 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Approach for Characterizing Major Galaxy Mergers
Feb 09, 2021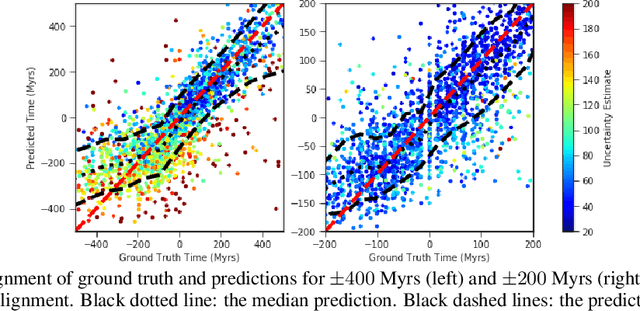

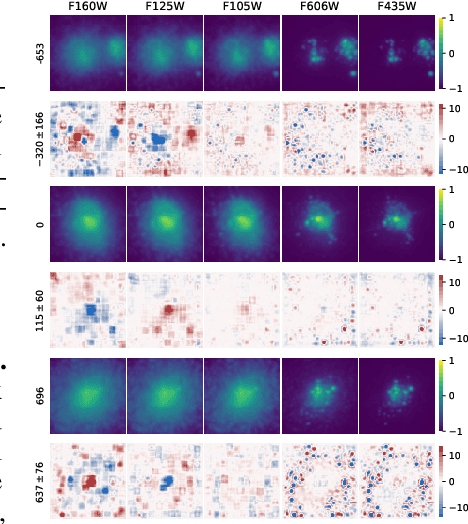
Fine-grained estimation of galaxy merger stages from observations is a key problem useful for validation of our current theoretical understanding of galaxy formation. To this end, we demonstrate a CNN-based regression model that is able to predict, for the first time, using a single image, the merger stage relative to the first perigee passage with a median error of 38.3 million years (Myrs) over a period of 400 Myrs. This model uses no specific dynamical modeling and learns only from simulated merger events. We show that our model provides reasonable estimates on real observations, approximately matching prior estimates provided by detailed dynamical modeling. We provide a preliminary interpretability analysis of our models, and demonstrate first steps toward calibrated uncertainty estimation.
Towards transformation-resilient provenance detection of digital media
Nov 14, 2020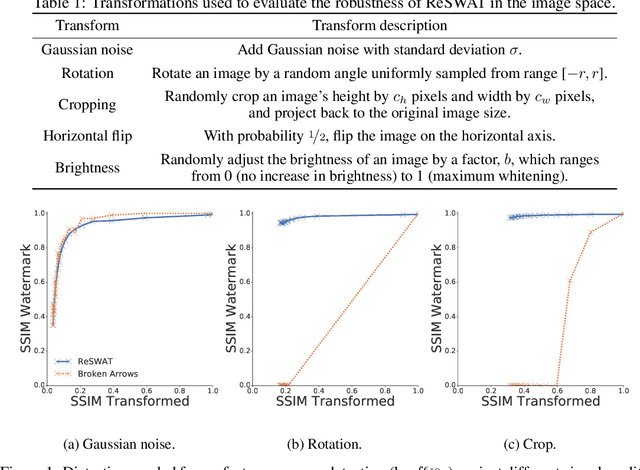
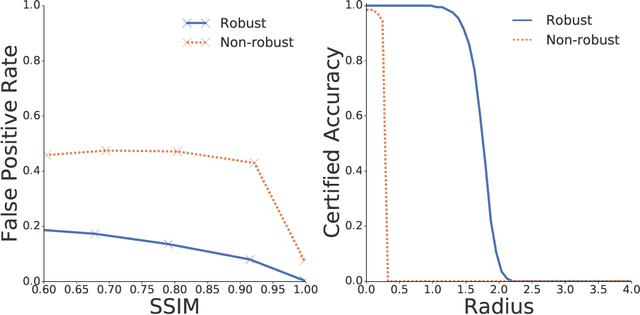

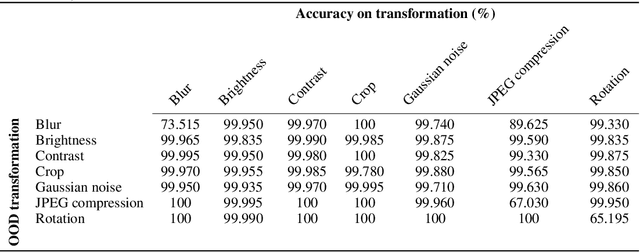
Advancements in deep generative models have made it possible to synthesize images, videos and audio signals that are difficult to distinguish from natural signals, creating opportunities for potential abuse of these capabilities. This motivates the problem of tracking the provenance of signals, i.e., being able to determine the original source of a signal. Watermarking the signal at the time of signal creation is a potential solution, but current techniques are brittle and watermark detection mechanisms can easily be bypassed by applying post-processing transformations (cropping images, shifting pitch