 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA semi-supervised geometric-driven methodology for supervised fishing activity detection on multi-source AIS tracking messages
Jul 12, 2022
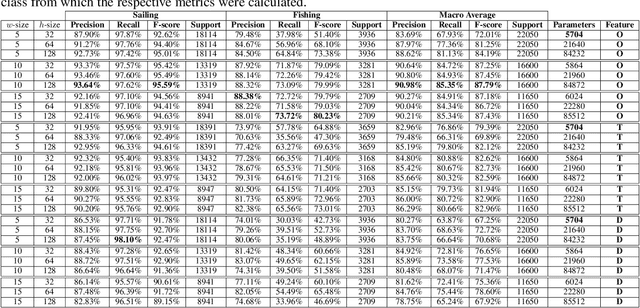
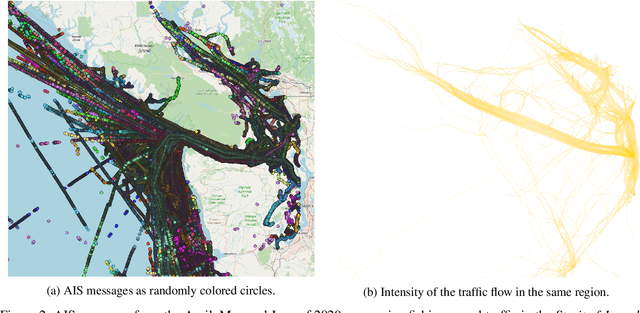

Automatic Identification System (AIS) messages are useful for tracking vessel activity across oceans worldwide using radio links and satellite transceivers. Such data plays a significant role in tracking vessel activity and mapping mobility patterns such as those found in fishing. Accordingly, this paper proposes a geometric-driven semi-supervised approach for fishing activity detection from AIS data. Through the proposed methodology we show how to explore the information included in the messages to extract features describing the geometry of the vessel route. To this end, we leverage the unsupervised nature of cluster analysis to label the trajectory geometry highlighting the changes in the vessel's moving pattern which tends to indicate fishing activity. The labels obtained by the proposed unsupervised approach are used to detect fishing activities, which we approach as a time-series classification task. In this context, we propose a solution using recurrent neural networks on AIS data streams with roughly 87% of the overall $F$-score on the whole trajectories of 50 different unseen fishing vessels. Such results are accompanied by a broad benchmark study assessing the performance of different Recurrent Neural Network (RNN) architectures. In conclusion, this work contributes by proposing a thorough process that includes data preparation, labeling, data modeling, and model validation. Therefore, we present a novel solution for mobility pattern detection that relies upon unfolding the trajectory in time and observing their inherent geometry.
Active learning for medical code assignment
Apr 12, 2021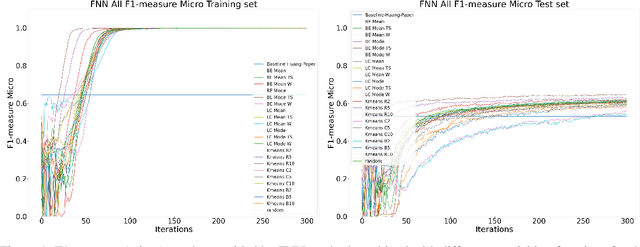
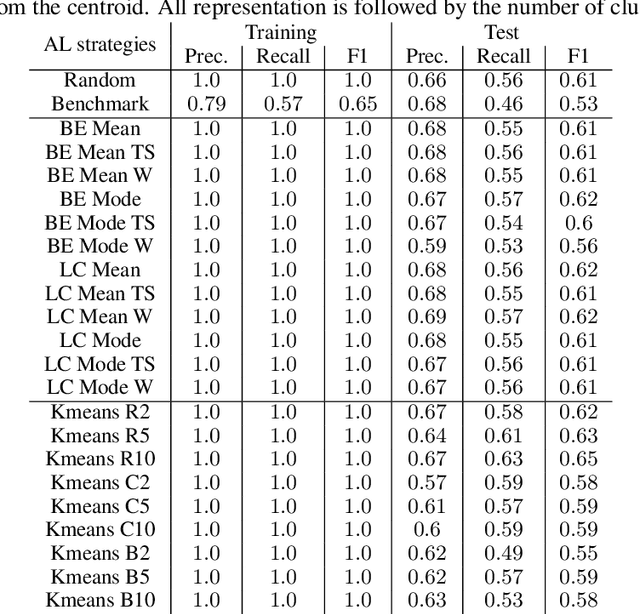
