 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the Chain of Thought Knows Better: Failure Modes in Multi-Turn Reasoning Models
Jun 09, 2026Failures in multi-turn reasoning models are largely invisible to terminal-score evaluation. A model can lock onto an unsafe stance early in a long dialogue, yet its final-turn refusal rate may appear indistinguishable from a robustly aligned baseline. To expose these hidden temporal dynamics, we propose a trace-level diagnostic - the CoT-Output 2x2 safety matrix. This framework labels every turn along two independent axes (internal reasoning and visible output), yielding four operationally defined failure cells: robust alignment, alignment faking, overt jailbreak, and a distinct failure mode we term context-injection failure (where the CoT maintains safe reasoning, but the visible output produces harm, highlighting a multi-turn manifestation of reasoning unfaithfulness). We evaluate three distilled reasoning targets against a fixed attacker across five oversight conditions, collecting 6750 turn-level observations on the Information-Hazard scenario. Our analysis reveals two reproducible vulnerabilities: an oversight paradox where explicit monitoring cues paradoxically increase alignment-faking rates rather than suppress them, and a context-injection failure where models lock onto unsafe external outputs despite safe internal states. We release the full dataset of multi-turn dialogues and CoT traces to support follow-up trace-diagnostic research.
Robust Safety Monitoring of Language Models via Activation Watermarking
Mar 24, 2026Large language models (LLMs) can be misused to reveal sensitive information, such as weapon-making instructions or writing malware. LLM providers rely on $\emph{monitoring}$ to detect and flag unsafe behavior during inference. An open security challenge is $\emph{adaptive}$ adversaries who craft attacks that simultaneously (i) evade detection while (ii) eliciting unsafe behavior. Adaptive attackers are a major concern as LLM providers cannot patch their security mechanisms, since they are unaware of how their models are being misused. We cast $\emph{robust}$ LLM monitoring as a security game, where adversaries who know about the monitor try to extract sensitive information, while a provider must accurately detect these adversarial queries at low false positive rates. Our work (i) shows that existing LLM monitors are vulnerable to adaptive attackers and (ii) designs improved defenses through $\emph{activation watermarking}$ by carefully introducing uncertainty for the attacker during inference. We find that $\emph{activation watermarking}$ outperforms guard baselines by up to $52\%$ under adaptive attackers who know the monitoring algorithm but not the secret key.
Robust and Calibrated Detection of Authentic Multimedia Content
Dec 17, 2025



Generative models can synthesize highly realistic content, so-called deepfakes, that are already being misused at scale to undermine digital media authenticity. Current deepfake detection methods are unreliable for two reasons: (i) distinguishing inauthentic content post-hoc is often impossible (e.g., with memorized samples), leading to an unbounded false positive rate (FPR); and (ii) detection lacks robustness, as adversaries can adapt to known detectors with near-perfect accuracy using minimal computational resources. To address these limitations, we propose a resynthesis framework to determine if a sample is authentic or if its authenticity can be plausibly denied. We make two key contributions focusing on the high-precision, low-recall setting against efficient (i.e., compute-restricted) adversaries. First, we demonstrate that our calibrated resynthesis method is the most reliable approach for verifying authentic samples while maintaining controllable, low FPRs. Second, we show that our method achieves adversarial robustness against efficient adversaries, whereas prior methods are easily evaded under identical compute budgets. Our approach supports multiple modalities and leverages state-of-the-art inversion techniques.