in the audio etc.). In this paper, we introduce ReSWAT (Resilient Signal Watermarking via Adversarial Training), a framework for learning transformation-resilient watermark detectors that are able to detect a watermark even after a signal has been through several post-processing transformations. Our detection method can be applied to domains with continuous data representations such as images, videos or sound signals. Experiments on watermarking image and audio signals show that our method can reliably detect the provenance of a signal, even if it has been through several post-processing transformations, and improve upon related work in this setting. Furthermore, we show that for specific kinds of transformations (perturbations bounded in the L2 norm), we can even get formal guarantees on the ability of our model to detect the watermark. We provide qualitative examples of watermarked image and audio samples in https://drive.google.com/open?id=1-yZ0WIGNu2Iez7UpXBjtjVgZu3jJjFga.
Self-Supervised MultiModal Versatile Networks
Jun 29, 2020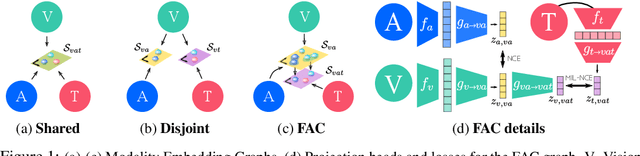
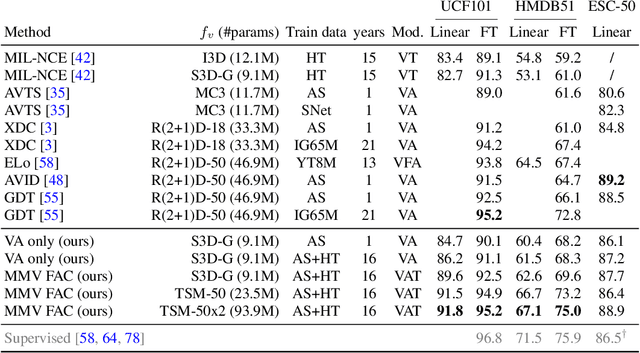
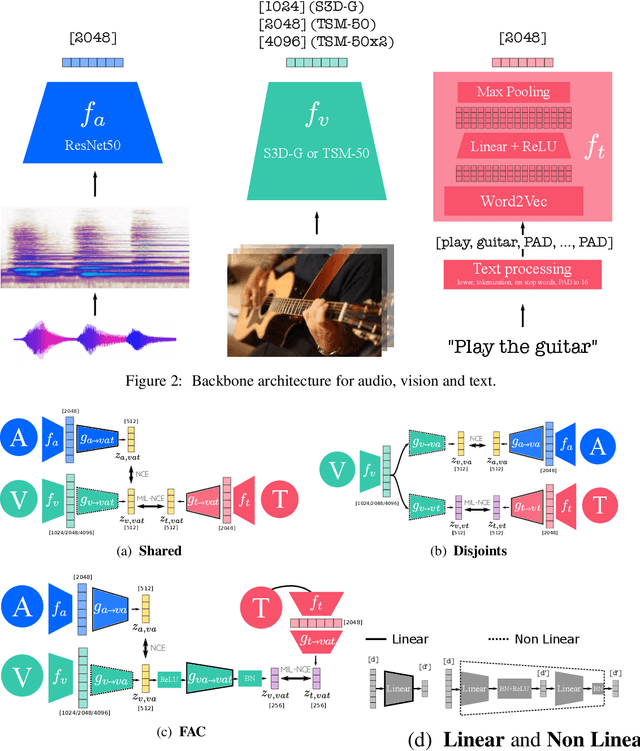
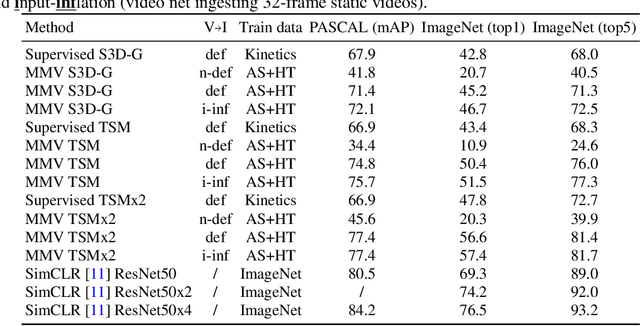
Videos are a rich source of multi-modal supervision. In this work, we learn representations using self-supervision by leveraging three modalities naturally present in videos: vision, audio and language. To this end, we introduce the notion of a multimodal versatile network -- a network that can ingest multiple modalities and whose representations enable downstream tasks in multiple modalities. In particular, we explore how best to combine the modalities, such that fine-grained representations of audio and vision can be maintained, whilst also integrating text into a common embedding. Driven by