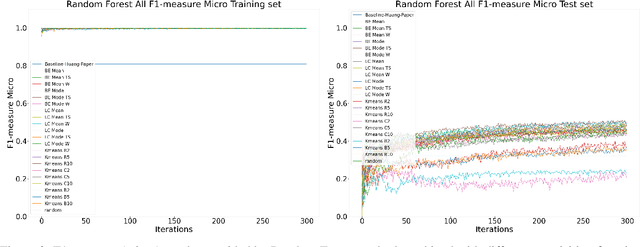
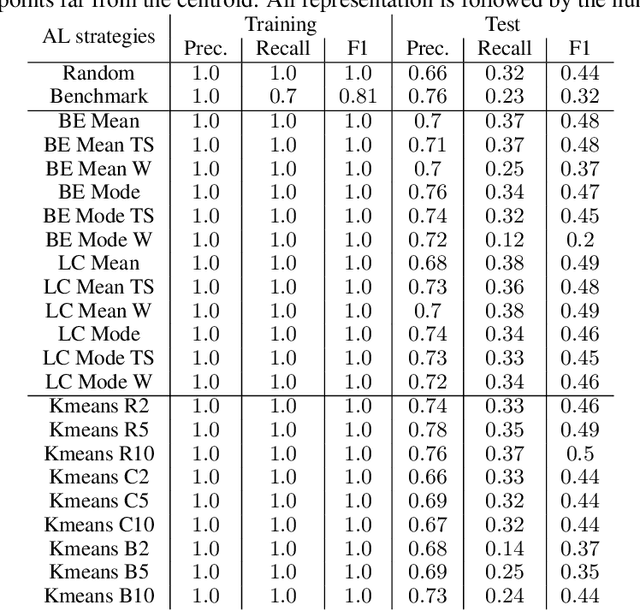
Machine Learning (ML) is widely used to automatically extract meaningful information from Electronic Health Records (EHR) to support operational, clinical, and financial decision-making. However, ML models require a large number of annotated examples to provide satisfactory results, which is not possible in most healthcare scenarios due to the high cost of clinician-labeled data. Active Learning (AL) is a process of selecting the most informative instances to be labeled by an expert to further train a supervised algorithm. We demonstrate the effectiveness of AL in multi-label text classification in the clinical domain. In this context, we apply a set of well-known AL methods to help automatically assign ICD-9 codes on the MIMIC-III dataset. Our results show that the selection of informative instances provides satisfactory classification with a significantly reduced training set (8.3\% of the total instances). We conclude that AL methods can significantly reduce the manual annotation cost while preserving model performance.
Providing theoretical learning guarantees to Deep Learning Networks
Nov 28, 2017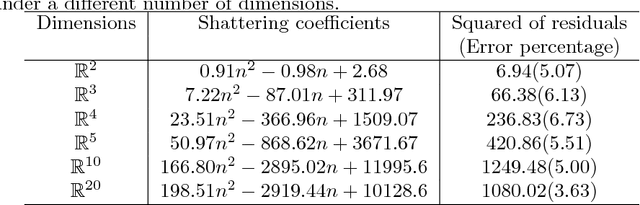
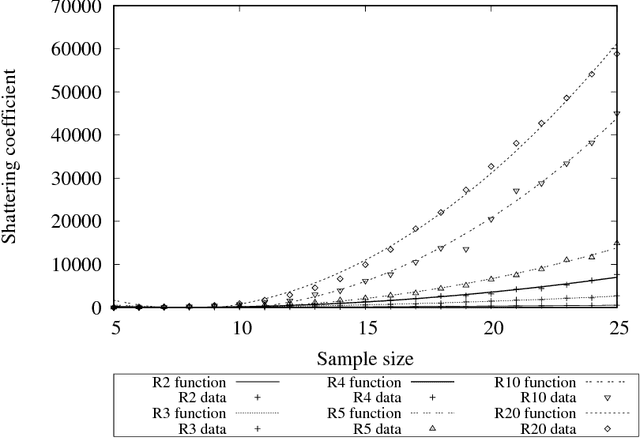
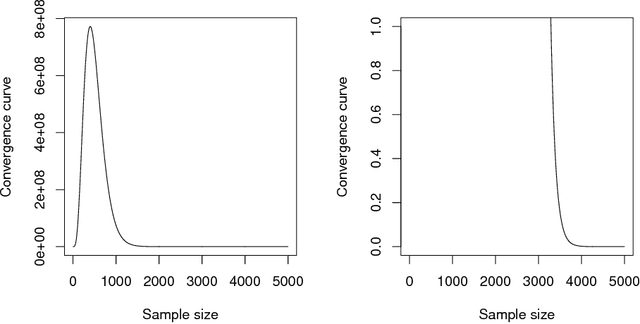

Deep Learning (DL) is one of the most common subjects when Machine Learning and Data Science approaches are considered. There are clearly two movements related to DL: the first aggregates researchers in quest to outperform other algorithms from literature, trying to win contests by considering often small decreases in the empirical risk; and the second investigates overfitting evidences, questioning the learning capabilities of DL classifiers. Motivated by such opposed points of view, this paper employs the Statistical Learning Theory (SLT) to study the convergence of Deep Neural Networks, with particular interest in Convolutional Neural Networks. In order