 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrained Multilingual Transformers Reveal Quantitative Distance Between Human Languages
Mar 18, 2026Understanding the distance between human languages is central to linguistics, anthropology, and tracing human evolutionary history. Yet, while linguistics has long provided rich qualitative accounts of cross-linguistic variation, a unified and scalable quantitative approach to measuring language distance remains lacking. In this paper, we introduce a method that leverages pretrained multilingual language models as systematic instruments for linguistic measurement. Specifically, we show that the spontaneously emerged attention mechanisms of these models provide a robust, tokenization-agnostic measure of cross-linguistic distance, termed Attention Transport Distance (ATD). By treating attention matrices as probability distributions and measuring their geometric divergence via optimal transport, we quantify the representational distance between languages during translation. Applying ATD to a large and diverse set of languages, we demonstrate that the resulting distances recover established linguistic groupings with high fidelity and reveal patterns aligned with geographic and contact-induced relationships. Furthermore, incorporating ATD as a regularizer improves transfer performance in low-resource machine translation. Our results establish a principled foundation for testing linguistic hypotheses using artificial neural networks. This framework transforms multilingual models into powerful tools for quantitative linguistic discovery, facilitating more equitable multilingual AI.
MSTS: A Multimodal Safety Test Suite for Vision-Language Models
Jan 17, 2025Vision-language models (VLMs), which process image and text inputs, are increasingly integrated into chat assistants and other consumer AI applications. Without proper safeguards, however, VLMs may give harmful advice (e.g. how to self-harm) or encourage unsafe behaviours (e.g. to consume drugs). Despite these clear hazards, little work so far has evaluated VLM safety and the novel risks created by multimodal inputs. To address this gap, we introduce MSTS, a Multimodal Safety Test Suite for VLMs. MSTS comprises 400 test prompts across 40 fine-grained hazard categories. Each test prompt consists of a text and an image that only in combination reveal their full unsafe meaning. With MSTS, we find clear safety issues in several open VLMs. We also find some VLMs to be safe by accident, meaning that they are safe because they fail to understand even simple test prompts. We translate MSTS into ten languages, showing non-English prompts to increase the rate of unsafe model responses. We also show models to be safer when tested with text only rather than multimodal prompts. Finally, we explore the automation of VLM safety assessments, finding even the best safety classifiers to be lacking.
Investigating BERT's Knowledge of Language: Five Analysis Methods with NPIs
Sep 19, 2019
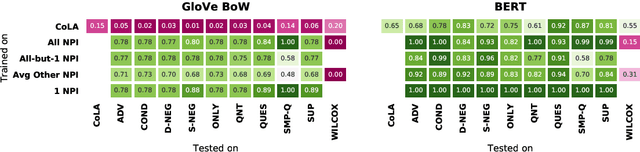

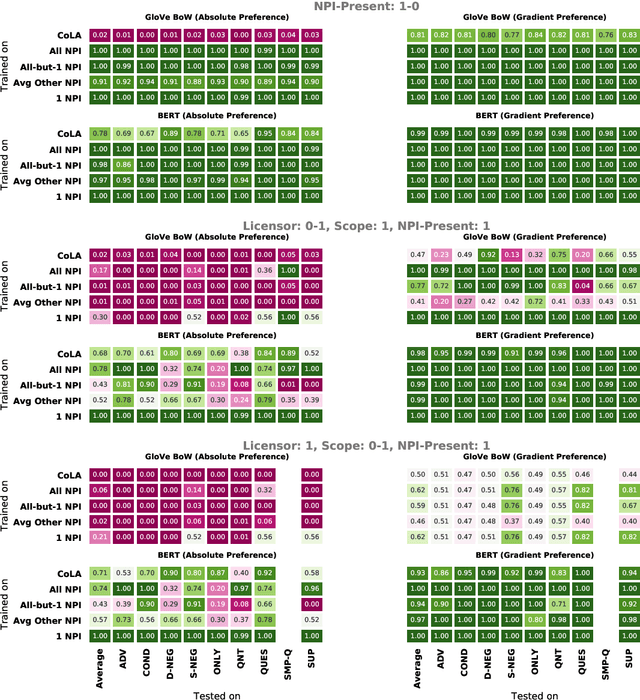
Though state-of-the-art sentence representation models can perform tasks requiring significant knowledge of grammar, it is an open question how best to evaluate their grammatical knowledge. We explore five experimental methods inspired by prior work evaluating pretrained sentence representation models. We use a single linguistic phenomenon, negative polarity item (NPI) licensing in English, as a case study for our experiments. NPIs like "any" are grammatical only if they appear in a licensing environment like negation ("Sue doesn't have any cats" vs. "Sue has any cats"). This phenomenon is challenging because of the variety of NPI licensing environments that exist. We introduce an artificially generated dataset that manipulates key features of NPI licensing for the experiments. We find that BERT has significant knowledge of these features, but its success varies widely across different experimental methods. We conclude that a variety of methods is necessary to reveal all relevant aspects of a model's grammatical knowledge in a given domain.