versatility, we also introduce a novel process of deflation, so that the networks can be effortlessly applied to the visual data in the form of video or a static image. We demonstrate how such networks trained on large collections of unlabelled video data can be applied on video, video-text, image and audio tasks. Equipped with these representations, we obtain state-of-the-art performance on multiple challenging benchmarks including UCF101, HMDB51 and ESC-50 when compared to previous self-supervised work.
End-to-End Adversarial Text-to-Speech
Jun 05, 2020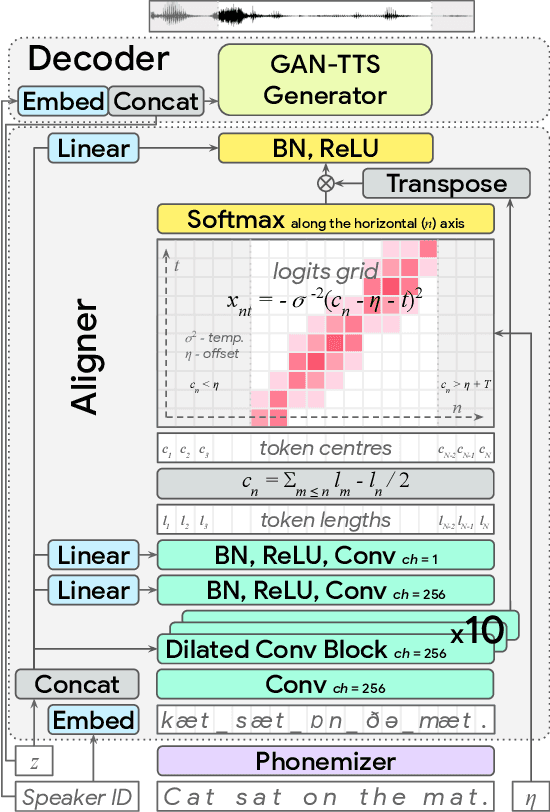
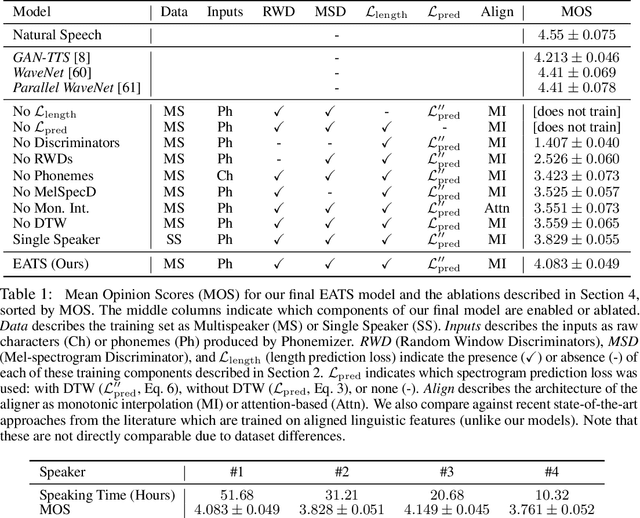

Modern text-to-speech synthesis pipelines typically involve multiple processing stages, each of which is designed or learnt independently from the rest. In this work, we take on the challenging task of learning to synthesise speech from normalised text or phonemes in an end-to-end manner, resulting in models which operate directly on character or phoneme input sequences and produce raw speech audio outputs. Our proposed generator is feed-forward and thus efficient for both training and inference, using a differentiable monotonic interpolation scheme to predict the duration of each input token. It learns to produce high fidelity audio through a combination of adversarial feedback and prediction losses constraining the generated audio to roughly match the ground truth in terms of its total duration and mel-spectrogram. To allow the model to capture temporal variation in the generated audio, we employ soft dynamic time warping in the spectrogram-based prediction loss. The resulting model achieves a mean opinion score exceeding 4 on a 5 point scale, which is comparable to the state-of-the-art models relying on multi-stage training and additional supervision.