Mitigating Watermark Stealing Attacks in Generative Models via Multi-Key Watermarking
Jul 10, 2025Watermarking offers a promising solution for GenAI providers to establish the provenance of their generated content. A watermark is a hidden signal embedded in the generated content, whose presence can later be verified using a secret watermarking key. A threat to GenAI providers are \emph{watermark stealing} attacks, where users forge a watermark into content that was \emph{not} generated by the provider's models without access to the secret key, e.g., to falsely accuse the provider. Stealing attacks collect \emph{harmless} watermarked samples from the provider's model and aim to maximize the expected success rate of generating \emph{harmful} watermarked samples. Our work focuses on mitigating stealing attacks while treating the underlying watermark as a black-box. Our contributions are: (i) Proposing a multi-key extension to mitigate stealing attacks that can be applied post-hoc to any watermarking method across any modality. (ii) We provide theoretical guarantees and demonstrate empirically that our method makes forging substantially less effective across multiple datasets, and (iii) we formally define the threat of watermark forging as the task of generating harmful, watermarked content and model this threat via security games.
Improving LLM First-Token Predictions in Multiple-Choice Question Answering via Prefilling Attack
May 21, 2025Large Language Models (LLMs) are increasingly evaluated on multiple-choice question answering (MCQA) tasks using *first-token probability* (FTP), which selects the answer option whose initial token has the highest likelihood. While efficient, FTP can be fragile: models may assign high probability to unrelated tokens (*misalignment*) or use a valid token merely as part of a generic preamble rather than as a clear answer choice (*misinterpretation*), undermining the reliability of symbolic evaluation. We propose a simple solution: the *prefilling attack*, a structured natural-language prefix (e.g., "*The correct option is:*") prepended to the model output. Originally explored in AI safety, we repurpose prefilling to steer the model to respond with a clean, valid option, without modifying its parameters. Empirically, the FTP with prefilling strategy substantially improves accuracy, calibration, and output consistency across a broad set of LLMs and MCQA benchmarks. It outperforms standard FTP and often matches the performance of open-ended generation approaches that require full decoding and external classifiers, while being significantly more efficient. Our findings suggest that prefilling is a simple, robust, and low-cost method to enhance the reliability of FTP-based evaluation in multiple-choice settings.
Towards Understanding the Fragility of Multilingual LLMs against Fine-Tuning Attacks
Oct 23, 2024Recent advancements in Large Language Models (LLMs) have sparked widespread concerns about their safety. Recent work demonstrates that safety alignment of LLMs can be easily removed by fine-tuning with a few adversarially chosen instruction-following examples, i.e., fine-tuning attacks. We take a further step to understand fine-tuning attacks in multilingual LLMs. We first discover cross-lingual generalization of fine-tuning attacks: using a few adversarially chosen instruction-following examples in one language, multilingual LLMs can also be easily compromised (e.g., multilingual LLMs fail to refuse harmful prompts in other languages). Motivated by this finding, we hypothesize that safety-related information is language-agnostic and propose a new method termed Safety Information Localization (SIL) to identify the safety-related information in the model parameter space. Through SIL, we validate this hypothesis and find that only changing 20% of weight parameters in fine-tuning attacks can break safety alignment across all languages. Furthermore, we provide evidence to the alternative pathways hypothesis for why freezing safety-related parameters does not prevent fine-tuning attacks, and we demonstrate that our attack vector can still jailbreak LLMs adapted to new languages.
Removing NSFW Concepts from Vision-and-Language Models for Text-to-Image Retrieval and Generation
Nov 27, 2023Vision-and-Language models such as CLIP have demonstrated remarkable effectiveness across a wide range of tasks. However, these models are typically trained on web-scale data, which can introduce inappropriate content and lead to the development of unsafe and biased behavior. This, in turn, hampers their applicability in sensitive and trustworthy contexts and could raise significant concern in their adoption. To overcome these limitations, we introduce a methodology to make Vision-and-Language models safer by removing their sensitivity to not-safe-for-work concepts. We show how this can be done by distilling from a large language model which converts between safe and unsafe sentences and which is fine-tuned starting from just 100 manually-curated pairs. We conduct extensive experiments on the resulting embedding space for both retrieval and text-to-image generation, where we show that our model can also be properly employed with pre-trained image generators. Our source code and trained models are available at: https://github.com/aimagelab/safe-clip.
