 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntermediate-Task Transfer Learning with Pretrained Models for Natural Language Understanding: When and Why Does It Work?
May 09, 2020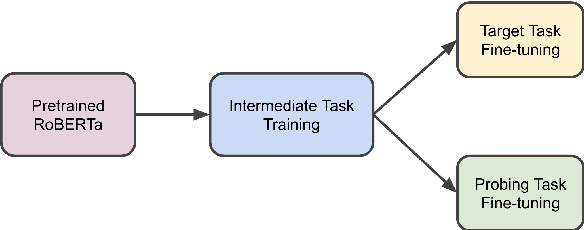
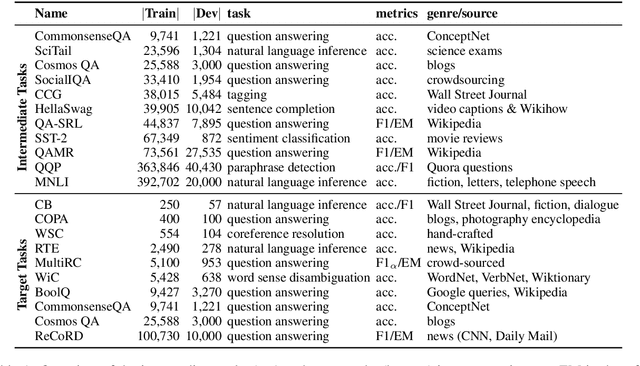
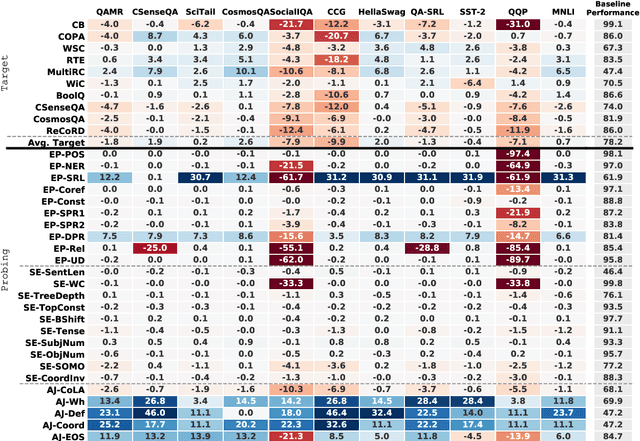
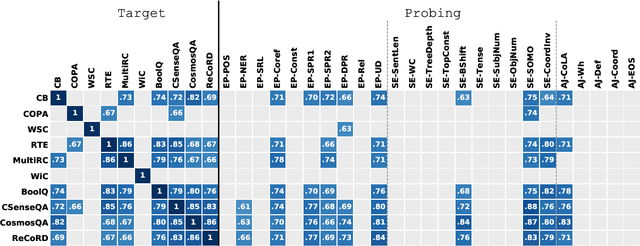
While pretrained models such as BERT have shown large gains across natural language understanding tasks, their performance can be improved by further training the model on a data-rich intermediate task, before fine-tuning it on a target task. However, it is still poorly understood when and why intermediate-task training is beneficial for a given target task. To investigate this, we perform a large-scale study on the pretrained RoBERTa model with 110 intermediate-target task combinations. We further evaluate all trained models with 25 probing tasks meant to reveal the specific skills that drive transfer. We observe that intermediate tasks requiring high-level inference and reasoning abilities tend to work best. We also observe that target task performance is strongly correlated with higher-level abilities such as coreference resolution. However, we fail to observe more granular correlations between probing and target task performance, highlighting the need for further work on broad-coverage probing benchmarks. We also observe evidence that the forgetting of knowledge learned during pretraining may limit our analysis, highlighting the need for further work on transfer learning methods in these settings.