Transformation-based Adversarial Video Prediction on Large-Scale Data
Mar 09, 2020
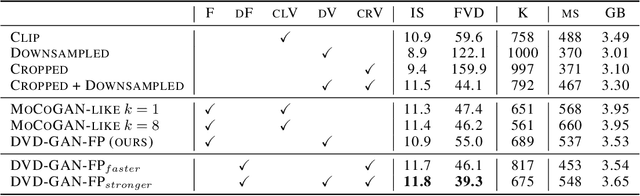
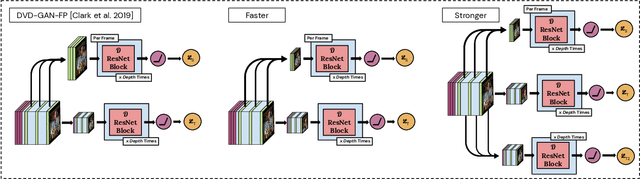
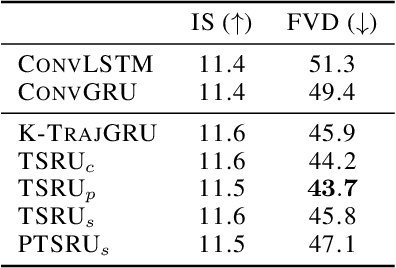
Recent breakthroughs in adversarial generative modeling have led to models capable of producing video samples of high quality, even on large and complex datasets of real-world video. In this work, we focus on the task of video prediction, where given a sequence of frames extracted from a video, the goal is to generate a plausible future sequence. We first improve the state of the art by performing a systematic empirical study of discriminator decompositions and proposing an architecture that yields faster convergence and higher performance than previous approaches. We then analyze recurrent units in the generator, and propose a novel recurrent unit which transforms its past hidden state according to predicted motion-like features, and refines it to to handle dis-occlusions, scene changes and other complex behavior. We show that this recurrent unit consistently outperforms previous designs. Our final model leads to a leap in the state-of-the-art performance, obtaining a test set Frechet Video Distance of 25.7, down from 69.2, on the large-scale Kinetics-600 dataset.
High Fidelity Speech Synthesis with Adversarial Networks
Sep 26, 2019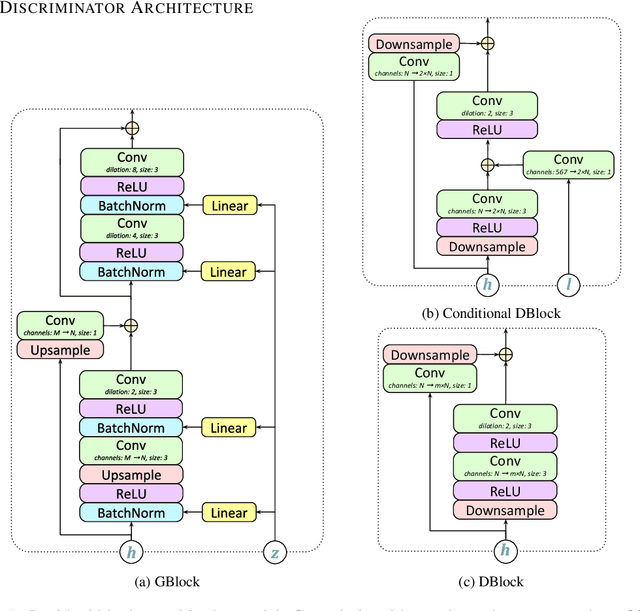
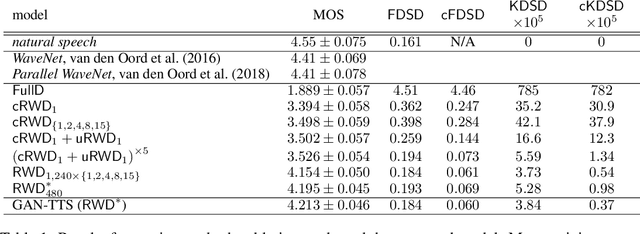
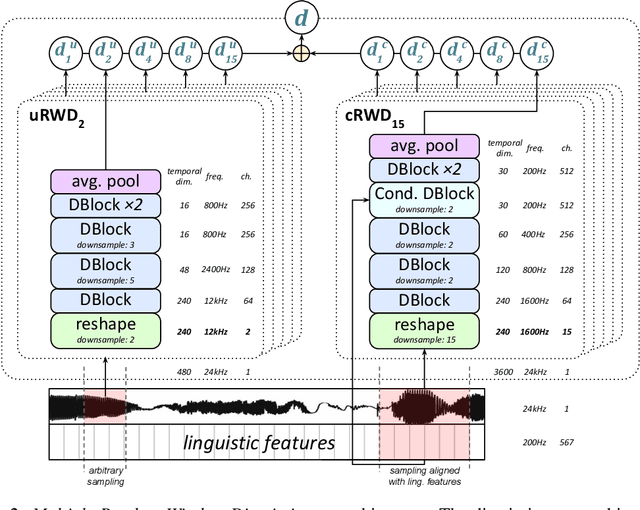
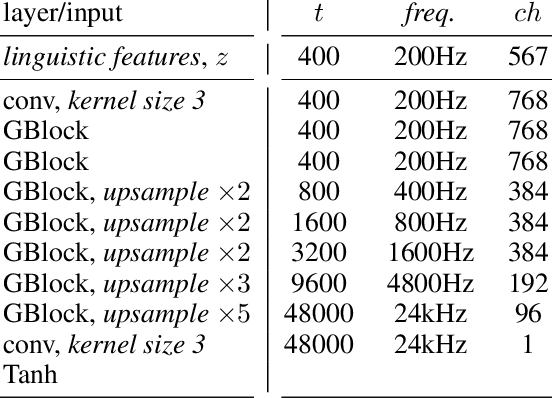
Generative adversarial networks have seen rapid development in recent years and have led to remarkable improvements in generative modelling of images. However, their application in the audio domain has received limited attention, and autoregressive models, such as WaveNet, remain the state of the art in generative modelling of audio signals such as human speech. To address this paucity, we introduce GAN-TTS, a Generative Adversarial Network for