to draw theoretical conclusions, we propose an approach to estimate the Shattering coefficient of those classification algorithms, providing a lower bound for the complexity of their space of admissible functions, a.k.a. algorithm bias. Based on such estimator, we generalize the complexity of network biases, and, next, we study AlexNet and VGG16 architectures in the point of view of their Shattering coefficients, and number of training examples required to provide theoretical learning guarantees. From our theoretical formulation, we show the conditions which Deep Neural Networks learn as well as point out another issue: DL benchmarks may be strictly driven by empirical risks, disregarding the complexity of algorithms biases.
Acoustic Modeling Using a Shallow CNN-HTSVM Architecture
Jun 27, 2017
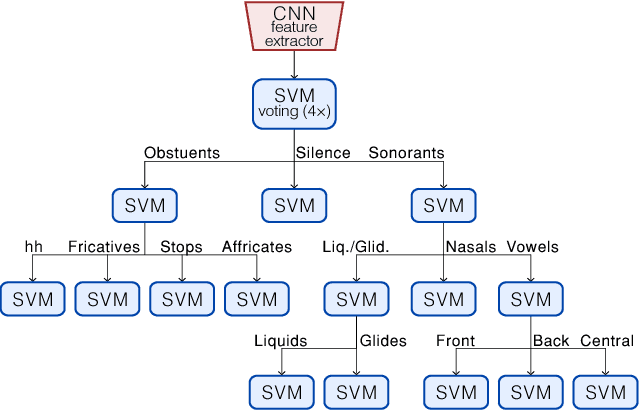
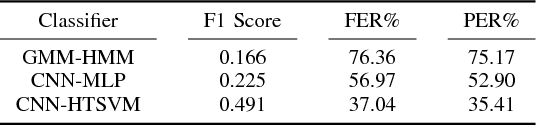
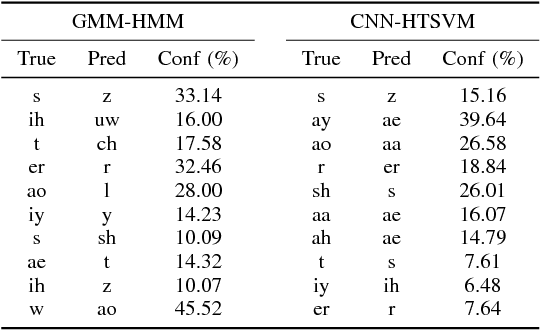
High-accuracy speech recognition is especially challenging when large datasets are not available. It is possible to bridge this gap with careful and knowledge-driven parsing combined with the biologically inspired CNN and the learning guarantees of the Vapnik Chervonenkis (VC) theory. This work presents a Shallow-CNN-HTSVM (Hierarchical Tree Support Vector Machine classifier) architecture which uses a predefined knowledge-based set of rules with statistical machine learning techniques. Here we show that gross errors present even in state-of-the-art systems can be avoided and that an accurate acoustic model can be built in a hierarchical fashion. The CNN-HTSVM acoustic model outperforms traditional GMM-HMM models and the HTSVM structure outperforms a MLP multi-class classifier. More importantly we isolate the performance of the acoustic model and provide results on both the frame and phoneme level considering the true robustness of the model. We show that even with a small amount of data accurate and robust recognition rates can be obtained.