Learning to Learn Morphological Inflection for Resource-Poor Languages
Apr 28, 2020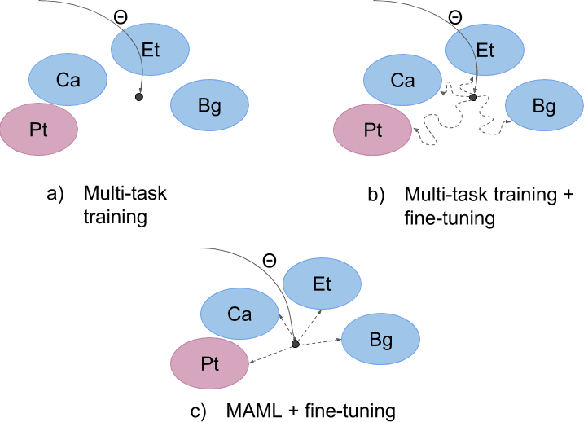
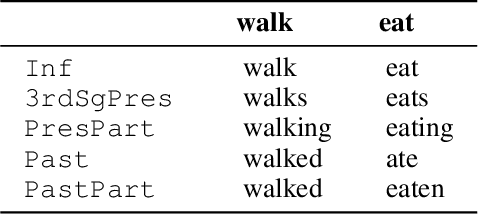
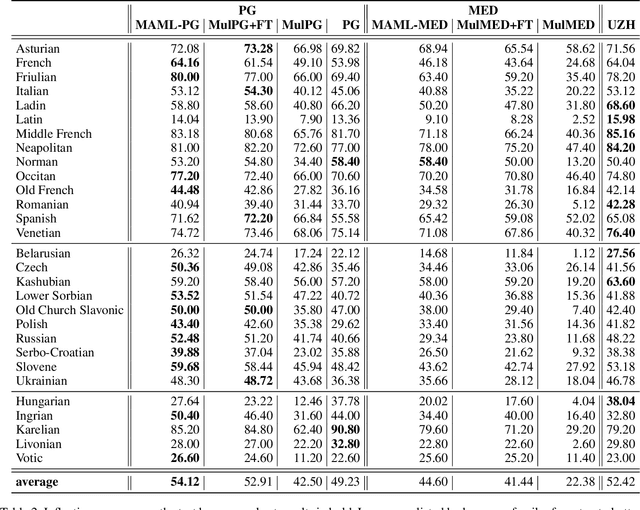
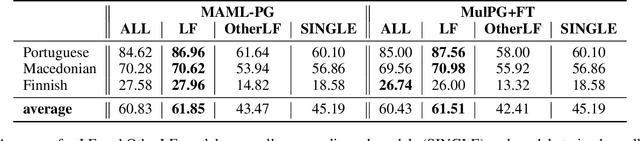
We propose to cast the task of morphological inflection - mapping a lemma to an indicated inflected form - for resource-poor languages as a meta-learning problem. Treating each language as a separate task, we use data from high-resource source languages to learn a set of model parameters that can serve as a strong initialization point for fine-tuning on a resource-poor target language. Experiments with two model architectures on 29 target languages from 3 families show that our suggested approach outperforms all baselines. In particular, it obtains a 31.7% higher absolute accuracy than a previously proposed cross-lingual transfer model and outperforms the previous state of the art by 1.7% absolute accuracy on average over languages.
Collecting Entailment Data for Pretraining: New Protocols and Negative Results
Apr 24, 2020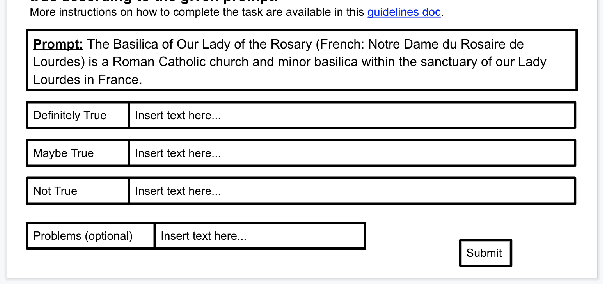