Text-to-Speech. Our architecture is composed of a conditional feed-forward generator producing raw speech audio, and an ensemble of discriminators which operate on random windows of different sizes. The discriminators analyse the audio both in terms of general realism, as well as how well the audio corresponds to the utterance that should be pronounced. To measure the performance of GAN-TTS, we employ both subjective human evaluation (MOS - Mean Opinion Score), as well as novel quantitative metrics (Fr\'echet DeepSpeech Distance and Kernel DeepSpeech Distance), which we find to be well correlated with MOS. We show that GAN-TTS is capable of generating high-fidelity speech with naturalness comparable to the state-of-the-art models, and unlike autoregressive models, it is highly parallelisable thanks to an efficient feed-forward generator. Listen to GAN-TTS reading this abstract at https://storage.googleapis.com/deepmind-media/research/abstract.wav.
Hierarchical Autoregressive Image Models with Auxiliary Decoders
Mar 06, 2019

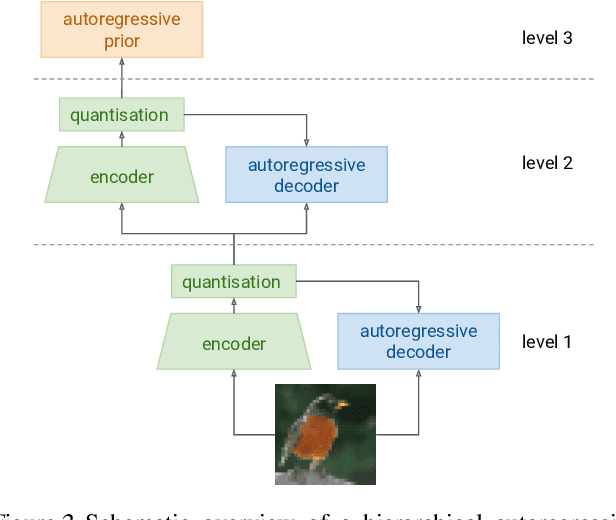
Autoregressive generative models of images tend to be biased towards capturing local structure, and as a result they often produce samples which are lacking in terms of large-scale coherence. To address this, we propose two methods to learn discrete representations of images which abstract away local detail. We show that autoregressive models conditioned on these representations can produce high-fidelity reconstructions of images, and that we can train autoregressive priors on these representations that produce samples with large-scale coherence. We can recursively apply the learning procedure, yielding a hierarchy of progressively more abstract image representations. We train hierarchical class-conditional autoregressive models on the ImageNet dataset and demonstrate that they are able to generate realistic images at resolutions of 128$\times$128 and 256$\times$256 pixels.
Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset
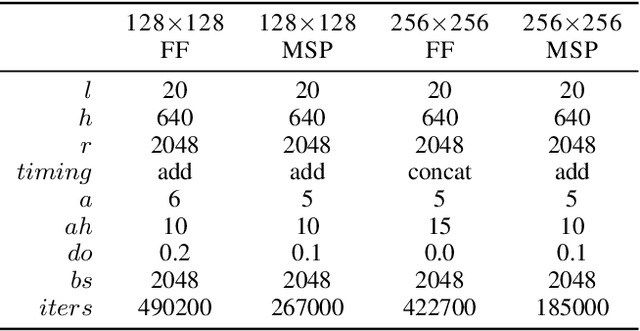
Oct 30, 2018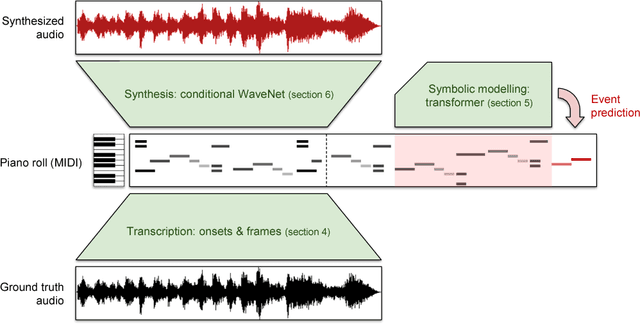

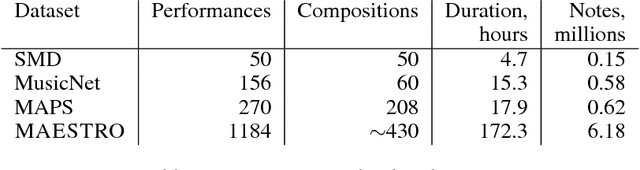
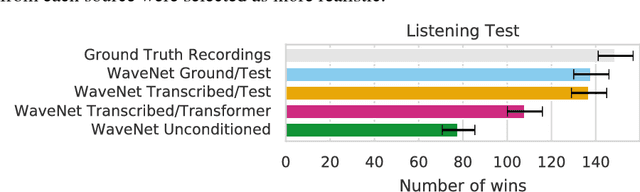
Generating musical audio directly with neural networks is notoriously difficult because it requires coherently modeling structure at many different timescales. Fortunately, most music is also highly structured and can be represented as discrete note events played on musical instruments. Herein, we show that by using notes as an intermediate representation, we can train a suite of models capable of transcribing, composing, and synthesizing audio waveforms with coherent musical structure on timescales spanning six orders of magnitude (~0.1 ms to ~100 s), a process we call Wave2Midi2Wave. This large advance in the state of the art is enabled by our release of the new MAESTRO (MIDI and Audio Edited for Synchronous TRacks and Organization) dataset, composed of over 172 hours of virtuosic piano performances captured with fine alignment (~3 ms) between note labels and audio waveforms. The networks and the dataset together present a promising approach toward creating new expressive and interpretable neural models of music.
