 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagarela - A Portuguese speech dataset from podcasts
Mar 16, 2026Despite significant advances in speech processing, Portuguese remains under-resourced due to the scarcity of public, large-scale, and high-quality datasets. To address this gap, we present a new dataset, named TAGARELA, composed of over 8,972 hours of podcast audio, specifically curated for training automatic speech recognition (ASR) and text-to-speech (TTS) models. Notably, its scale rivals English's GigaSpeech (10kh), enabling state-of-the-art Portuguese models. To ensure data quality, the corpus was subjected to an audio pre-processing pipeline and subsequently transcribed using a mixed strategy: we applied ASR models that were previously trained on high-fidelity transcriptions generated by proprietary APIs, ensuring a high level of initial accuracy. Finally, to validate the effectiveness of this new resource, we present ASR and TTS models trained exclusively on our dataset and evaluate their performance, demonstrating its potential to drive the development of more robust and natural speech technologies for Portuguese. The dataset is released publicly, available at https://freds0.github.io/TAGARELA/, to foster the development of robust speech technologies.
Proactive Security: Embedded AI Solution for Violent and Abusive Speech Recognition
Oct 22, 2018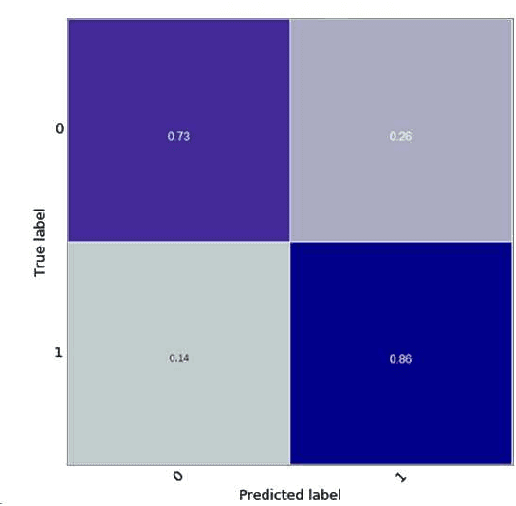
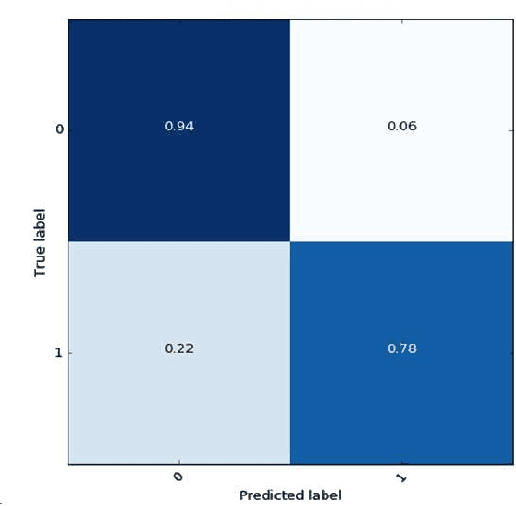
Violence is an epidemic in Brazil and a problem on the rise world-wide. Mobile devices provide communication technologies which can be used to monitor and alert about violent situations. However, current solutions, like panic buttons or safe words, might increase the loss of life in violent situations. We propose an embedded artificial intelligence solution, using natural language and speech processing technology, to silently alert someone who can help in this situation. The corpus used contains 400 positive phrases and 800 negative phrases, totaling 1,200 sentences which are classified using two well-known extraction methods for natural language processing tasks: bag-of-words and word embeddings and classified with a support vector machine. We describe the proof-of-concept product in development with promising results, indicating a path towards a commercial product. More importantly we show that model improvements via word embeddings and data augmentation techniques provide an intrinsically robust model. The final embedded solution also has a small footprint of less than 10 MB.
Acoustic Modeling Using a Shallow CNN-HTSVM Architecture
Jun 27, 2017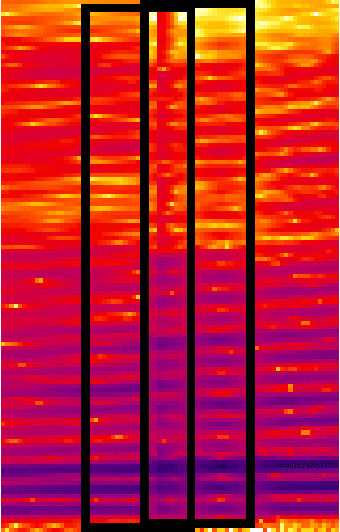
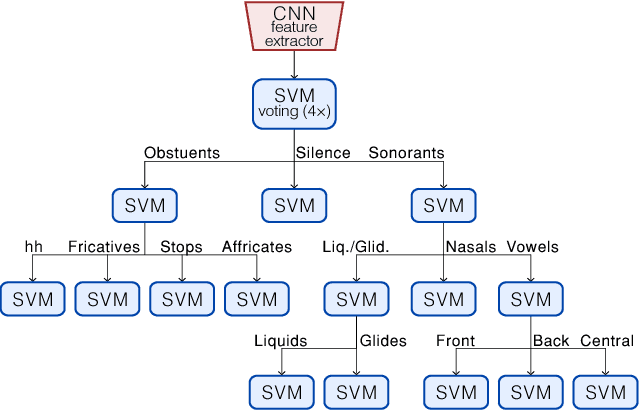
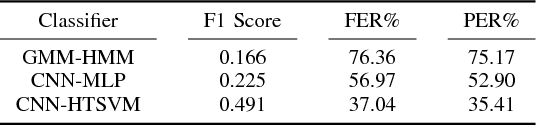
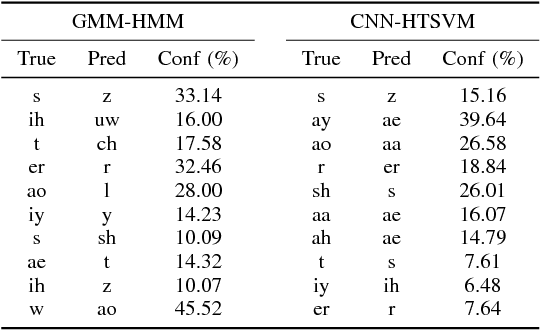
High-accuracy speech recognition is especially challenging when large datasets are not available. It is possible to bridge this gap with careful and knowledge-driven parsing combined with the biologically inspired CNN and the learning guarantees of the Vapnik Chervonenkis (VC) theory. This work presents a Shallow-CNN-HTSVM (Hierarchical Tree Support Vector Machine classifier) architecture which uses a predefined knowledge-based set of rules with statistical machine learning techniques. Here we show that gross errors present even in state-of-the-art systems can be avoided and that an accurate acoustic model can be built in a hierarchical fashion. The CNN-HTSVM acoustic model outperforms traditional GMM-HMM models and the HTSVM structure outperforms a MLP multi-class classifier. More importantly we isolate the performance of the acoustic model and provide results on both the frame and phoneme level considering the true robustness of the model. We show that even with a small amount of data accurate and robust recognition rates can be obtained.