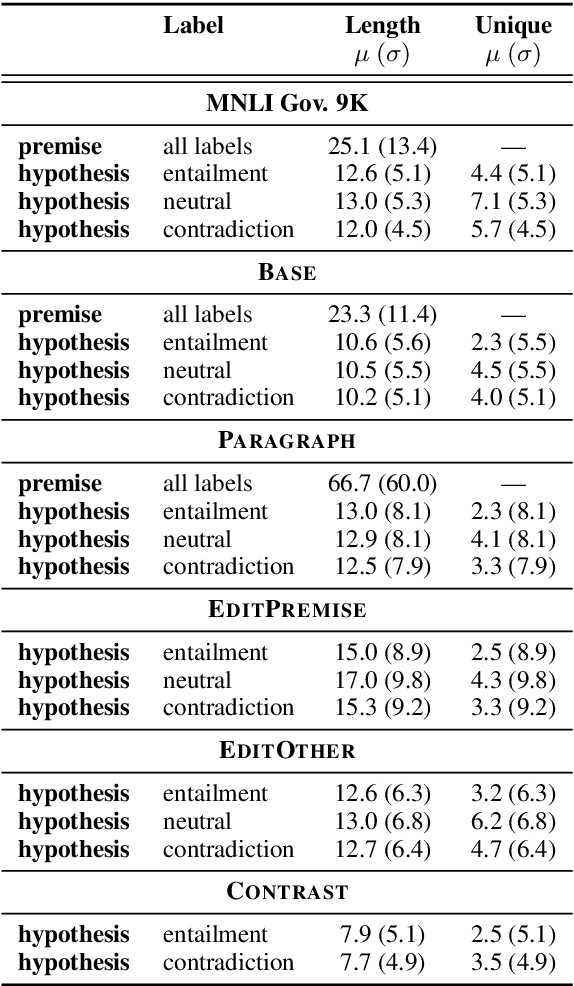
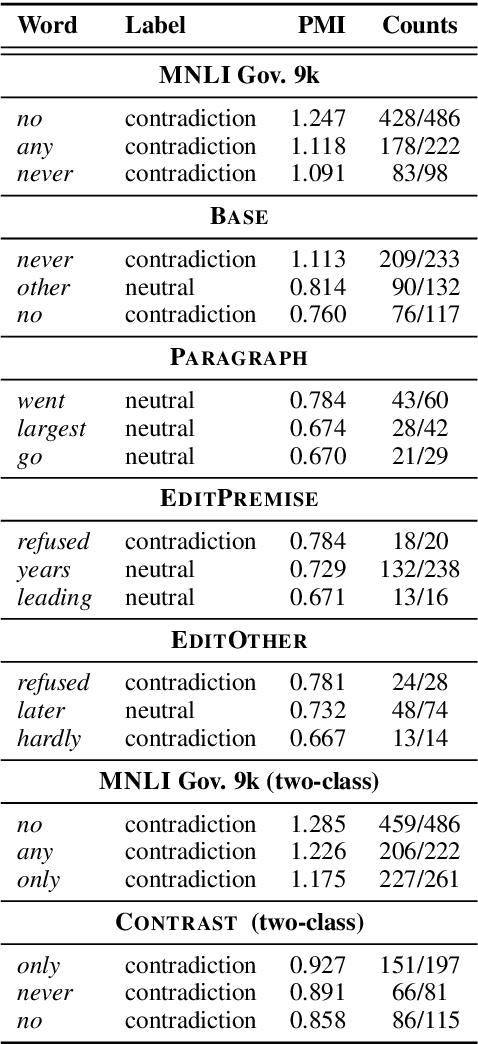
Textual entailment (or NLI) data has proven useful as pretraining data for tasks requiring language understanding, even when building on an already-pretrained model like RoBERTa. The standard protocol for collecting NLI was not designed for the creation of pretraining data, and it is likely far from ideal for this purpose. With this application in mind, we propose four alternative protocols, each aimed at improving either the ease with which annotators can produce sound training examples or the quality and diversity of those examples. Using these alternatives and a simple MNLI-based baseline, we collect and compare five new 8.5k-example training sets. Our primary results are solidly negative, with our baseline MNLI-style dataset yielding good transfer performance, but none of our four new methods (nor the recent ANLI) showing any improvements on that baseline. However, we do observe that all four of these interventions, especially the use of seed sentences for inspiration, reduce previously observed issues with annotation artifacts.