Piano Genie
Oct 11, 2018
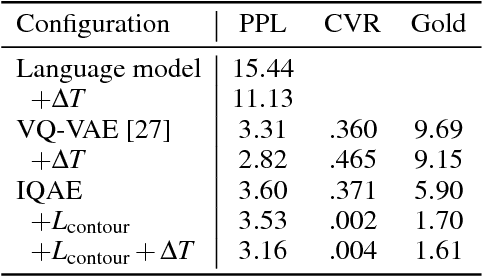
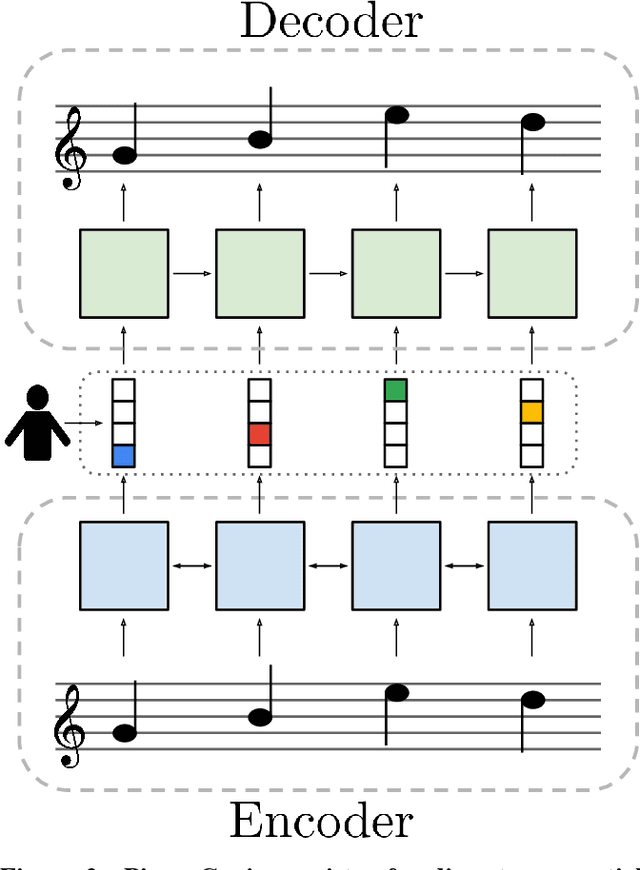
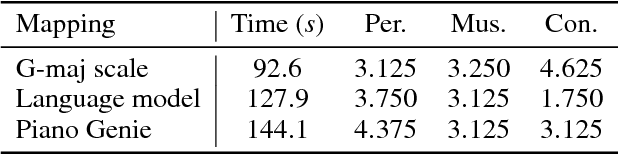
We present Piano Genie, an intelligent controller which allows non-musicians to improvise on the piano. With Piano Genie, a user performs on a simple interface with eight buttons, and their performance is decoded into the space of plausible piano music in real time. To learn a suitable mapping procedure for this problem, we train recurrent neural network autoencoders with discrete bottlenecks: an encoder learns an appropriate sequence of buttons corresponding to a piano piece, and a decoder learns to map this sequence back to the original piece. During performance, we substitute a user's input for the encoder output, and play the decoder's prediction each time the user presses a button. To improve the interpretability of Piano Genie's performance mechanics, we impose musically-salient constraints over the encoder's outputs.
This Time with Feeling: Learning Expressive Musical Performance
Aug 10, 2018
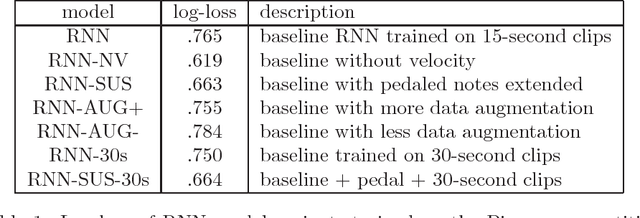

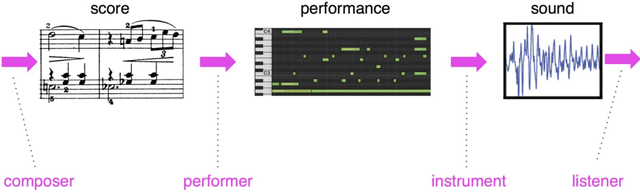
Music generation has generally been focused on either creating scores or interpreting them. We discuss differences between these two problems and propose that, in fact, it may be valuable to work in the space of direct $\it performance$ generation: jointly predicting the notes $\it and$ $\it also$ their expressive timing and dynamics. We consider the significance and qualities of the data set needed for this. Having identified both a problem domain and characteristics of an appropriate data set, we show an LSTM-based recurrent network model that subjectively performs quite well on this task. Critically, we provide generated examples. We also include feedback from professional composers and musicians about some of these examples.