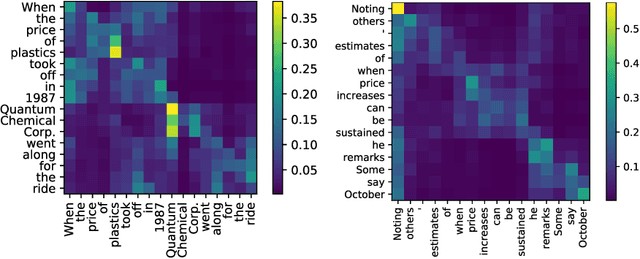
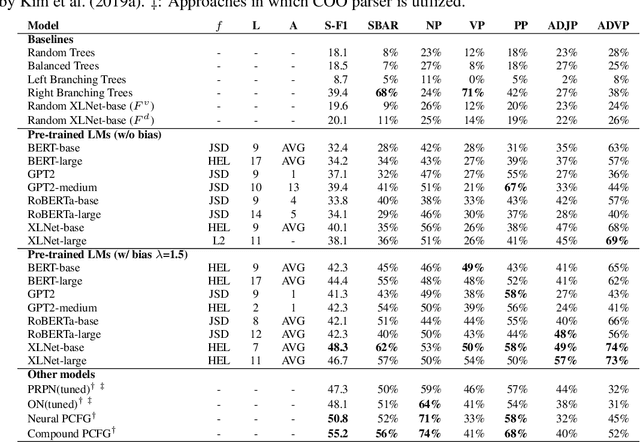
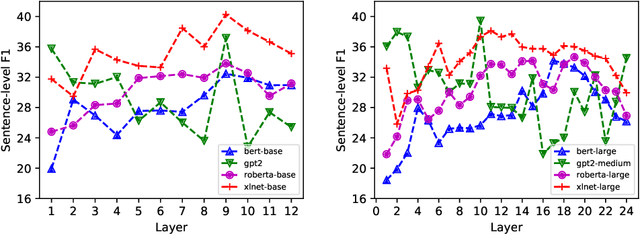
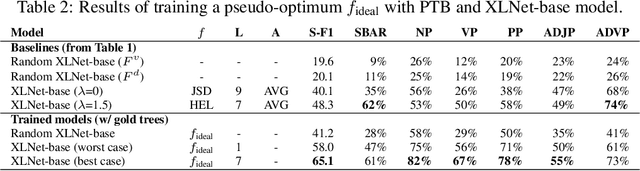
With the recent success and popularity of pre-trained language models (LMs) in natural language processing, there has been a rise in efforts to understand their inner workings. In line with such interest, we propose a novel method that assists us in investigating the extent to which pre-trained LMs capture the syntactic notion of constituency. Our method provides an effective way of extracting constituency trees from the pre-trained LMs without training. In addition, we report intriguing findings in the induced trees, including the fact that pre-trained LMs outperform other approaches in correctly demarcating adverb phrases in sentences.
Dynamic Compositionality in Recursive Neural Networks with Structure-aware Tag Representations
Sep 07, 2018
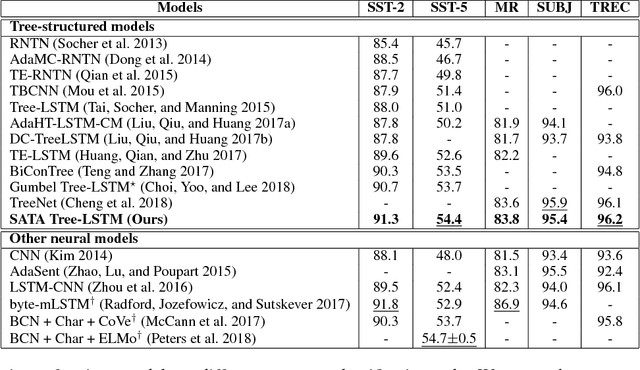
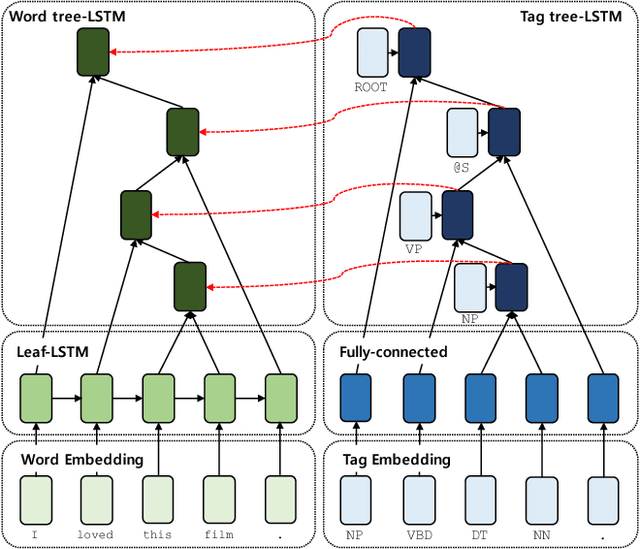
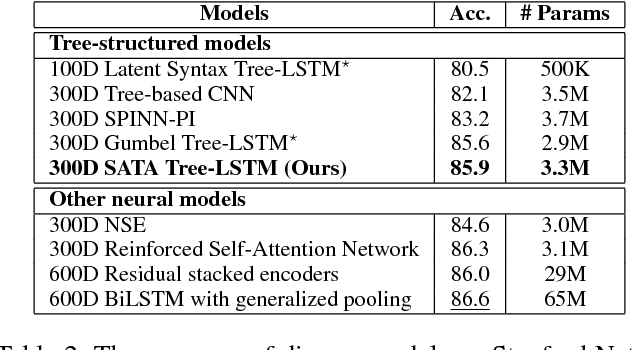
Most existing recursive neural network (RvNN) architectures utilize only the structure of parse trees, ignoring syntactic tags which are provided as by-products of parsing. We present a novel RvNN architecture that can provide dynamic compositionality by considering comprehensive syntactic information derived from both the structure and linguistic tags. Specifically, we introduce a structure-aware tag representation constructed by a separate tag-level tree-LSTM. With this, we can control the composition function of the existing word-level tree-LSTM by augmenting the representation as a supplementary input to the gate functions of the tree-LSTM. We show that models built upon the proposed architecture obtain superior performance on several sentence-level tasks such as sentiment analysis and natural language inference when compared against previous tree-structured models and other sophisticated neural models. In particular, our models achieve new state-of-the-art results on Stanford Sentiment Treebank, Movie Review, and Text Retrieval Conference datasets.