jiant: A Software Toolkit for Research on General-Purpose Text Understanding Models
Mar 04, 2020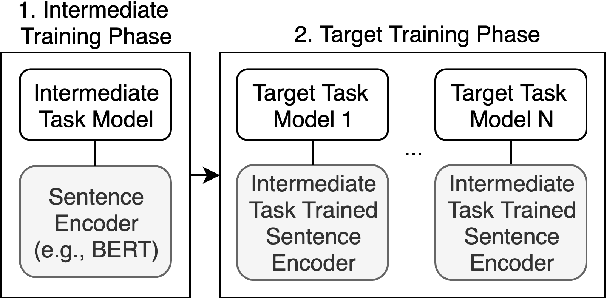
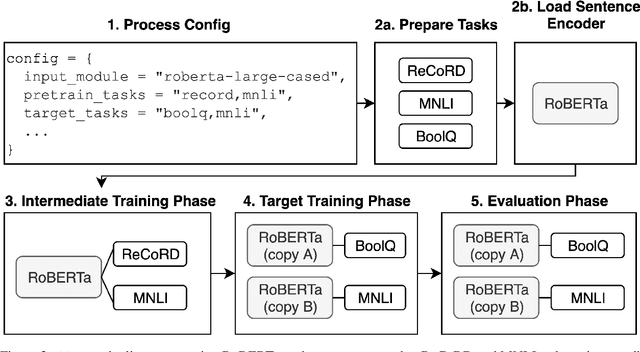

We introduce jiant, an open source toolkit for conducting multitask and transfer learning experiments on English NLU tasks. jiant enables modular and configuration-driven experimentation with state-of-the-art models and implements a broad set of tasks for probing, transfer learning, and multitask training experiments. jiant implements over 50 NLU tasks, including all GLUE and SuperGLUE benchmark tasks. We demonstrate that jiant reproduces published performance on a variety of tasks and models, including BERT and RoBERTa. jiant is available at https://jiant.info.
BLiMP: A Benchmark of Linguistic Minimal Pairs for English
Dec 02, 2019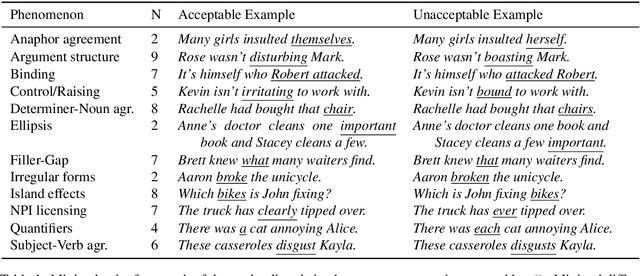
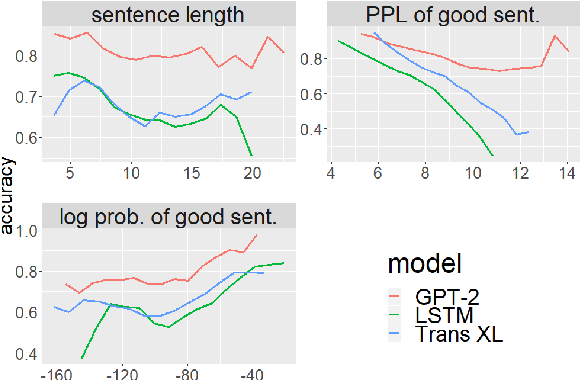

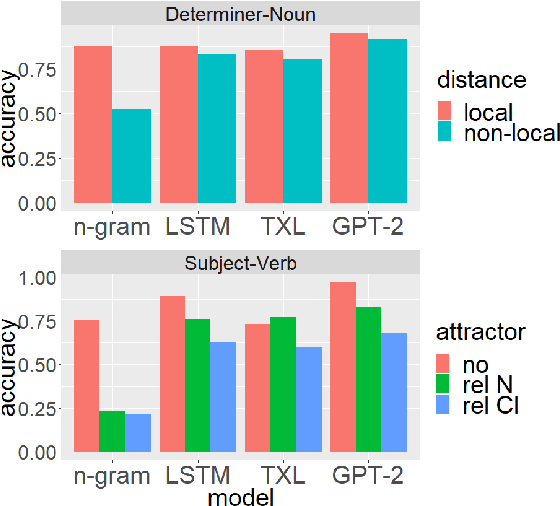
We introduce The Benchmark of Linguistic Minimal Pairs (shortened to BLiMP), a challenge set for evaluating what language models (LMs) know about major grammatical phenomena in English. BLiMP consists of 67 sub-datasets, each containing 1000 minimal pairs isolating specific contrasts in syntax, morphology, or semantics. The data is automatically generated according to expert-crafted grammars, and aggregate human agreement with the labels is 96.4%. We use it to evaluate n-gram, LSTM, and Transformer (GPT-2 and Transformer-XL) LMs. We find that state-of-the-art models identify morphological contrasts reliably, but they struggle with semantic restrictions on the distribution of quantifiers and negative polarity items and subtle syntactic phenomena such as extraction islands.
Do Attention Heads in BERT Track Syntactic Dependencies?
