 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRollout-Level Advantage-Prioritized Experience Replay for GRPO
Jun 04, 2026Reinforcement learning from verifiable rewards with GRPO is a standard approach for post-training reasoning LLMs. It remains sample inefficient. Each rollout is used for a single gradient update and then discarded. Naive replay is not well suited in this setting because LLM policies drift quickly per gradient step. Stored rollouts therefore become stale and can destabilize training. We propose a rollout-level replay buffer for GRPO that stores and samples individual rollouts rather than whole groups. The buffer bounds staleness through age eviction. Any rollout older than tau_max training steps is removed. The buffer also preserves on-policy data via fresh-anchored composition. Each batch keeps its fresh on-policy rollouts and then concatenates replay rollouts drawn separately from the buffer. We prioritize replay by per-rollout advantage magnitude and recycle individual rollouts whose advantages are large. Across three Qwen3-Base scales on five math benchmarks, our method outperforms GRPO and naive replay baselines. Gains are positive at every scale and grow with model size. The largest gain is +4.35 pp on the five-benchmark average at 4B. Under an AES metric that jointly measures accuracy and token efficiency, the efficiency margin over GRPO is again largest at 4B, at +0.579.
Balancing Saliency and Coverage: Semantic Prominence-Aware Budgeting for Visual Token Compression in VLMs
Mar 16, 2026Large Vision-Language Models (VLMs) achieve strong multimodal understanding capabilities by leveraging high-resolution visual inputs, but the resulting large number of visual tokens creates a major computational bottleneck. Recent work mitigates this issue through visual token compression, typically compressing tokens based on saliency, diversity, or a fixed combination of both. We observe that the distribution of semantic prominence varies substantially across samples, leading to different optimal trade-offs between local saliency preservation and global coverage. This observation suggests that applying a static compression strategy across all samples can be suboptimal. Motivated by this insight, we propose PromPrune, a sample-adaptive visual token selection framework composed of semantic prominence-aware budget allocation and a two-stage selection pipeline. Our method adaptively balances local saliency preservation and global coverage according to the semantic prominence distribution of each sample. By allocating token budgets between locally salient regions and globally diverse regions, our method maintains strong performance even under high compression ratios. On LLaVA-NeXT-7B, our approach reduces FLOPs by 88% and prefill latency by 22% while preserving 97.5% of the original accuracy.
Superpixel Tokenization for Vision Transformers: Preserving Semantic Integrity in Visual Tokens
Dec 06, 2024



Transformers, a groundbreaking architecture proposed for Natural Language Processing (NLP), have also achieved remarkable success in Computer Vision. A cornerstone of their success lies in the attention mechanism, which models relationships among tokens. While the tokenization process in NLP inherently ensures that a single token does not contain multiple semantics, the tokenization of Vision Transformer (ViT) utilizes tokens from uniformly partitioned square image patches, which may result in an arbitrary mixing of visual concepts in a token. In this work, we propose to substitute the grid-based tokenization in ViT with superpixel tokenization, which employs superpixels to generate a token that encapsulates a sole visual concept. Unfortunately, the diverse shapes, sizes, and locations of superpixels make integrating superpixels into ViT tokenization rather challenging. Our tokenization pipeline, comprised of pre-aggregate extraction and superpixel-aware aggregation, overcomes the challenges that arise in superpixel tokenization. Extensive experiments demonstrate that our approach, which exhibits strong compatibility with existing frameworks, enhances the accuracy and robustness of ViT on various downstream tasks.
FedRN: Exploiting k-Reliable Neighbors Towards Robust Federated Learning
May 03, 2022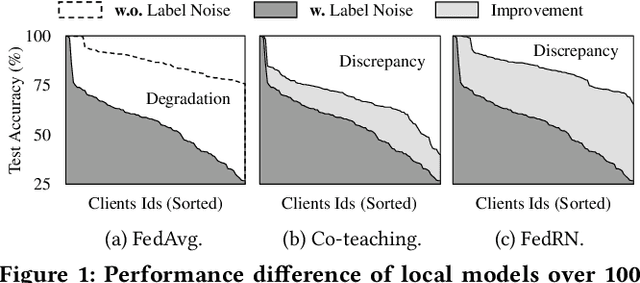
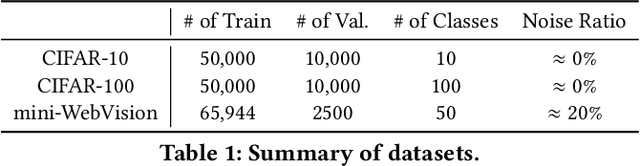
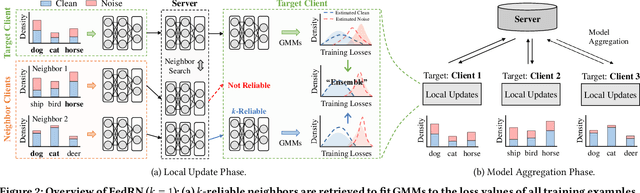
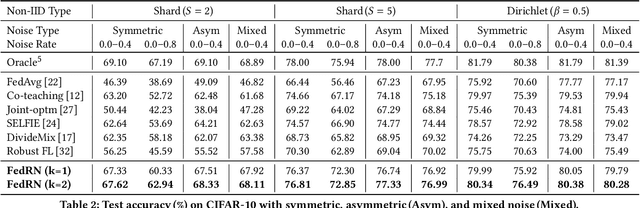
Robustness is becoming another important challenge of federated learning in that the data collection process in each client is naturally accompanied by noisy labels. However, it is far more complex and challenging owing to varying levels of data heterogeneity and noise over clients, which exacerbates the client-to-client performance discrepancy. In this work, we propose a robust federated learning method called FedRN, which exploits k-reliable neighbors with high data expertise or similarity. Our method helps mitigate the gap between low- and high-performance clients by training only with a selected set of clean examples, identified by their ensembled mixture models. We demonstrate the superiority of FedRN via extensive evaluations on three real-world or synthetic benchmark datasets. Compared with existing robust training methods, the results show that FedRN significantly improves the test accuracy in the presence of noisy labels.