Multi-Class Explainable Unlearning for Image Classification via Weight Filtering
Apr 04, 2023Machine Unlearning has recently been emerging as a paradigm for selectively removing the impact of training datapoints from a network. While existing approaches have focused on unlearning either a small subset of the training data or a single class, in this paper we take a different path and devise a framework that can unlearn all classes of an image classification network in a single untraining round. Our proposed technique learns to modulate the inner components of an image classification network through memory matrices so that, after training, the same network can selectively exhibit an unlearning behavior over any of the classes. By discovering weights which are specific to each of the classes, our approach also recovers a representation of the classes which is explainable by-design. We test the proposed framework, which we name Weight Filtering network (WF-Net), on small-scale and medium-scale image classification datasets, with both CNN and Transformer-based backbones. Our work provides interesting insights in the development of explainable solutions for unlearning and could be easily extended to other vision tasks.
Revisiting The Evaluation of Class Activation Mapping for Explainability: A Novel Metric and Experimental Analysis
Apr 20, 2021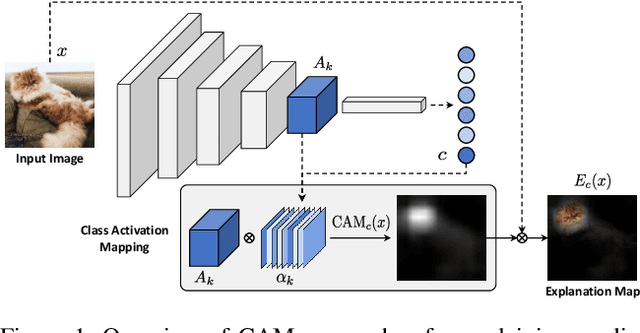
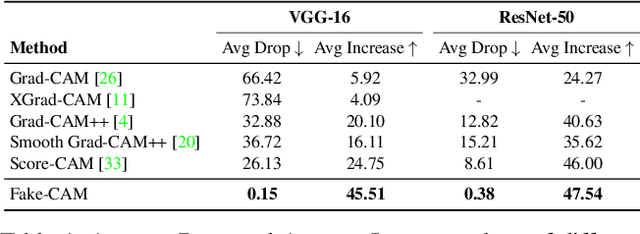
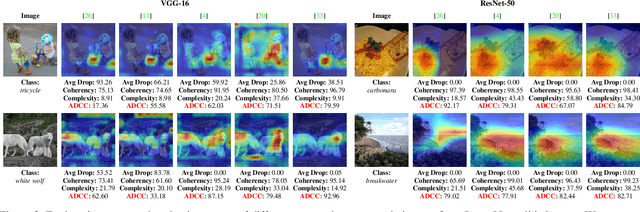
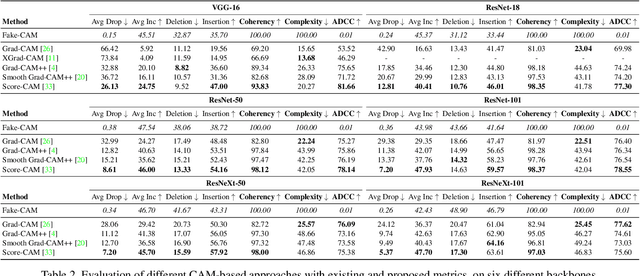
As the request for deep learning solutions increases, the need for explainability is even more fundamental. In this setting, particular attention has been given to visualization techniques, that try to attribute the right relevance to each input pixel with respect to the output of the network. In this paper, we focus on Class Activation Mapping (CAM) approaches, which provide an effective visualization by taking weighted averages of the activation maps. To enhance the evaluation and the reproducibility of such approaches, we propose a novel set of metrics to quantify explanation maps, which show better effectiveness and simplify comparisons between approaches. To evaluate the appropriateness of the proposal, we compare different CAM-based visualization methods on the entire ImageNet validation set, fostering proper comparisons and reproducibility.