Nov 27, 2019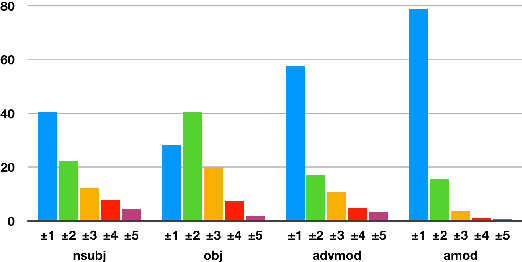

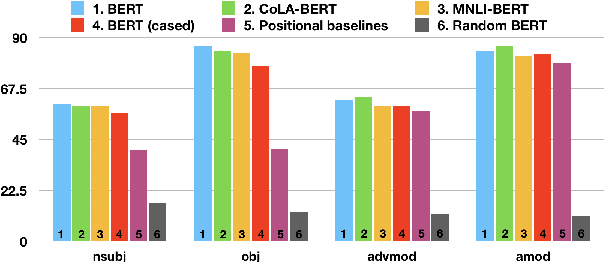
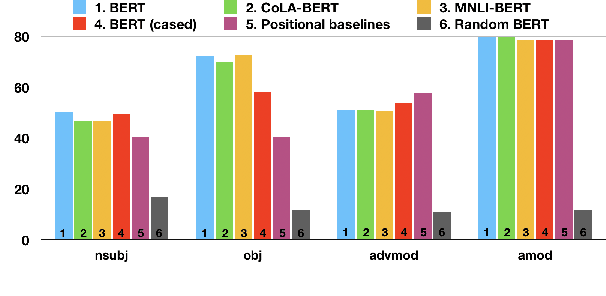
We investigate the extent to which individual attention heads in pretrained transformer language models, such as BERT and RoBERTa, implicitly capture syntactic dependency relations. We employ two methods---taking the maximum attention weight and computing the maximum spanning tree---to extract implicit dependency relations from the attention weights of each layer/head, and compare them to the ground-truth Universal Dependency (UD) trees. We show that, for some UD relation types, there exist heads that can recover the dependency type significantly better than baselines on parsed English text, suggesting that some self-attention heads act as a proxy for syntactic structure. We also analyze BERT fine-tuned on two datasets---the syntax-oriented CoLA and the semantics-oriented MNLI---to investigate whether fine-tuning affects the patterns of their self-attention, but we do not observe substantial differences in the overall dependency relations extracted using our methods. Our results suggest that these models have some specialist attention heads that track individual dependency types, but no generalist head that performs holistic parsing significantly better than a trivial baseline, and that analyzing attention weights directly may not reveal much of the syntactic knowledge that BERT-style models are known to learn.
Inducing Constituency Trees through Neural Machine Translation
Sep 22, 2019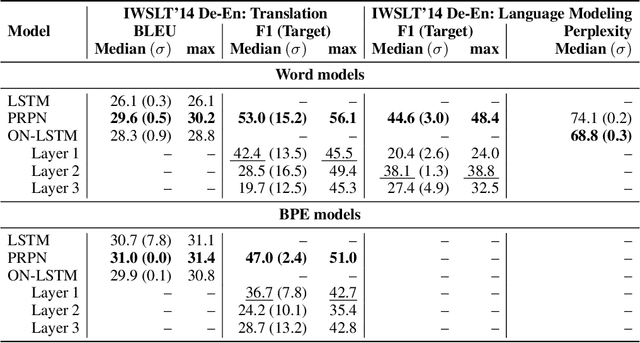
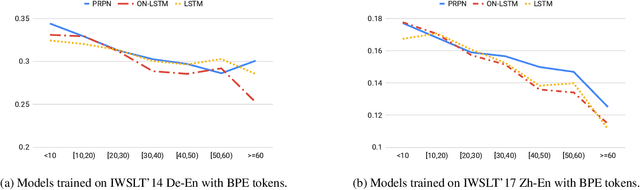
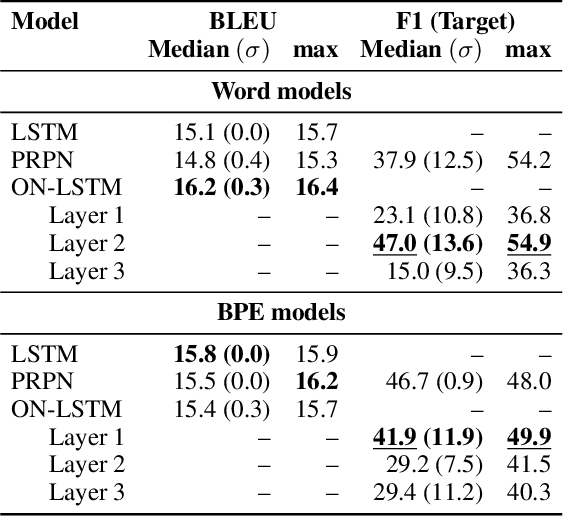

Latent tree learning(LTL) methods learn to parse sentences using only indirect supervision from a downstream task. Recent advances in latent tree learning have made it possible to recover moderately high quality tree structures by training with language modeling or auto-encoding objectives. In this work, we explore the hypothesis that decoding in machine translation, as a conditional language modeling task, will produce better tree structures since it offers a similar training signal as language modeling, but with more semantic signal. We adapt two existing latent-tree language models--PRPN andON-LSTM--for use in translation. We find that they indeed recover trees that are better in F1 score than those seen in language modeling on WSJ test set, while maintaining strong translation quality. We observe that translation is a better objective than language modeling for inducing trees, marking the first success at latent tree learning using a machine translation objective. Additionally, our findings suggest that, although translation provides better signal for inducing trees than language modeling, translation models can perform well without exploiting the latent tree structure.
Investigating BERT's Knowledge of Language: Five Analysis Methods with NPIs
Sep 19, 2019
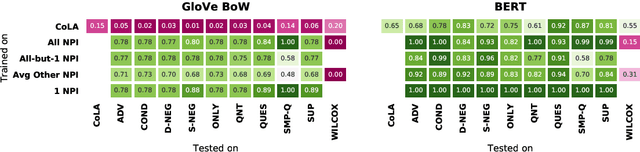

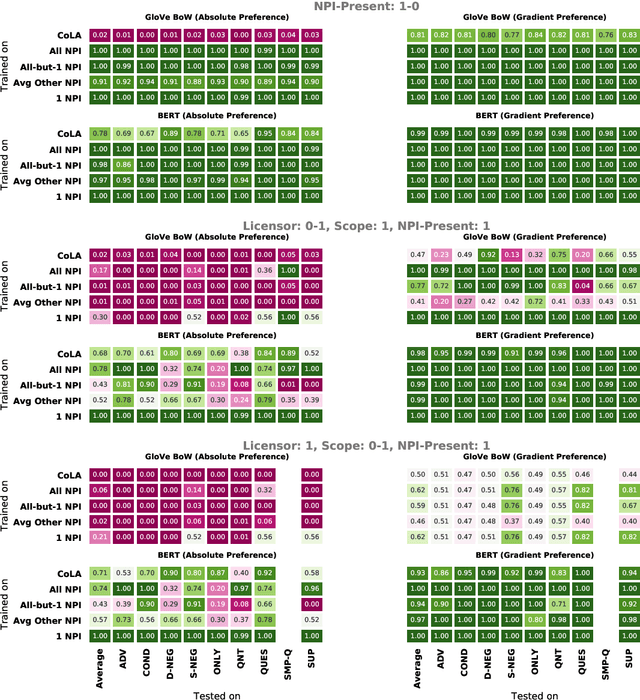
Though state-of-the-art sentence representation models can perform tasks requiring significant knowledge of grammar, it is an open question how best to evaluate their grammatical knowledge. We explore five experimental methods inspired by prior work evaluating pretrained sentence representation models. We use a single linguistic phenomenon, negative polarity item (NPI) licensing in English, as a case study for our experiments. NPIs like "any" are grammatical only if they appear in a licensing environment like negation ("Sue doesn't have any cats" vs. "Sue has any cats"). This phenomenon is challenging because of the variety of NPI licensing environments that exist. We introduce an artificially generated dataset that manipulates key features of NPI licensing for the experiments. We find that BERT has significant knowledge of these features, but its success varies widely across different experimental methods. We conclude that a variety of methods is necessary to reveal all relevant aspects of a model's grammatical knowledge in a given domain.
Towards Realistic Practices In Low-Resource Natural Language Processing: The Development Set
Sep 15, 2019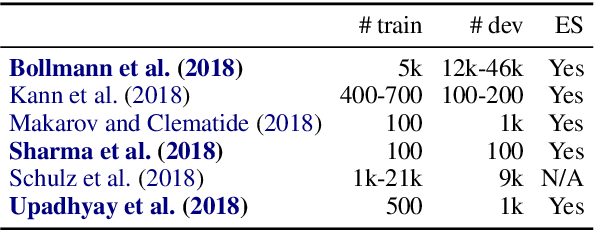
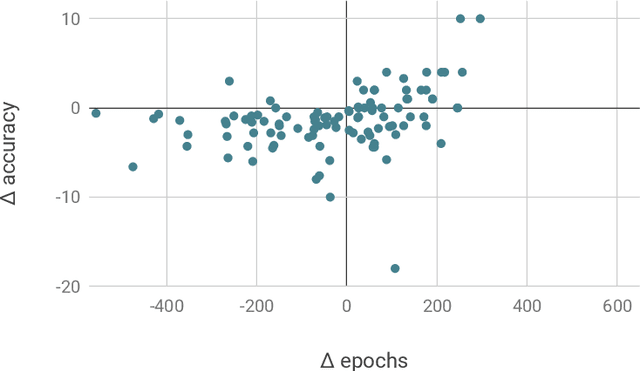
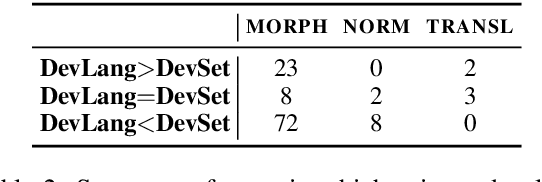
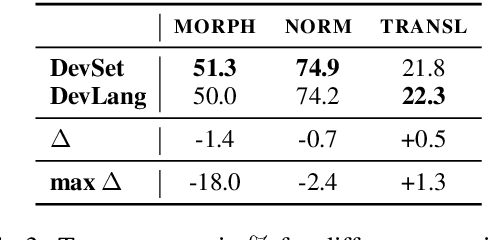
Development sets are impractical to obtain for real low-resource languages, since using all available data for training is often more effective. However, development sets are widely used in research papers that purport to deal with low-resource natural language processing (NLP). Here, we aim to answer the following questions: Does using a development set for early stopping in the low-resource setting influence results as compared to a more realistic alternative, where the number of training epochs is tuned on development languages? And does it lead to overestimation or underestimation of performance? We repeat multiple experiments from recent work on neural models for low-resource NLP and compare results for models obtained by training with and without development sets. On average over languages, absolute accuracy differs by up to 1.4%. However, for some languages and tasks, differences are as big as 18.0% accuracy. Our results highlight the importance of realistic experimental setups in the publication of low-resource NLP research results.
Human vs. Muppet: A Conservative Estimate of Human Performance on the GLUE Benchmark
Jun 01, 2019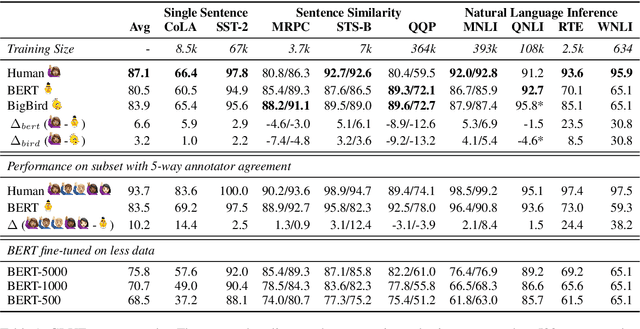


The GLUE benchmark (Wang et al., 2019b) is a suite of language understanding tasks which has seen dramatic progress in the past year, with average performance moving from 70.0 at launch to 83.9, state of the art at the time of writing (May 24, 2019). Here, we measure human performance on the benchmark, in order to learn whether significant headroom remains for further progress. We provide a conservative estimate of human performance on the benchmark through crowdsourcing: Our annotators are non-experts who must learn each task from a brief set of instructions and 20 examples. In spite of limited training, these annotators robustly outperform the state of the art on six of the nine GLUE tasks and achieve an average score of 87.1. Given the fast pace of progress however, the headroom we observe is quite limited. To reproduce the data-poor setting that our annotators must learn in, we also train the BERT model (Devlin et al., 2019) in limited-data regimes, and conclude that low-resource sentence classification remains a challenge for modern neural network approaches to text understanding.